 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaNMP: A Language-Conditioned Mobile Manipulation Benchmark for Autonomous Robots
Nov 28, 2024


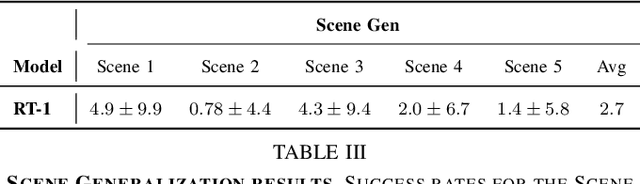
As robots that follow natural language become more capable and prevalent, we need a benchmark to holistically develop and evaluate their ability to solve long-horizon mobile manipulation tasks in large, diverse environments. To tackle this challenge, robots must use visual and language understanding, navigation, and manipulation capabilities. Existing datasets do not integrate all these aspects, restricting their efficacy as benchmarks. To address this gap, we present the Language, Navigation, Manipulation, Perception (LaNMP, pronounced Lamp) dataset and demonstrate the benefits of integrating these four capabilities and various modalities. LaNMP comprises 574 trajectories across eight simulated and real-world environments for long-horizon room-to-room pick-and-place tasks specified by natural language. Every trajectory consists of over 20 attributes, including RGB-D images, segmentations, and the poses of the robot body, end-effector, and grasped objects. We fine-tuned and tested two models in simulation, and evaluated a third on a physical robot, to demonstrate the benchmark's applicability in development and evaluation, as well as making models more sample efficient. The models performed suboptimally compared to humans; however, showed promise in increasing model sample efficiency, indicating significant room for developing more sample efficient multimodal mobile manipulation models using our benchmark.
Categorizing the Visual Environment and Analyzing the Visual Attention of Dogs
Nov 20, 2023Dogs have a unique evolutionary relationship with humans and serve many important roles e.g. search and rescue, blind assistance, emotional support. However, few datasets exist to categorize visual features and objects available to dogs, as well as how dogs direct their visual attention within their environment. We collect and study a dataset with over 11,698 gazes to categorize the objects available to be gazed at by 11 dogs in everyday outdoor environments i.e. a walk around a college campus and urban area. We explore the availability of these object categories and the visual attention of dogs over these categories using a head mounted eye tracking apparatus. A small portion (approx. 600 images or < 20% of total dataset) of the collected data is used to fine tune a MaskRCNN for the novel image domain to segment objects present in the scene, enabling further statistical analysis on the visual gaze tendencies of dogs. The MaskRCNN, with eye tracking apparatus, serves as an end to end model for automatically classifying the visual fixations of dogs. The fine tuned MaskRCNN performs far better than chance. There are few individual differences between the 11 dogs and we observe greater visual fixations on buses, plants, pavement, and construction equipment. This work takes a step towards understanding visual behavior of dogs and their interaction with the physical world.
Planning with Large Language Models via Corrective Re-prompting
Nov 17, 2022
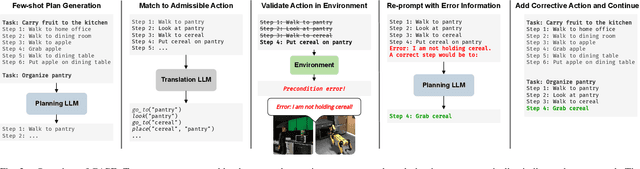
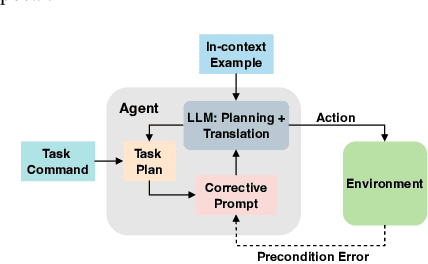
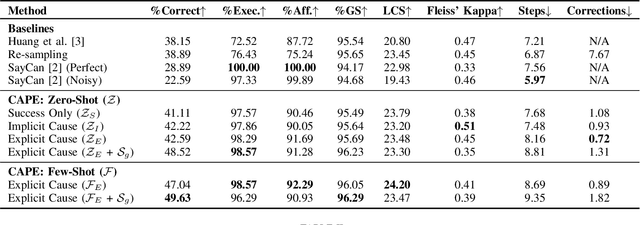
Extracting the common sense knowledge present in Large Language Models (LLMs) offers a path to designing intelligent, embodied agents. Related works have queried LLMs with a wide-range of contextual information, such as goals, sensor observations and scene descriptions, to generate high-level action plans for specific tasks; however these approaches often involve human intervention or additional machinery to enable sensor-motor interactions. In this work, we propose a prompting-based strategy for extracting executable plans from an LLM, which leverages a novel and readily-accessible source of information: precondition errors. Our approach assumes that actions are only afforded execution in certain contexts, i.e., implicit preconditions must be met for an action to execute (e.g., a door must be unlocked to open it), and that the embodied agent has the ability to determine if the action is/is not executable in the current context (e.g., detect if a precondition error is present). When an agent is unable to execute an action, our approach re-prompts the LLM with precondition error information to extract an executable corrective action to achieve the intended goal in the current context. We evaluate our approach in the VirtualHome simulation environment on 88 different tasks and 7 scenes. We evaluate different prompt templates and compare to methods that naively re-sample actions from the LLM. Our approach, using precondition errors, improves executability and semantic correctness of plans, while also reducing the number of re-prompts required when querying actions.