 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Layer's Trash is Another Layer's Treasure: Adaptive Layer-wise Visual Token Selection in LVLMs
Jun 12, 2026Large Vision-Language Models (LVLMs) have achieved remarkable success across diverse multimodal tasks, yet their practical deployment remains constrained by the computational burden arising from lengthy visual tokens. While visual token pruning has emerged as a promising solution, existing methods suffer from a fundamental limitation: once tokens are pruned at a specific layer, they become inaccessible to all subsequent layers, leading to premature information loss that can compromise model performance. Through empirical studies, we observe that different layers exhibit distinct visual region focus, indicating a varying optimal token subset across layers. Motivated by this insight, we propose Adaptive Layer-wise Visual Token Selection (ALVTS), a novel framework that breaks away from the conventional static token pruning paradigm. ALVTS incorporates a lightweight token selector to identify and route important tokens for further processing, while allowing less important tokens to skip the layer, thus minimizing computational redundancy. These two streams of tokens are seamlessly reintegrated before being fed into subsequent layers, facilitating adaptive compression across the entire model. Grounded in our importance consistency constrained low-rank approximation, the proposed token selection module closely emulates the full attention mechanism, effectively capturing its essential patterns without requiring model retraining. Extensive experiments on LLaVA-1.5, LLaVA-NeXT, and Qwen2.5-VL validate the effectiveness of our method. With an 89% token compression ratio, ALVTS retains 96.7% of the original model's accuracy, achieving a superior efficiency-accuracy trade-off for LVLM inference.
1+1>2: A Synergistic Sparse and Low-Rank Compression Method for Large Language Models
Oct 30, 2025


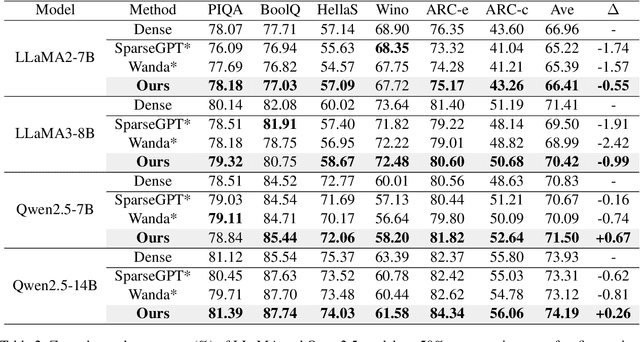
Large Language Models (LLMs) have demonstrated remarkable proficiency in language comprehension and generation; however, their widespread adoption is constrained by substantial bandwidth and computational demands. While pruning and low-rank approximation have each demonstrated promising performance individually, their synergy for LLMs remains underexplored. We introduce \underline{S}ynergistic \underline{S}parse and \underline{L}ow-Rank \underline{C}ompression (SSLC) methods for LLMs, which leverages the strengths of both techniques: low-rank approximation compresses the model by retaining its essential structure with minimal information loss, whereas sparse optimization eliminates non-essential weights, preserving those crucial for generalization. Based on theoretical analysis, we first formulate the low-rank approximation and sparse optimization as a unified problem and solve it by iterative optimization algorithm. Experiments on LLaMA and Qwen2.5 models (7B-70B) show that SSLC, without any additional training steps, consistently surpasses standalone methods, achieving state-of-the-arts results. Notably, SSLC compresses Qwen2.5 by 50\% with no performance drop and achieves at least 1.63$\times$ speedup, offering a practical solution for efficient LLM deployment.
UWC: Unit-wise Calibration Towards Rapid Network Compression
Jan 17, 2022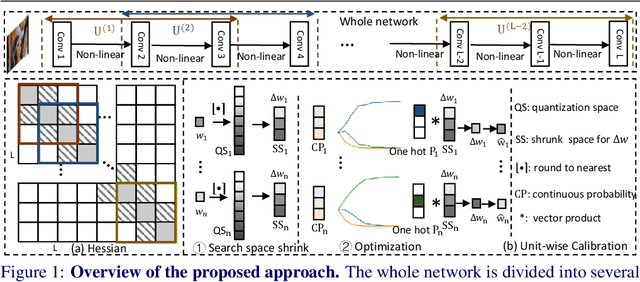
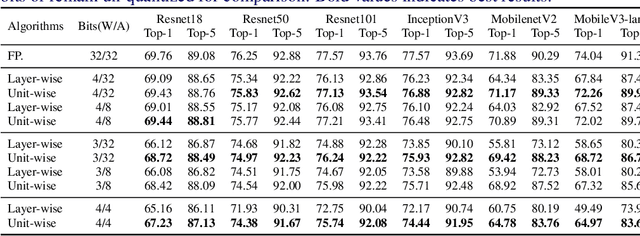
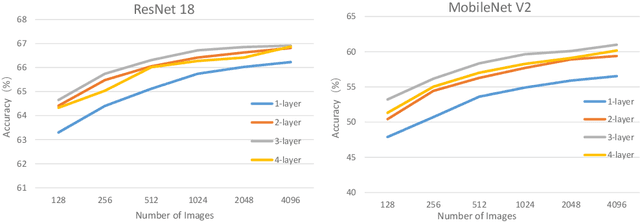
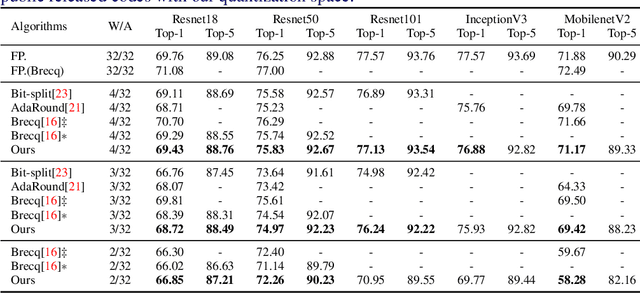
This paper introduces a post-training quantization~(PTQ) method achieving highly efficient Convolutional Neural Network~ (CNN) quantization with high performance. Previous PTQ methods usually reduce compression error via performing layer-by-layer parameters calibration. However, with lower representational ability of extremely compressed parameters (e.g., the bit-width goes less than 4), it is hard to eliminate all the layer-wise errors. This work addresses this issue via proposing a unit-wise feature reconstruction algorithm based on an observation of second order Taylor series expansion of the unit-wise error. It indicates that leveraging the interaction between adjacent layers' parameters could compensate layer-wise errors better. In this paper, we define several adjacent layers as a Basic-Unit, and present a unit-wise post-training algorithm which can minimize quantization error. This method achieves near-original accuracy on ImageNet and COCO when quantizing FP32 models to INT4 and INT3.
SOIT: Segmenting Objects with Instance-Aware Transformers
Dec 23, 2021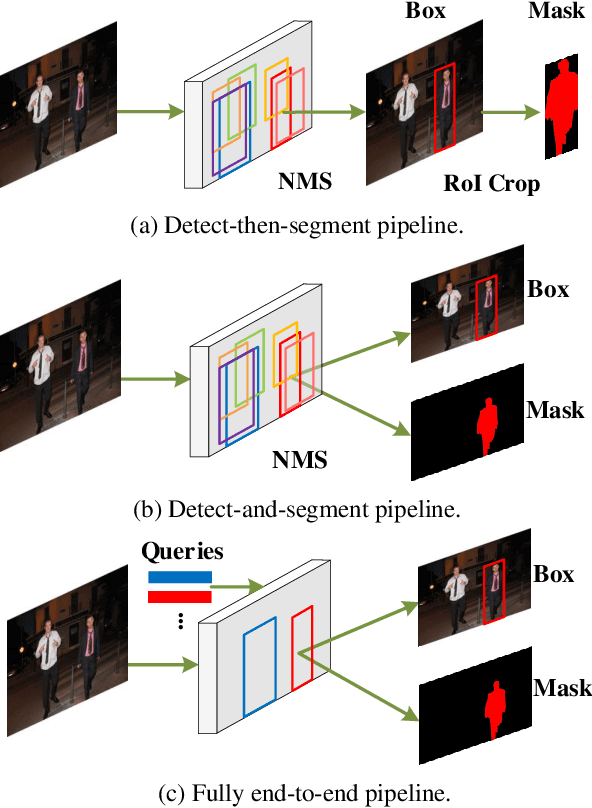
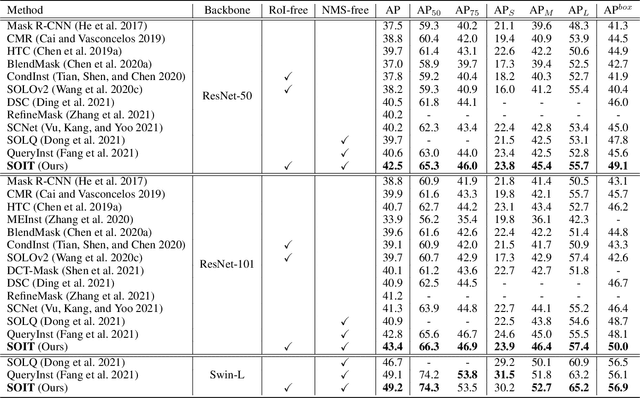
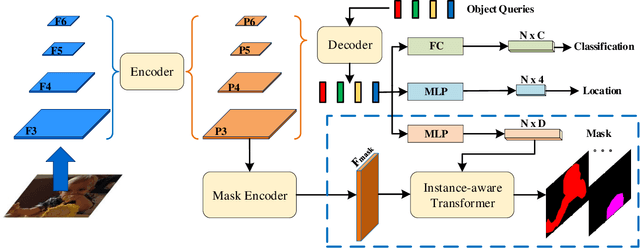
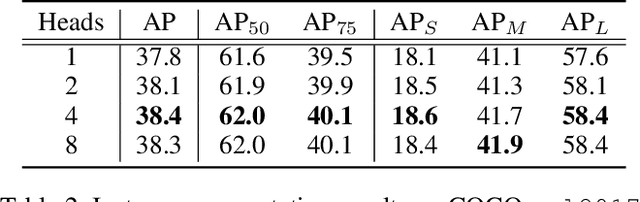
This paper presents an end-to-end instance segmentation framework, termed SOIT, that Segments Objects with Instance-aware Transformers. Inspired by DETR \cite{carion2020end}, our method views instance segmentation as a direct set prediction problem and effectively removes the need for many hand-crafted components like RoI cropping, one-to-many label assignment, and non-maximum suppression (NMS). In SOIT, multiple queries are learned to directly reason a set of object embeddings of semantic category, bounding-box location, and pixel-wise mask in parallel under the global image context. The class and bounding-box can be easily embedded by a fixed-length vector. The pixel-wise mask, especially, is embedded by a group of parameters to construct a lightweight instance-aware transformer. Afterward, a full-resolution mask is produced by the instance-aware transformer without involving any RoI-based operation. Overall, SOIT introduces a simple single-stage instance segmentation framework that is both RoI- and NMS-free. Experimental results on the MS COCO dataset demonstrate that SOIT outperforms state-of-the-art instance segmentation approaches significantly. Moreover, the joint learning of multiple tasks in a unified query embedding can also substantially improve the detection performance. Code is available at \url{https://github.com/yuxiaodongHRI/SOIT}.
InsPose: Instance-Aware Networks for Single-Stage Multi-Person Pose Estimation
Jul 20, 2021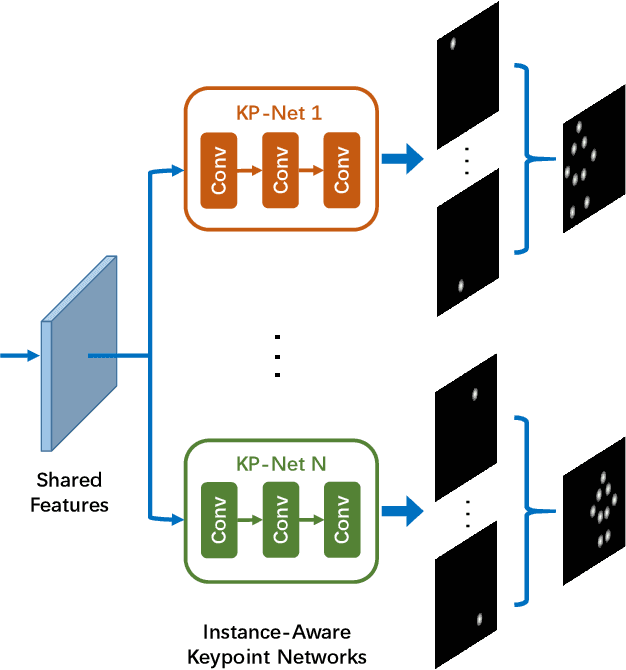


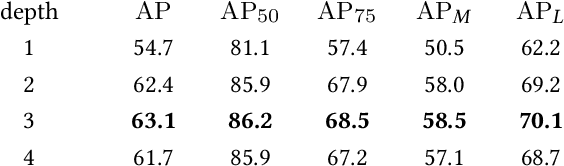
Multi-person pose estimation is an attractive and challenging task. Existing methods are mostly based on two-stage frameworks, which include top-down and bottom-up methods. Two-stage methods either suffer from high computational redundancy for additional person detectors or they need to group keypoints heuristically after predicting all the instance-agnostic keypoints. The single-stage paradigm aims to simplify the multi-person pose estimation pipeline and receives a lot of attention. However, recent single-stage methods have the limitation of low performance due to the difficulty of regressing various full-body poses from a single feature vector. Different from previous solutions that involve complex heuristic designs, we present a simple yet effective solution by employing instance-aware dynamic networks. Specifically, we propose an instance-aware module to adaptively adjust (part of) the network parameters for each instance. Our solution can significantly increase the capacity and adaptive-ability of the network for recognizing various poses, while maintaining a compact end-to-end trainable pipeline. Extensive experiments on the MS-COCO dataset demonstrate that our method achieves significant improvement over existing single-stage methods, and makes a better balance of accuracy and efficiency compared to the state-of-the-art two-stage approaches.
* arXiv admin note: text overlap with arXiv:1911.07451, arXiv:2003.05664, arXiv:2102.03026 by other authors
PolarDet: A Fast, More Precise Detector for Rotated Target in Aerial Images
Oct 17, 2020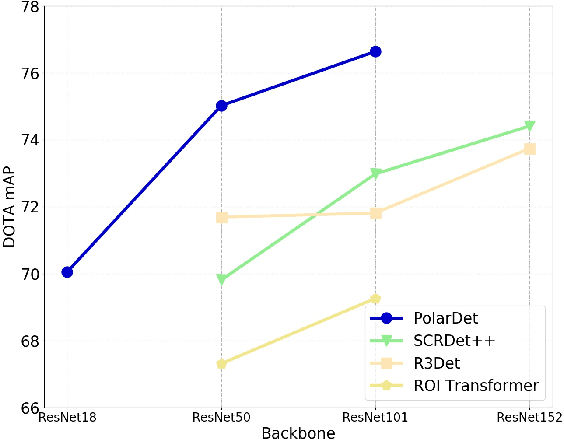

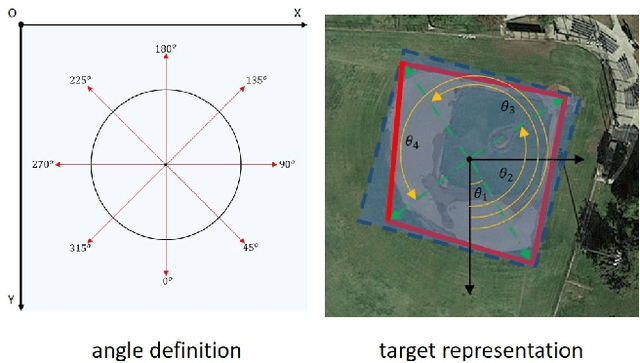

Fast and precise object detection for high-resolution aerial images has been a challenging task over the years. Due to the sharp variations on object scale, rotation, and aspect ratio, most existing methods are inefficient and imprecise. In this paper, we represent the oriented objects by polar method in polar coordinate and propose PolarDet, a fast and accurate one-stage object detector based on that representation. Our detector introduces a sub-pixel center semantic structure to further improve classifying veracity. PolarDet achieves nearly all SOTA performance in aerial object detection tasks with faster inference speed. In detail, our approach obtains the SOTA results on DOTA, UCAS-AOD, HRSC with 76.64\% mAP, 97.01\% mAP, and 90.46\% mAP respectively. Most noticeably, our PolarDet gets the best performance and reaches the fastest speed(32fps) at the UCAS-AOD dataset.