 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
Jul 28, 2025The demand for Large Language Models (LLMs) capable of sophisticated mathematical reasoning is growing across industries. However, the development of performant mathematical LLMs is critically bottlenecked by the scarcity of difficult, novel training data. We introduce \textbf{SAND-Math} (Synthetic Augmented Novel and Difficult Mathematics problems and solutions), a pipeline that addresses this by first generating high-quality problems from scratch and then systematically elevating their complexity via a new \textbf{Difficulty Hiking} step. We demonstrate the effectiveness of our approach through two key findings. First, augmenting a strong baseline with SAND-Math data significantly boosts performance, outperforming the next-best synthetic dataset by \textbf{$\uparrow$ 17.85 absolute points} on the AIME25 benchmark. Second, in a dedicated ablation study, we show our Difficulty Hiking process is highly effective: by increasing average problem difficulty from 5.02 to 5.98, this step lifts AIME25 performance from 46.38\% to 49.23\%. The full generation pipeline, final dataset, and a fine-tuned model form a practical and scalable toolkit for building more capable and efficient mathematical reasoning LLMs. SAND-Math dataset is released here: \href{https://huggingface.co/datasets/amd/SAND-MATH}{https://huggingface.co/datasets/amd/SAND-MATH}
TTT-Bench: A Benchmark for Evaluating Reasoning Ability with Simple and Novel Tic-Tac-Toe-style Games
Jun 11, 2025Large reasoning models (LRMs) have demonstrated impressive reasoning capabilities across a broad range of tasks including Olympiad-level mathematical problems, indicating evidence of their complex reasoning abilities. While many reasoning benchmarks focus on the STEM domain, the ability of LRMs to reason correctly in broader task domains remains underexplored. In this work, we introduce \textbf{TTT-Bench}, a new benchmark that is designed to evaluate basic strategic, spatial, and logical reasoning abilities in LRMs through a suite of four two-player Tic-Tac-Toe-style games that humans can effortlessly solve from a young age. We propose a simple yet scalable programmatic approach for generating verifiable two-player game problems for TTT-Bench. Although these games are trivial for humans, they require reasoning about the intentions of the opponent, as well as the game board's spatial configurations, to ensure a win. We evaluate a diverse set of state-of-the-art LRMs, and \textbf{discover that the models that excel at hard math problems frequently fail at these simple reasoning games}. Further testing reveals that our evaluated reasoning models score on average $\downarrow$ 41\% \& $\downarrow$ 5\% lower on TTT-Bench compared to MATH 500 \& AIME 2024 respectively, with larger models achieving higher performance using shorter reasoning traces, where most of the models struggle on long-term strategic reasoning situations on simple and new TTT-Bench tasks.
SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Feb 21, 2024

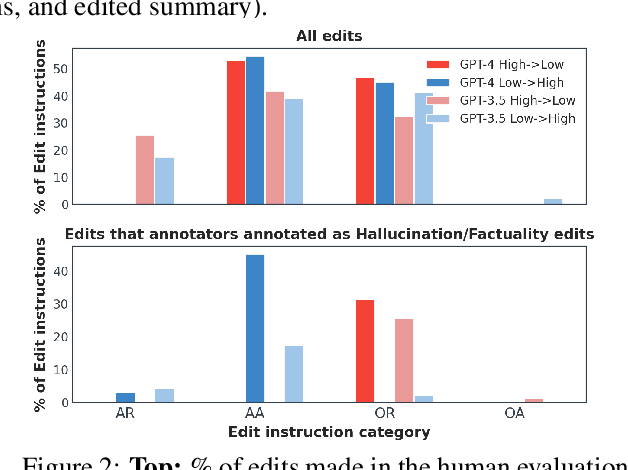
Large Language Models (LLMs) such as GPT and Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes GPT-3.5 and GPT-4 to generate high-quality feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback, mirroring the practical scenario in which medical professionals refine AI system outputs without the need for additional annotations. Despite GPT's proven expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on its capacity to deliver expert-level edit feedback for improving weaker LMs or LLMs generation quality. This work leverages GPT's advanced capabilities in clinical NLP to offer expert-level edit feedback. Through the use of two distinct alignment algorithms (DPO and SALT) based on GPT edit feedback, our goal is to reduce hallucinations and align closely with medical facts, endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of GPT edits in enhancing the alignment of clinical factuality.
Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Nov 03, 2023Large Language Models (LLMs) like the GPT and LLaMA families have demonstrated exceptional capabilities in capturing and condensing critical contextual information and achieving state-of-the-art performance in the summarization task. However, community concerns about these models' hallucination issues continue to rise. LLMs sometimes generate factually hallucinated summaries, which can be extremely harmful in the clinical domain NLP tasks (e.g., clinical note summarization), where factually incorrect statements can lead to critically erroneous diagnoses. Fine-tuning LLMs using human feedback has shown the promise of aligning LLMs to be factually consistent during generation, but such training procedure requires high-quality human-annotated data, which can be extremely expensive to get in the clinical domain. In this work, we propose a new pipeline using ChatGPT instead of human experts to generate high-quality feedback data for improving factual consistency in the clinical note summarization task. We focus specifically on edit feedback because recent work discusses the shortcomings of human alignment via preference feedback in complex situations (such as clinical NLP tasks that require extensive expert knowledge), as well as some advantages of collecting edit feedback from domain experts. In addition, although GPT has reached the expert level in many clinical NLP tasks (e.g., USMLE QA), there is not much previous work discussing whether GPT can generate expert-level edit feedback for LMs in the clinical note summarization task. We hope to fill this gap. Finally, our evaluations demonstrate the potential use of GPT edits in human alignment, especially from a factuality perspective.
Sarcasm detection from user-generated noisy short text
Nov 26, 2020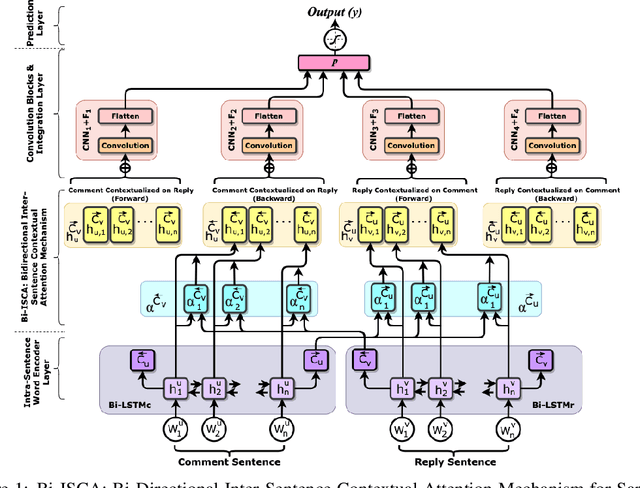
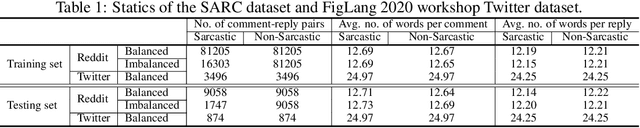
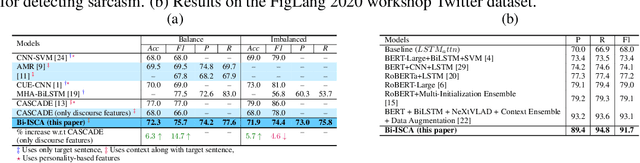

Sentiment analysis of social media comments is very important for review analysis. Many online reviews are sarcastic, humorous, or hateful. This sarcastic nature of these short texts change the actual sentiments of the review as predicted by a machine learning model that attempts to detect sentiment alone. Thus, having a model that is explicitly aware of these features should help it perform better on reviews that are characterized by them. Several research has already been done in this field. This paper deals with sarcasm detection on reddit comments. Several machine learning and deep learning algorithms have been applied for the same but each of these models only take into account the initial text instead of the conversation which serves as a better measure to determine sarcasm. The other shortcoming these papers have is they rely on word embedding for representing comments and thus do not take into account the problem of polysemy(A word can have multiple meanings based on the context in which it appears). These existing modules were able to solve the problem of capturing inter sentence contextual information but not the intra sentence contextual information. So we propose a novel architecture which solves the problem of sarcasm detection by capturing intra sentence contextual information using a novel contextual attention mechanism. The proposed model solves the problem of polysemy also by using context enriched language modules like ELMO and BERT in its first component. This model comprises a total of three major components which takes into account inter sentence, intra sentence contextual information and at last use a convolutional neural network for capturing global contextual information for sarcasm detection. The proposed model was able to generate decent results and cleared showed potential to perform state of the art if trained on a larger dataset.
STEPs-RL: Speech-Text Entanglement for Phonetically Sound Representation Learning
Nov 23, 2020


In this paper, we present a novel multi-modal deep neural network architecture that uses speech and text entanglement for learning phonetically sound spoken-word representations. STEPs-RL is trained in a supervised manner to predict the phonetic sequence of a target spoken-word using its contextual spoken word's speech and text, such that the model encodes its meaningful latent representations. Unlike existing work, we have used text along with speech for auditory representation learning to capture semantical and syntactical information along with the acoustic and temporal information. The latent representations produced by our model were not only able to predict the target phonetic sequences with an accuracy of 89.47% but were also able to achieve competitive results to textual word representation models, Word2Vec & FastText (trained on textual transcripts), when evaluated on four widely used word similarity benchmark datasets. In addition, investigation of the generated vector space also demonstrated the capability of the proposed model to capture the phonetic structure of the spoken-words. To the best of our knowledge, none of the existing works use speech and text entanglement for learning spoken-word representation, which makes this work first of its kind.
Contextualized Spoken Word Representations from Convolutional Autoencoders
Jul 06, 2020


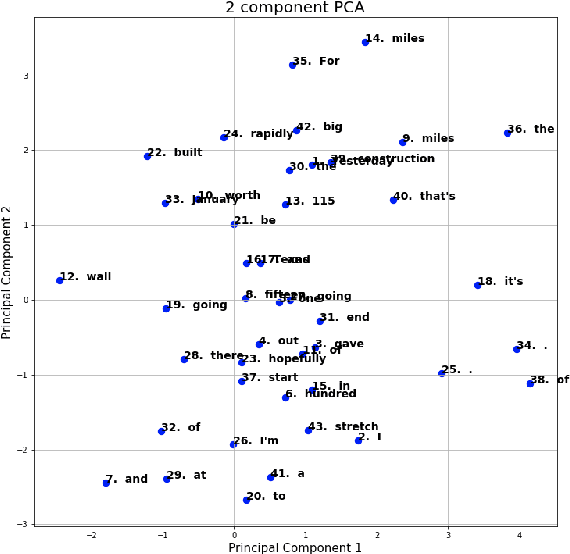
A lot of work has been done recently to build sound language models for the textual data, but not much such has been done in the case of speech/audio type data. In the case of text, words can be represented by a unique fixed-length vector. Such models for audio type data can not only lead to great advances in the speech-related natural language processing tasks but can also reduce the need for converting speech to text for performing the same. This paper proposes a novel model architecture that produces syntactically, contextualized, and semantically adequate representation of varying length spoken words. The performance of the spoken word embeddings generated by the proposed model was validated by (1) inspecting the vector space generated, and (2) evaluating its performance on the downstream task of next spoken word prediction in a speech.
Correlated Feature Selection for Tweet Spam Classification using Artificial Neural Networks
Nov 27, 2019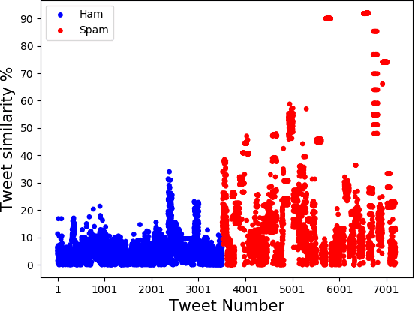
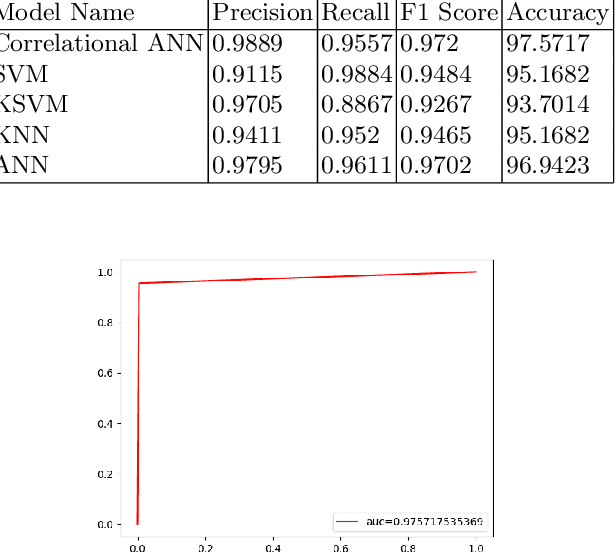

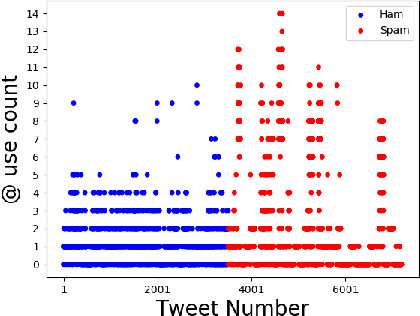
Identification of spam messages is a very challenging task for social networks due to its large size and complex nature. The purpose of this paper is to undertake the analysis of spamming on Twitter. To classify spams efficiently it is necessary to first understand the features of the spam tweets as well as identify attributes of the spammer. We extract both tweet based features and user based features for our analysis and observe the correlation between these features. This step is necessary as we can reduce the training time if we combine the features that are highly correlated. To perform our analysis we use artificial neural networks and train the model to classify the tweets as spam or non-spam. Using Correlational Artificial Neural Network gives us the highest accuracy of 97.57\% when compared with four other classifiers SVM, Kernel SVM, K Nearest Neighbours and Artificial Neural Network.