 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting 3D representations for Dynamic Scenes
Jan 28, 2025



We present a novel framework for dynamic radiance field prediction given monocular video streams. Unlike previous methods that primarily focus on predicting future frames, our method goes a step further by generating explicit 3D representations of the dynamic scene. The framework builds on two core designs. First, we adopt an ego-centric unbounded triplane to explicitly represent the dynamic physical world. Second, we develop a 4D-aware transformer to aggregate features from monocular videos to update the triplane. Coupling these two designs enables us to train the proposed model with large-scale monocular videos in a self-supervised manner. Our model achieves top results in dynamic radiance field prediction on NVIDIA dynamic scenes, demonstrating its strong performance on 4D physical world modeling. Besides, our model shows a superior generalizability to unseen scenarios. Notably, we find that our approach emerges capabilities for geometry and semantic learning.
Gender Biased Legal Case Retrieval System on Users' Decision Process
Feb 25, 2024



In the last decade, legal case search has become an important part of a legal practitioner's work. During legal case search, search engines retrieval a number of relevant cases from huge amounts of data and serve them to users. However, it is uncertain whether these cases are gender-biased and whether such bias has impact on user perceptions. We designed a new user experiment framework to simulate the judges' reading of relevant cases. 72 participants with backgrounds in legal affairs invited to conduct the experiment. Participants were asked to simulate the role of the judge in conducting a legal case search on 3 assigned cases and determine the sentences of the defendants in these cases. Gender of the defendants in both the task and relevant cases was edited to statistically measure the effect of gender bias in the legal case search results on participants' perceptions. The results showed that gender bias in the legal case search results did not have a significant effect on judges' perceptions.
SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Feb 21, 2024
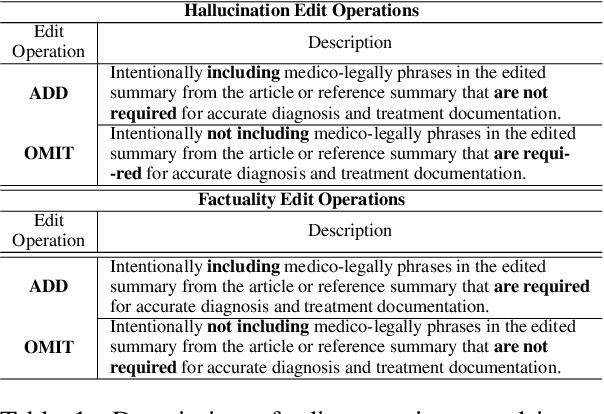

Large Language Models (LLMs) such as GPT and Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes GPT-3.5 and GPT-4 to generate high-quality feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback, mirroring the practical scenario in which medical professionals refine AI system outputs without the need for additional annotations. Despite GPT's proven expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on its capacity to deliver expert-level edit feedback for improving weaker LMs or LLMs generation quality. This work leverages GPT's advanced capabilities in clinical NLP to offer expert-level edit feedback. Through the use of two distinct alignment algorithms (DPO and SALT) based on GPT edit feedback, our goal is to reduce hallucinations and align closely with medical facts, endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of GPT edits in enhancing the alignment of clinical factuality.
Do Physicians Know How to Prompt? The Need for Automatic Prompt Optimization Help in Clinical Note Generation
Nov 16, 2023
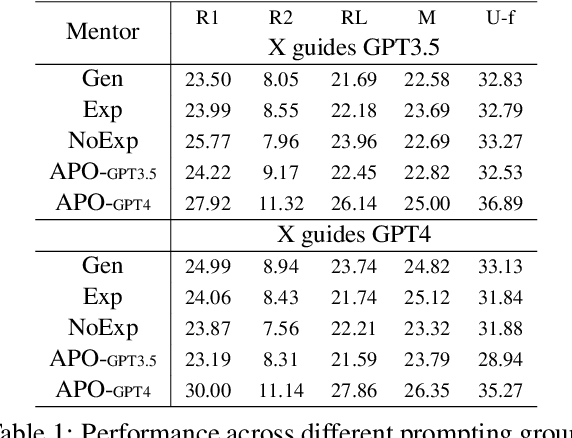
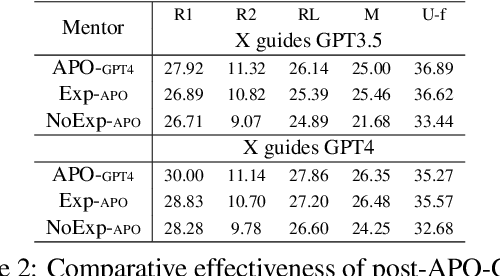
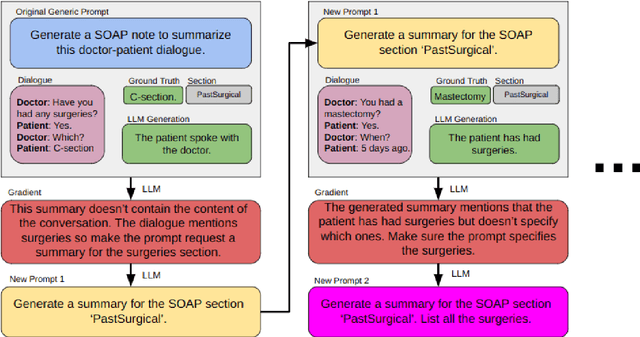
This study examines the effect of prompt engineering on the performance of Large Language Models (LLMs) in clinical note generation. We introduce an Automatic Prompt Optimization (APO) framework to refine initial prompts and compare the outputs of medical experts, non-medical experts, and APO-enhanced GPT3.5 and GPT4. Results highlight GPT4 APO's superior performance in standardizing prompt quality across clinical note sections. A human-in-the-loop approach shows that experts maintain content quality post-APO, with a preference for their own modifications, suggesting the value of expert customization. We recommend a two-phase optimization process, leveraging APO-GPT4 for consistency and expert input for personalization.
Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Nov 03, 2023Large Language Models (LLMs) like the GPT and LLaMA families have demonstrated exceptional capabilities in capturing and condensing critical contextual information and achieving state-of-the-art performance in the summarization task. However, community concerns about these models' hallucination issues continue to rise. LLMs sometimes generate factually hallucinated summaries, which can be extremely harmful in the clinical domain NLP tasks (e.g., clinical note summarization), where factually incorrect statements can lead to critically erroneous diagnoses. Fine-tuning LLMs using human feedback has shown the promise of aligning LLMs to be factually consistent during generation, but such training procedure requires high-quality human-annotated data, which can be extremely expensive to get in the clinical domain. In this work, we propose a new pipeline using ChatGPT instead of human experts to generate high-quality feedback data for improving factual consistency in the clinical note summarization task. We focus specifically on edit feedback because recent work discusses the shortcomings of human alignment via preference feedback in complex situations (such as clinical NLP tasks that require extensive expert knowledge), as well as some advantages of collecting edit feedback from domain experts. In addition, although GPT has reached the expert level in many clinical NLP tasks (e.g., USMLE QA), there is not much previous work discussing whether GPT can generate expert-level edit feedback for LMs in the clinical note summarization task. We hope to fill this gap. Finally, our evaluations demonstrate the potential use of GPT edits in human alignment, especially from a factuality perspective.
Investigating the Influence of Legal Case Retrieval Systems on Users' Decision Process
Oct 07, 2023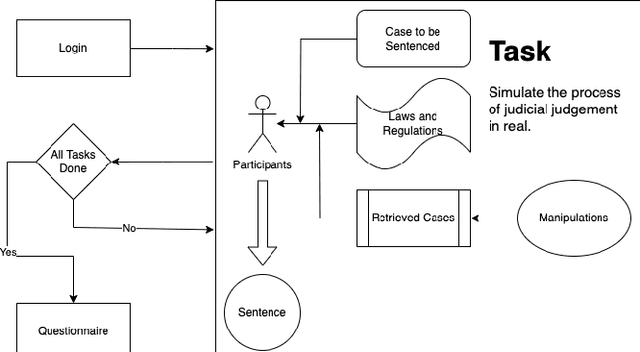


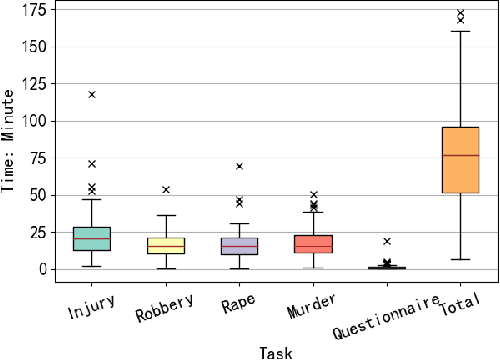
Given a specific query case, legal case retrieval systems aim to retrieve a set of case documents relevant to the case at hand. Previous studies on user behavior analysis have shown that information retrieval (IR) systems can significantly influence users' decisions by presenting results in varying orders and formats. However, whether such influence exists in legal case retrieval remains largely unknown. This study presents the first investigation into the influence of legal case retrieval systems on the decision-making process of legal users. We conducted an online user study involving more than ninety participants, and our findings suggest that the result distribution of legal case retrieval systems indeed affect users' judgements on the sentences in cases. Notably, when users are presented with biased results that involve harsher sentences, they tend to impose harsher sentences on the current case as well. This research highlights the importance of optimizing the unbiasedness of legal case retrieval systems.