 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Task and Motion Planning: Hierarchical Robot Planning with General-Purpose Policies
Apr 24, 2025

Task and motion planning is a well-established approach for solving long-horizon robot planning problems. However, traditional methods assume that each task-level robot action, or skill, can be reduced to kinematic motion planning. In this work, we address the challenge of planning with both kinematic skills and closed-loop motor controllers that go beyond kinematic considerations. We propose a novel method that integrates these controllers into motion planning using Composable Interaction Primitives (CIPs), enabling the use of diverse, non-composable pre-learned skills in hierarchical robot planning. Toward validating our Task and Skill Planning (TASP) approach, we describe ongoing robot experiments in real-world scenarios designed to demonstrate how CIPs can allow a mobile manipulator robot to effectively combine motion planning with general-purpose skills to accomplish complex tasks.
LaNMP: A Language-Conditioned Mobile Manipulation Benchmark for Autonomous Robots
Nov 28, 2024


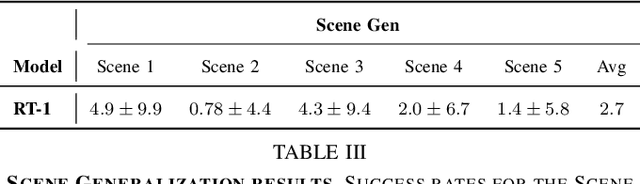
As robots that follow natural language become more capable and prevalent, we need a benchmark to holistically develop and evaluate their ability to solve long-horizon mobile manipulation tasks in large, diverse environments. To tackle this challenge, robots must use visual and language understanding, navigation, and manipulation capabilities. Existing datasets do not integrate all these aspects, restricting their efficacy as benchmarks. To address this gap, we present the Language, Navigation, Manipulation, Perception (LaNMP, pronounced Lamp) dataset and demonstrate the benefits of integrating these four capabilities and various modalities. LaNMP comprises 574 trajectories across eight simulated and real-world environments for long-horizon room-to-room pick-and-place tasks specified by natural language. Every trajectory consists of over 20 attributes, including RGB-D images, segmentations, and the poses of the robot body, end-effector, and grasped objects. We fine-tuned and tested two models in simulation, and evaluated a third on a physical robot, to demonstrate the benchmark's applicability in development and evaluation, as well as making models more sample efficient. The models performed suboptimally compared to humans; however, showed promise in increasing model sample efficiency, indicating significant room for developing more sample efficient multimodal mobile manipulation models using our benchmark.
Compositional Zero-Shot Learning for Attribute-Based Object Reference in Human-Robot Interaction
Dec 21, 2023Language-enabled robots have been widely studied over the past years to enable natural human-robot interaction and teaming in various real-world applications. Language-enabled robots must be able to comprehend referring expressions to identify a particular object from visual perception using a set of referring attributes extracted from natural language. However, visual observations of an object may not be available when it is referred to, and the number of objects and attributes may also be unbounded in open worlds. To address the challenges, we implement an attribute-based compositional zero-shot learning method that uses a list of attributes to perform referring expression comprehension in open worlds. We evaluate the approach on two datasets including the MIT-States and the Clothing 16K. The preliminary experimental results show that our implemented approach allows a robot to correctly identify the objects referred to by human commands.
Do Physicians Know How to Prompt? The Need for Automatic Prompt Optimization Help in Clinical Note Generation
Nov 16, 2023
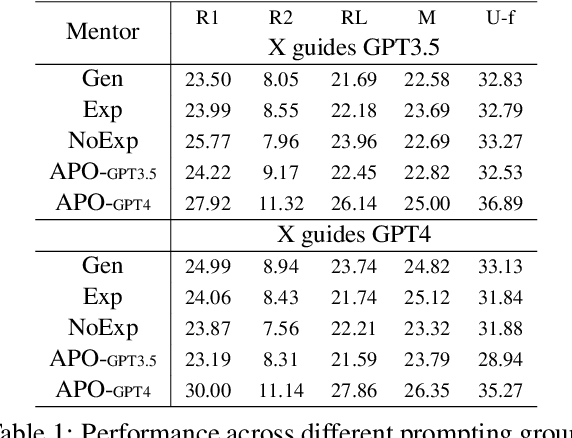
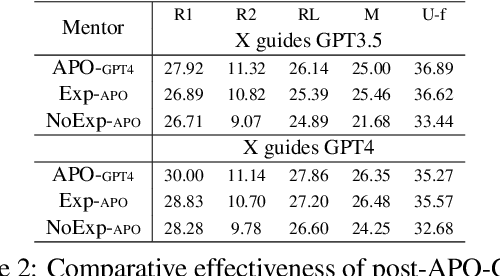
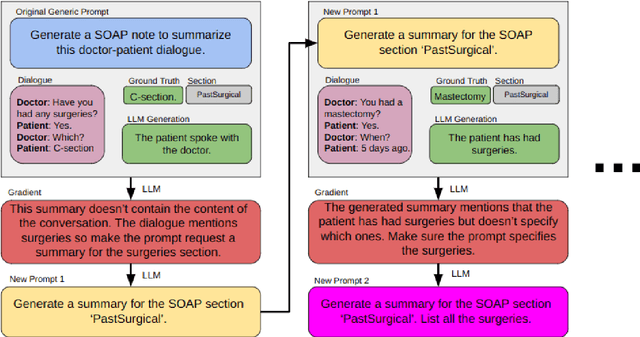
This study examines the effect of prompt engineering on the performance of Large Language Models (LLMs) in clinical note generation. We introduce an Automatic Prompt Optimization (APO) framework to refine initial prompts and compare the outputs of medical experts, non-medical experts, and APO-enhanced GPT3.5 and GPT4. Results highlight GPT4 APO's superior performance in standardizing prompt quality across clinical note sections. A human-in-the-loop approach shows that experts maintain content quality post-APO, with a preference for their own modifications, suggesting the value of expert customization. We recommend a two-phase optimization process, leveraging APO-GPT4 for consistency and expert input for personalization.