 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Paper and Code

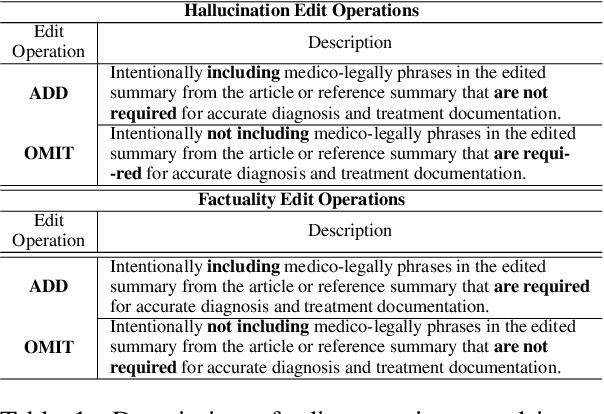

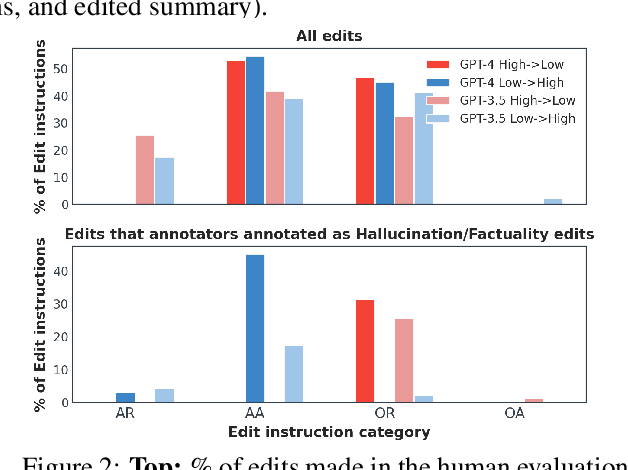
Large Language Models (LLMs) such as GPT and Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes GPT-3.5 and GPT-4 to generate high-quality feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback, mirroring the practical scenario in which medical professionals refine AI system outputs without the need for additional annotations. Despite GPT's proven expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on its capacity to deliver expert-level edit feedback for improving weaker LMs or LLMs generation quality. This work leverages GPT's advanced capabilities in clinical NLP to offer expert-level edit feedback. Through the use of two distinct alignment algorithms (DPO and SALT) based on GPT edit feedback, our goal is to reduce hallucinations and align closely with medical facts, endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of GPT edits in enhancing the alignment of clinical factuality.