 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1+1>2: A Synergistic Sparse and Low-Rank Compression Method for Large Language Models
Oct 30, 2025


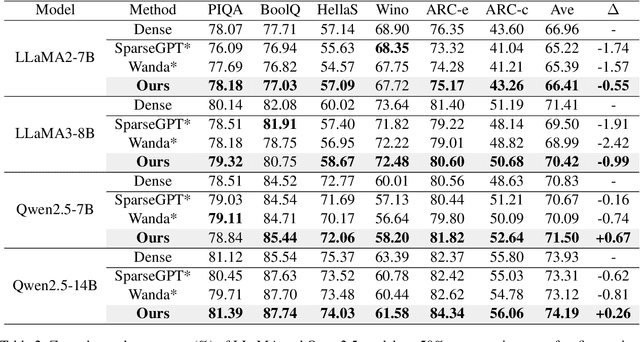
Large Language Models (LLMs) have demonstrated remarkable proficiency in language comprehension and generation; however, their widespread adoption is constrained by substantial bandwidth and computational demands. While pruning and low-rank approximation have each demonstrated promising performance individually, their synergy for LLMs remains underexplored. We introduce \underline{S}ynergistic \underline{S}parse and \underline{L}ow-Rank \underline{C}ompression (SSLC) methods for LLMs, which leverages the strengths of both techniques: low-rank approximation compresses the model by retaining its essential structure with minimal information loss, whereas sparse optimization eliminates non-essential weights, preserving those crucial for generalization. Based on theoretical analysis, we first formulate the low-rank approximation and sparse optimization as a unified problem and solve it by iterative optimization algorithm. Experiments on LLaMA and Qwen2.5 models (7B-70B) show that SSLC, without any additional training steps, consistently surpasses standalone methods, achieving state-of-the-arts results. Notably, SSLC compresses Qwen2.5 by 50\% with no performance drop and achieves at least 1.63$\times$ speedup, offering a practical solution for efficient LLM deployment.
Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection
Aug 28, 2023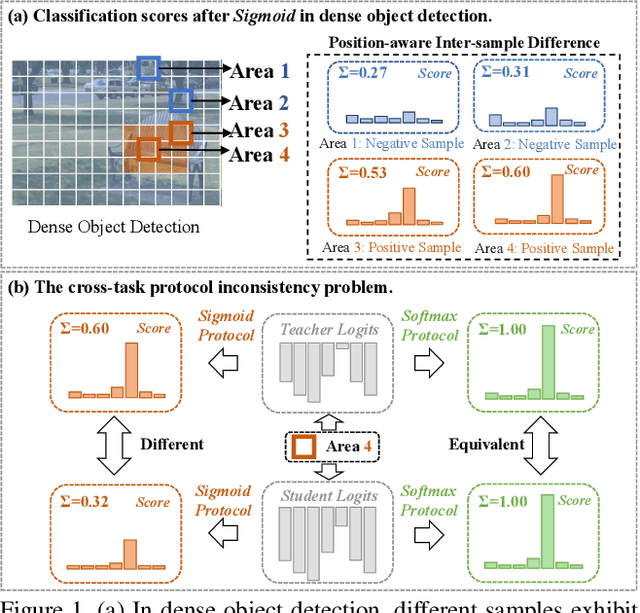
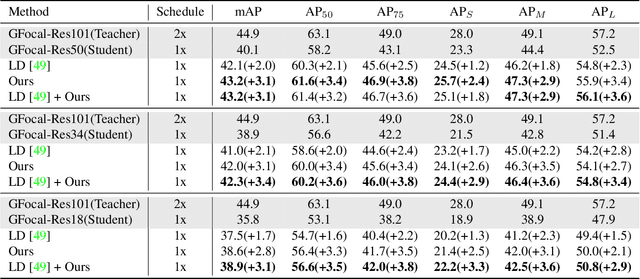
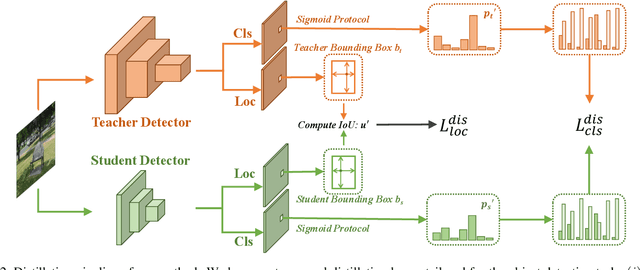
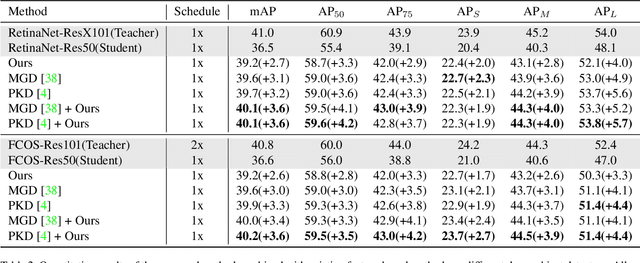
Knowledge distillation (KD) has shown potential for learning compact models in dense object detection. However, the commonly used softmax-based distillation ignores the absolute classification scores for individual categories. Thus, the optimum of the distillation loss does not necessarily lead to the optimal student classification scores for dense object detectors. This cross-task protocol inconsistency is critical, especially for dense object detectors, since the foreground categories are extremely imbalanced. To address the issue of protocol differences between distillation and classification, we propose a novel distillation method with cross-task consistent protocols, tailored for the dense object detection. For classification distillation, we address the cross-task protocol inconsistency problem by formulating the classification logit maps in both teacher and student models as multiple binary-classification maps and applying a binary-classification distillation loss to each map. For localization distillation, we design an IoU-based Localization Distillation Loss that is free from specific network structures and can be compared with existing localization distillation losses. Our proposed method is simple but effective, and experimental results demonstrate its superiority over existing methods. Code is available at https://github.com/TinyTigerPan/BCKD.
Language Adaptive Weight Generation for Multi-task Visual Grounding
Jun 06, 2023
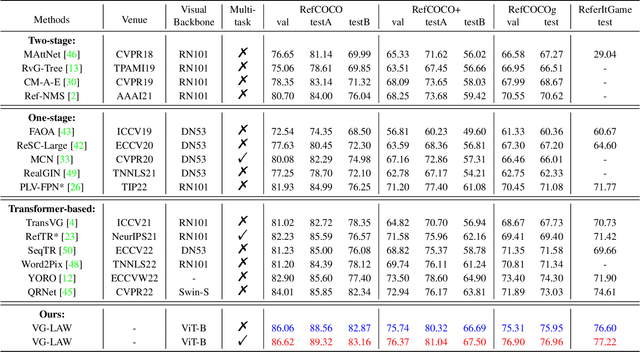
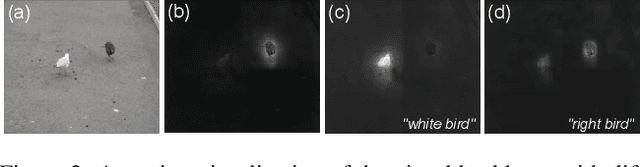
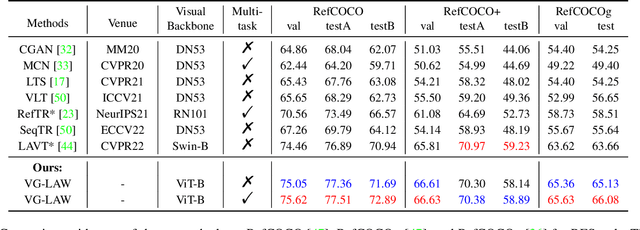
Although the impressive performance in visual grounding, the prevailing approaches usually exploit the visual backbone in a passive way, i.e., the visual backbone extracts features with fixed weights without expression-related hints. The passive perception may lead to mismatches (e.g., redundant and missing), limiting further performance improvement. Ideally, the visual backbone should actively extract visual features since the expressions already provide the blueprint of desired visual features. The active perception can take expressions as priors to extract relevant visual features, which can effectively alleviate the mismatches. Inspired by this, we propose an active perception Visual Grounding framework based on Language Adaptive Weights, called VG-LAW. The visual backbone serves as an expression-specific feature extractor through dynamic weights generated for various expressions. Benefiting from the specific and relevant visual features extracted from the language-aware visual backbone, VG-LAW does not require additional modules for cross-modal interaction. Along with a neat multi-task head, VG-LAW can be competent in referring expression comprehension and segmentation jointly. Extensive experiments on four representative datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, validate the effectiveness of the proposed framework and demonstrate state-of-the-art performance.
Understanding and Unifying Fourteen Attribution Methods with Taylor Interactions
Mar 06, 2023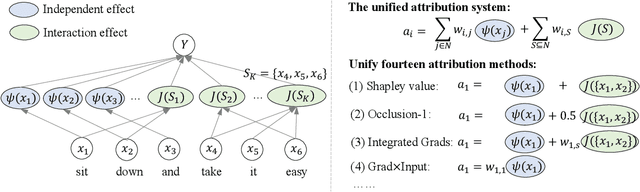
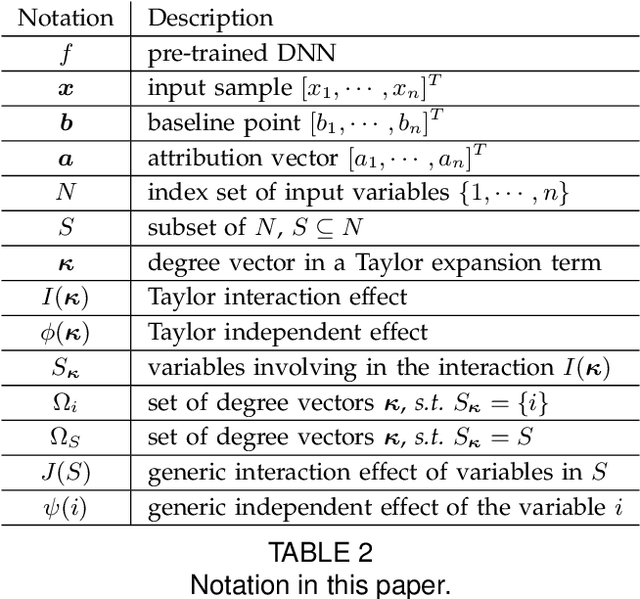
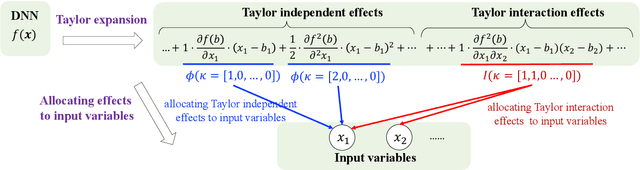

Various attribution methods have been developed to explain deep neural networks (DNNs) by inferring the attribution/importance/contribution score of each input variable to the final output. However, existing attribution methods are often built upon different heuristics. There remains a lack of a unified theoretical understanding of why these methods are effective and how they are related. To this end, for the first time, we formulate core mechanisms of fourteen attribution methods, which were designed on different heuristics, into the same mathematical system, i.e., the system of Taylor interactions. Specifically, we prove that attribution scores estimated by fourteen attribution methods can all be reformulated as the weighted sum of two types of effects, i.e., independent effects of each individual input variable and interaction effects between input variables. The essential difference among the fourteen attribution methods mainly lies in the weights of allocating different effects. Based on the above findings, we propose three principles for a fair allocation of effects to evaluate the faithfulness of the fourteen attribution methods.
Unified Normalization for Accelerating and Stabilizing Transformers
Aug 02, 2022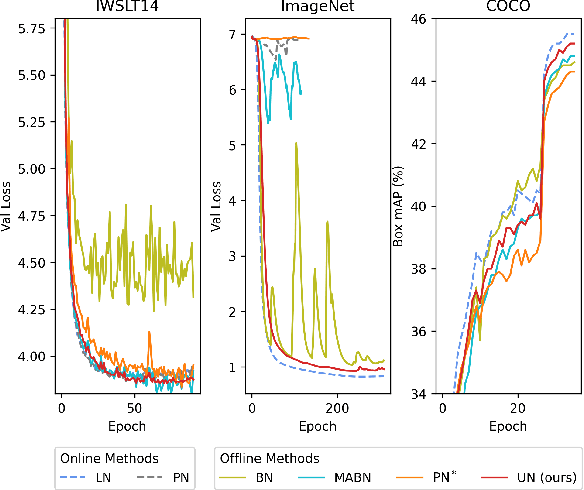
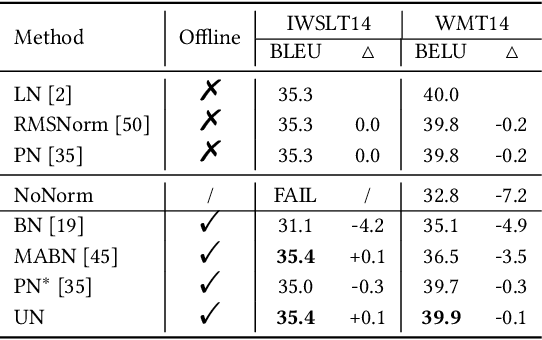
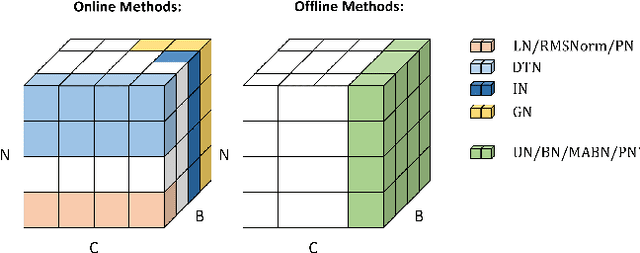
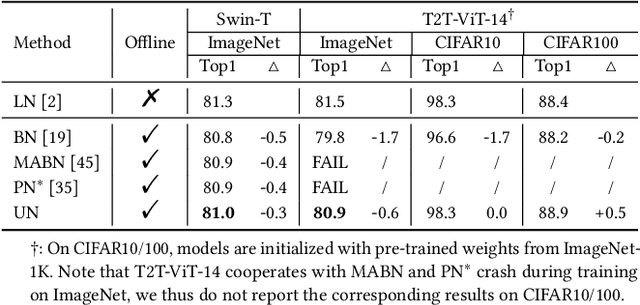
Solid results from Transformers have made them prevailing architectures in various natural language and vision tasks. As a default component in Transformers, Layer Normalization (LN) normalizes activations within each token to boost the robustness. However, LN requires on-the-fly statistics calculation in inference as well as division and square root operations, leading to inefficiency on hardware. What is more, replacing LN with other hardware-efficient normalization schemes (e.g., Batch Normalization) results in inferior performance, even collapse in training. We find that this dilemma is caused by abnormal behaviors of activation statistics, including large fluctuations over iterations and extreme outliers across layers. To tackle these issues, we propose Unified Normalization (UN), which can speed up the inference by being fused with other linear operations and achieve comparable performance on par with LN. UN strives to boost performance by calibrating the activation and gradient statistics with a tailored fluctuation smoothing strategy. Meanwhile, an adaptive outlier filtration strategy is applied to avoid collapse in training whose effectiveness is theoretically proved and experimentally verified in this paper. We demonstrate that UN can be an efficient drop-in alternative to LN by conducting extensive experiments on language and vision tasks. Besides, we evaluate the efficiency of our method on GPU. Transformers equipped with UN enjoy about 31% inference speedup and nearly 18% memory reduction. Code will be released at https://github.com/hikvision-research/Unified-Normalization.
Bidirectional Self-Training with Multiple Anisotropic Prototypes for Domain Adaptive Semantic Segmentation
Apr 16, 2022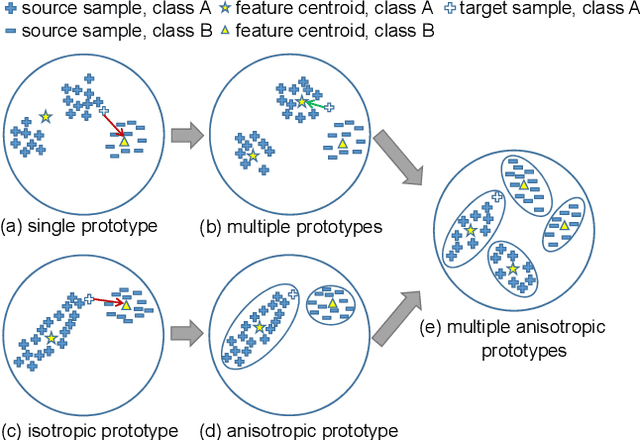
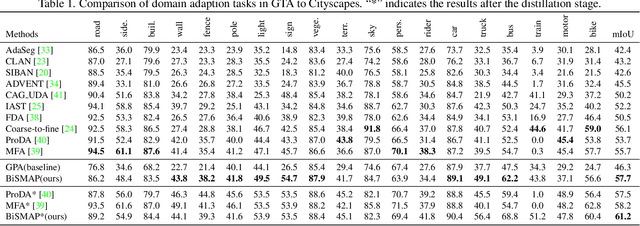
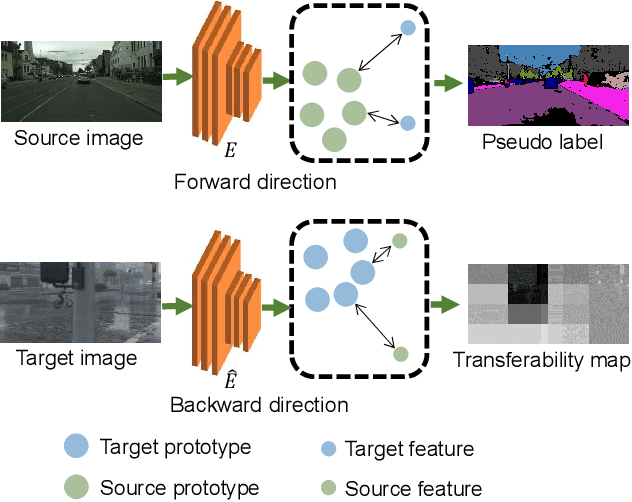

A thriving trend for domain adaptive segmentation endeavors to generate the high-quality pseudo labels for target domain and retrain the segmentor on them. Under this self-training paradigm, some competitive methods have sought to the latent-space information, which establishes the feature centroids (a.k.a prototypes) of the semantic classes and determines the pseudo label candidates by their distances from these centroids. In this paper, we argue that the latent space contains more information to be exploited thus taking one step further to capitalize on it. Firstly, instead of merely using the source-domain prototypes to determine the target pseudo labels as most of the traditional methods do, we bidirectionally produce the target-domain prototypes to degrade those source features which might be too hard or disturbed for the adaptation. Secondly, existing attempts simply model each category as a single and isotropic prototype while ignoring the variance of the feature distribution, which could lead to the confusion of similar categories. To cope with this issue, we propose to represent each category with multiple and anisotropic prototypes via Gaussian Mixture Model, in order to fit the de facto distribution of source domain and estimate the likelihood of target samples based on the probability density. We apply our method on GTA5->Cityscapes and Synthia->Cityscapes tasks and achieve 61.2 and 62.8 respectively in terms of mean IoU, substantially outperforming other competitive self-training methods. Noticeably, in some categories which severely suffer from the categorical confusion such as "truck" and "bus", our method achieves 56.4 and 68.8 respectively, which further demonstrates the effectiveness of our design.
UWC: Unit-wise Calibration Towards Rapid Network Compression
Jan 17, 2022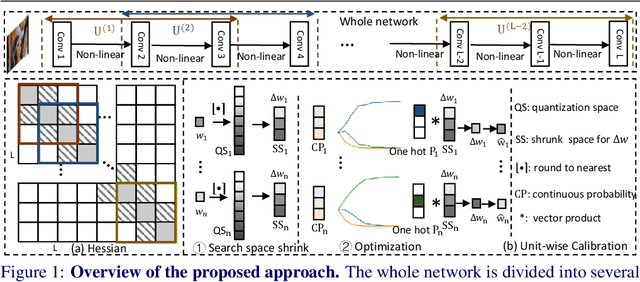
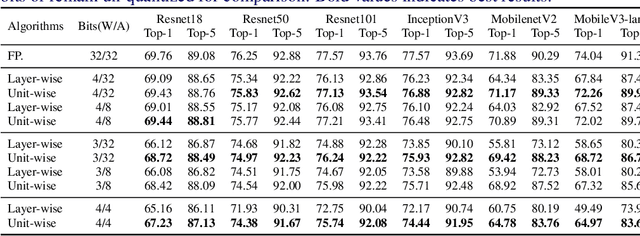
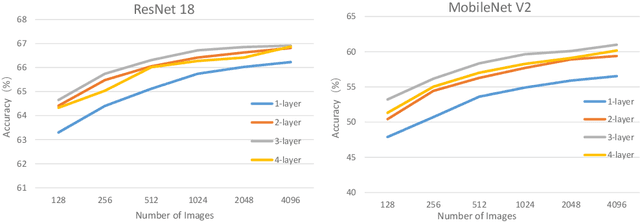
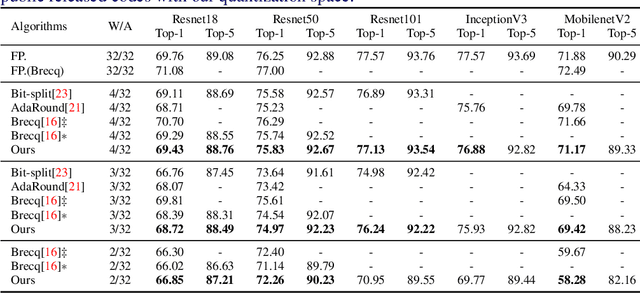
This paper introduces a post-training quantization~(PTQ) method achieving highly efficient Convolutional Neural Network~ (CNN) quantization with high performance. Previous PTQ methods usually reduce compression error via performing layer-by-layer parameters calibration. However, with lower representational ability of extremely compressed parameters (e.g., the bit-width goes less than 4), it is hard to eliminate all the layer-wise errors. This work addresses this issue via proposing a unit-wise feature reconstruction algorithm based on an observation of second order Taylor series expansion of the unit-wise error. It indicates that leveraging the interaction between adjacent layers' parameters could compensate layer-wise errors better. In this paper, we define several adjacent layers as a Basic-Unit, and present a unit-wise post-training algorithm which can minimize quantization error. This method achieves near-original accuracy on ImageNet and COCO when quantizing FP32 models to INT4 and INT3.
Improving Ranking Correlation of Supernet with Candidates Enhancement and Progressive Training
Aug 12, 2021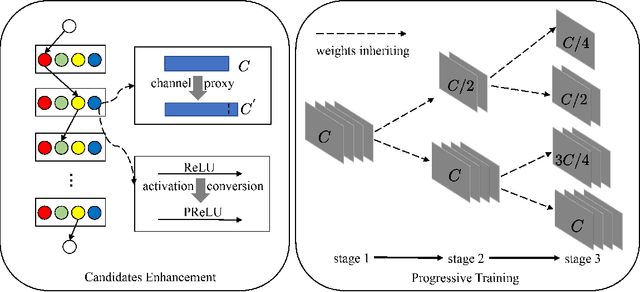
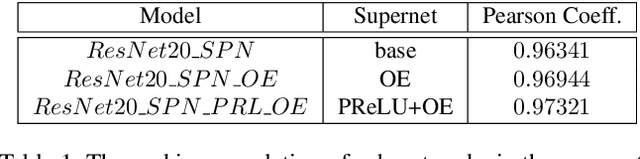
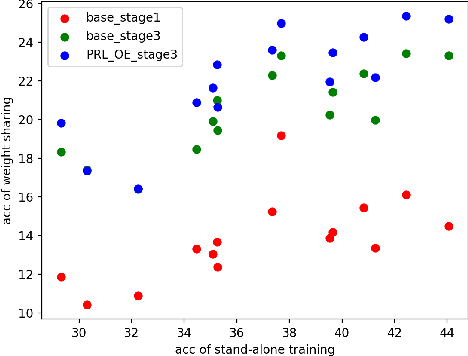
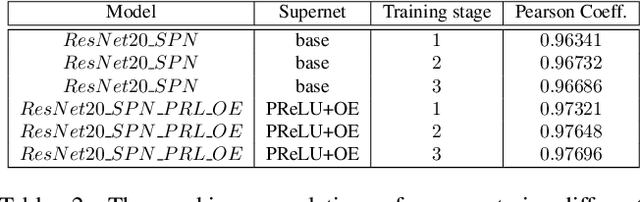
One-shot neural architecture search (NAS) applies weight-sharing supernet to reduce the unaffordable computation overhead of automated architecture designing. However, the weight-sharing technique worsens the ranking consistency of performance due to the interferences between different candidate networks. To address this issue, we propose a candidates enhancement method and progressive training pipeline to improve the ranking correlation of supernet. Specifically, we carefully redesign the sub-networks in the supernet and map the original supernet to a new one of high capacity. In addition, we gradually add narrow branches of supernet to reduce the degree of weight sharing which effectively alleviates the mutual interference between sub-networks. Finally, our method ranks the 1st place in the Supernet Track of CVPR2021 1st Lightweight NAS Challenge.
Cascade Bagging for Accuracy Prediction with Few Training Samples
Aug 12, 2021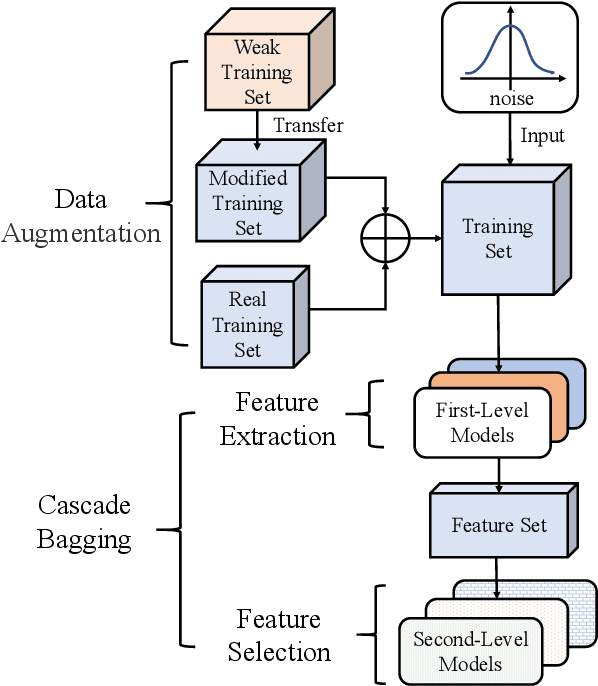
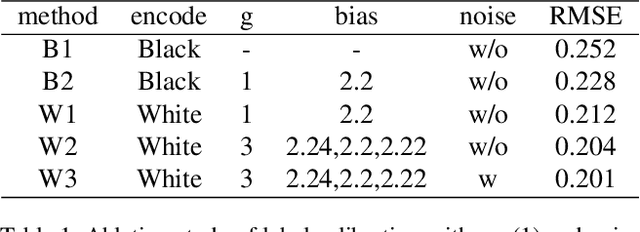
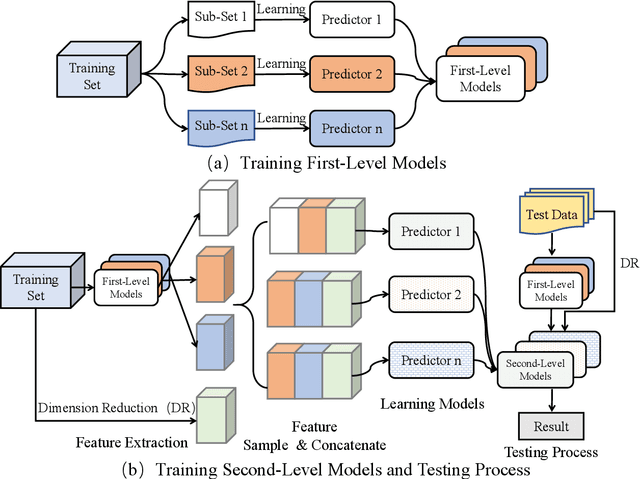

Accuracy predictor is trained to predict the validation accuracy of an network from its architecture encoding. It can effectively assist in designing networks and improving Neural Architecture Search(NAS) efficiency. However, a high-performance predictor depends on adequate trainning samples, which requires unaffordable computation overhead. To alleviate this problem, we propose a novel framework to train an accuracy predictor under few training samples. The framework consists ofdata augmentation methods and an ensemble learning algorithm. The data augmentation methods calibrate weak labels and inject noise to feature space. The ensemble learning algorithm, termed cascade bagging, trains two-level models by sampling data and features. In the end, the advantages of above methods are proved in the Performance Prediciton Track of CVPR2021 1st Lightweight NAS Challenge. Our code is made public at: https://github.com/dlongry/Solutionto-CVPR2021-NAS-Track2.
Extreme Network Compression via Filter Group Approximation
Jul 31, 2018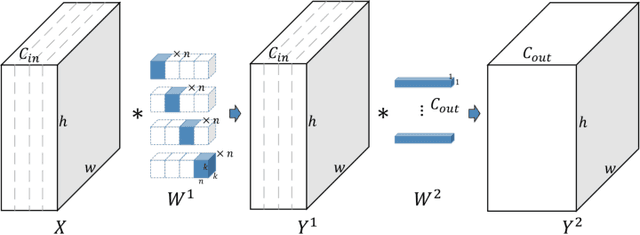

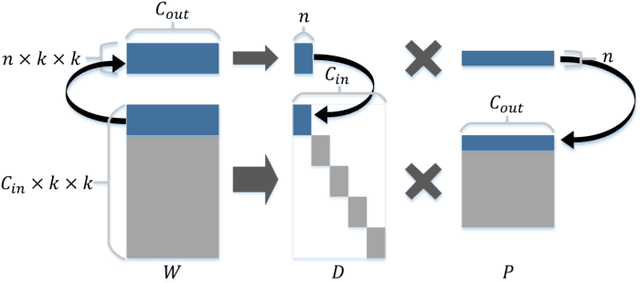
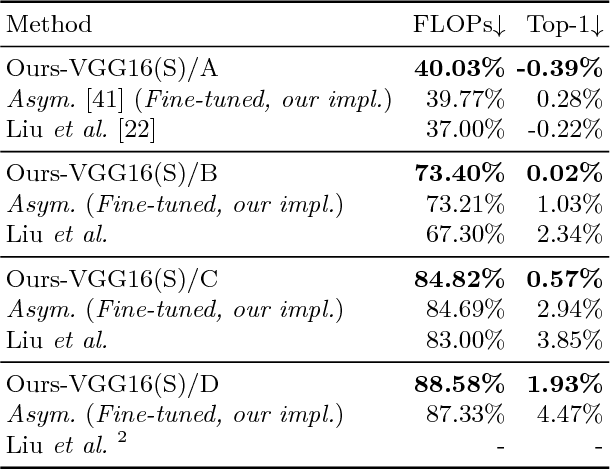
In this paper we propose a novel decomposition method based on filter group approximation, which can significantly reduce the redundancy of deep convolutional neural networks (CNNs) while maintaining the majority of feature representation. Unlike other low-rank decomposition algorithms which operate on spatial or channel dimension of filters, our proposed method mainly focuses on exploiting the filter group structure for each layer. For several commonly used CNN models, including VGG and ResNet, our method can reduce over 80% floating-point operations (FLOPs) with less accuracy drop than state-of-the-art methods on various image classification datasets. Besides, experiments demonstrate that our method is conducive to alleviating degeneracy of the compressed network, which hurts the convergence and performance of the network.