 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Efficient Reasoning with Step-Level Advantage Selection
Apr 27, 2026Large language models (LLMs) achieve strong reasoning performance by allocating substantial computation at inference time, often generating long and verbose reasoning traces. While recent work on efficient reasoning reduces this overhead through length-based rewards or pruning, many approaches are post-trained under a much shorter context window than base-model training, a factor whose effect has not been systematically isolated. We first show that short-context post-training alone, using standard GRPO without any length-aware objective, already induces substantial reasoning compression-but at the cost of increasingly unstable training dynamics and accuracy degradation. To address this, we propose Step-level Advantage Selection (SAS), which operates at the reasoning-step level and assigns a zero advantage to low-confidence steps in correct rollouts and to high-confidence steps in verifier-failed rollouts, where failures often arise from truncation or verifier issues rather than incorrect reasoning. Across diverse mathematical and general reasoning benchmarks, SAS improves average Pass@1 accuracy by 0.86 points over the strongest length-aware baseline while reducing average reasoning length by 16.3%, yielding a better accuracy-efficiency trade-off.
VideoSeek: Long-Horizon Video Agent with Tool-Guided Seeking
Mar 20, 2026Video agentic models have advanced challenging video-language tasks. However, most agentic approaches still heavily rely on greedy parsing over densely sampled video frames, resulting in high computational cost. We present VideoSeek, a long-horizon video agent that leverages video logic flow to actively seek answer-critical evidence instead of exhaustively parsing the full video. This insight allows the model to use far fewer frames while maintaining, or even improving, its video understanding capability. VideoSeek operates in a think-act-observe loop with a well-designed toolkit for collecting multi-granular video observations. This design enables query-aware exploration over accumulated observations and supports practical video understanding and reasoning. Experiments on four challenging video understanding and reasoning benchmarks demonstrate that VideoSeek achieves strong accuracy while using far fewer frames than prior video agents and standalone LMMs. Notably, VideoSeek achieves a 10.2 absolute points improvement on LVBench over its base model, GPT-5, while using 93% fewer frames. Further analysis highlights the significance of leveraging video logic flow, strong reasoning capability, and the complementary roles of toolkit design.
Effective MoE-based LLM Compression by Exploiting Heterogeneous Inter-Group Experts Routing Frequency and Information Density
Feb 11, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have achieved superior performance, yet the massive memory overhead caused by storing multiple expert networks severely hinders their practical deployment. Singular Value Decomposition (SVD)-based compression has emerged as a promising post-training technique; however, most existing methods apply uniform rank allocation or rely solely on static weight properties. This overlooks the substantial heterogeneity in expert utilization observed in MoE models, where frequent routing patterns and intrinsic information density vary significantly across experts. In this work, we propose RFID-MoE, an effective framework for MoE compression by exploiting heterogeneous Routing Frequency and Information Density. We first introduce a fused metric that combines expert activation frequency with effective rank to measure expert importance, adaptively allocating higher ranks to critical expert groups under a fixed budget. Moreover, instead of discarding compression residuals, we reconstruct them via a parameter-efficient sparse projection mechanism to recover lost information with minimal parameter overhead. Extensive experiments on representative MoE LLMs (e.g., Qwen3, DeepSeekMoE) across multiple compression ratios demonstrate that RFID-MoE consistently outperforms state-of-the-art methods like MoBE and D2-MoE. Notably, RFID-MoE achieves a perplexity of 16.92 on PTB with the Qwen3-30B model at a 60% compression ratio, reducing perplexity by over 8.0 compared to baselines, and improves zero-shot accuracy on HellaSwag by approximately 8%.
Reliable Use of Lemmas via Eligibility Reasoning and Section$-$Aware Reinforcement Learning
Feb 01, 2026Recent large language models (LLMs) perform strongly on mathematical benchmarks yet often misapply lemmas, importing conclusions without validating assumptions. We formalize lemma$-$judging as a structured prediction task: given a statement and a candidate lemma, the model must output a precondition check and a conclusion$-$utility check, from which a usefulness decision is derived. We present RULES, which encodes this specification via a two$-$section output and trains with reinforcement learning plus section$-$aware loss masking to assign penalty to the section responsible for errors. Training and evaluation draw on diverse natural language and formal proof corpora; robustness is assessed with a held$-$out perturbation suite; and end$-$to$-$end evaluation spans competition$-$style, perturbation$-$aligned, and theorem$-$based problems across various LLMs. Results show consistent in$-$domain gains over both a vanilla model and a single$-$label RL baseline, larger improvements on applicability$-$breaking perturbations, and parity or modest gains on end$-$to$-$end tasks; ablations indicate that the two$-$section outputs and section$-$aware reinforcement are both necessary for robustness.
CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models
Jan 05, 2026Autoregressive large language models achieve strong results on many benchmarks, but decoding remains fundamentally latency-limited by sequential dependence on previously generated tokens. Diffusion language models (DLMs) promise parallel generation but suffer from a fundamental static-to-dynamic misalignment: Training optimizes local transitions under fixed schedules, whereas efficient inference requires adaptive "long-jump" refinements through unseen states. Our goal is to enable highly parallel decoding for DLMs with low number of function evaluations while preserving generation quality. To achieve this, we propose CD4LM, a framework that decouples training from inference via Discrete-Space Consistency Distillation (DSCD) and Confidence-Adaptive Decoding (CAD). Unlike standard objectives, DSCD trains a student to be trajectory-invariant, mapping diverse noisy states directly to the clean distribution. This intrinsic robustness enables CAD to dynamically allocate compute resources based on token confidence, aggressively skipping steps without the quality collapse typical of heuristic acceleration. On GSM8K, CD4LM matches the LLaDA baseline with a 5.18x wall-clock speedup; across code and math benchmarks, it strictly dominates the accuracy-efficiency Pareto frontier, achieving a 3.62x mean speedup while improving average accuracy. Code is available at https://github.com/yihao-liang/CDLM
Instella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
An Efficient Gradient-Aware Error-Bounded Lossy Compressor for Federated Learning
Nov 07, 2025Federated learning (FL) enables collaborative model training without exposing clients' private data, but its deployment is often constrained by the communication cost of transmitting gradients between clients and the central server, especially under system heterogeneity where low-bandwidth clients bottleneck overall performance. Lossy compression of gradient data can mitigate this overhead, and error-bounded lossy compression (EBLC) is particularly appealing for its fine-grained utility-compression tradeoff. However, existing EBLC methods (e.g., SZ), originally designed for smooth scientific data with strong spatial locality, rely on generic predictors such as Lorenzo and interpolation for entropy reduction to improve compression ratio. Gradient tensors, in contrast, exhibit low smoothness and weak spatial correlation, rendering these predictors ineffective and leading to poor compression ratios. To address this limitation, we propose an EBLC framework tailored for FL gradient data to achieve high compression ratios while preserving model accuracy. The core of it is an innovative prediction mechanism that exploits temporal correlations across FL training rounds and structural regularities within convolutional kernels to reduce residual entropy. The predictor is compatible with standard quantizers and entropy coders and comprises (1) a cross-round magnitude predictor based on a normalized exponential moving average, and (2) a sign predictor that leverages gradient oscillation and kernel-level sign consistency. Experiments show that this new EBLC yields up to 1.53x higher compression ratios than SZ3 with lower accuracy loss. Integrated into a real-world FL framework, APPFL, it reduces end-to-end communication time by 76.1%-96.2% under various constrained-bandwidth scenarios, demonstrating strong scalability for real-world FL deployments.
Learning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025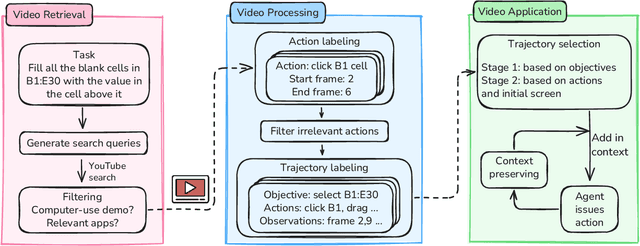



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.
MoE-Compression: How the Compression Error of Experts Affects the Inference Accuracy of MoE Model?
Sep 09, 2025With the widespread application of Mixture of Experts (MoE) reasoning models in the field of LLM learning, efficiently serving MoE models under limited GPU memory constraints has emerged as a significant challenge. Offloading the non-activated experts to main memory has been identified as an efficient approach to address such a problem, while it brings the challenges of transferring the expert between the GPU memory and main memory. We need to explore an efficient approach to compress the expert and analyze how the compression error affects the inference performance. To bridge this gap, we propose employing error-bounded lossy compression algorithms (such as SZ3 and CuSZp) to compress non-activated experts, thereby reducing data transfer overhead during MoE inference. We conduct extensive experiments across various benchmarks and present a comprehensive analysis of how compression-induced errors in different experts affect overall inference accuracy. The results indicate that experts in the shallow layers, which are primarily responsible for the attention mechanism and the transformation of input tokens into vector representations, exhibit minimal degradation in inference accuracy when subjected to bounded errors. In contrast, errors in the middle-layer experts, which are central to model reasoning, significantly impair inference accuracy. Interestingly, introducing bounded errors in the deep-layer experts, which are mainly responsible for instruction following and output integration, can sometimes lead to improvements in inference accuracy.
Instella-T2I: Pushing the Limits of 1D Discrete Latent Space Image Generation
Jun 26, 2025Image tokenization plays a critical role in reducing the computational demands of modeling high-resolution images, significantly improving the efficiency of image and multimodal understanding and generation. Recent advances in 1D latent spaces have reduced the number of tokens required by eliminating the need for a 2D grid structure. In this paper, we further advance compact discrete image representation by introducing 1D binary image latents. By representing each image as a sequence of binary vectors, rather than using traditional one-hot codebook tokens, our approach preserves high-resolution details while maintaining the compactness of 1D latents. To the best of our knowledge, our text-to-image models are the first to achieve competitive performance in both diffusion and auto-regressive generation using just 128 discrete tokens for images up to 1024x1024, demonstrating up to a 32-fold reduction in token numbers compared to standard VQ-VAEs. The proposed 1D binary latent space, coupled with simple model architectures, achieves marked improvements in speed training and inference speed. Our text-to-image models allow for a global batch size of 4096 on a single GPU node with 8 AMD MI300X GPUs, and the training can be completed within 200 GPU days. Our models achieve competitive performance compared to modern image generation models without any in-house private training data or post-training refinements, offering a scalable and efficient alternative to conventional tokenization methods.