 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Predicates and Actions Enables Zero-Shot Skill Composition
May 20, 2026Learning from Demonstration (LfD) enables robots to learn complex behaviors from expert examples, yet existing approaches often fail to generalize to new compositions of known skills without retraining. Modern generative policies model distributions over action trajectories alone, thus are unable to reason about the symbolic outcomes required for robust composition. We propose that skills should jointly model action trajectories and the symbolic outcomes they induce. To address this gap, we introduce Predicate Action Skills (PACTS), a class of closed-loop visuomotor policies that model skills as a joint generative process over action and predicate belief trajectories, producing coherent action-outcome rollouts within a single model. Jointly generating actions and predicates enables PACTS to learn internal representations that improve both action generation and predicate classification. Furthermore, we demonstrate zero-shot composition of learned skills via planning by leveraging online predicate predictions from PACTS as a symbolic interface for sequencing and monitoring execution. Project website: https://planpacts.github.io/
LaNMP: A Language-Conditioned Mobile Manipulation Benchmark for Autonomous Robots
Nov 28, 2024


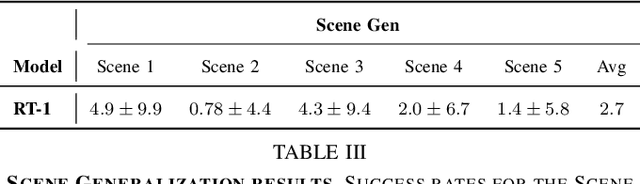
As robots that follow natural language become more capable and prevalent, we need a benchmark to holistically develop and evaluate their ability to solve long-horizon mobile manipulation tasks in large, diverse environments. To tackle this challenge, robots must use visual and language understanding, navigation, and manipulation capabilities. Existing datasets do not integrate all these aspects, restricting their efficacy as benchmarks. To address this gap, we present the Language, Navigation, Manipulation, Perception (LaNMP, pronounced Lamp) dataset and demonstrate the benefits of integrating these four capabilities and various modalities. LaNMP comprises 574 trajectories across eight simulated and real-world environments for long-horizon room-to-room pick-and-place tasks specified by natural language. Every trajectory consists of over 20 attributes, including RGB-D images, segmentations, and the poses of the robot body, end-effector, and grasped objects. We fine-tuned and tested two models in simulation, and evaluated a third on a physical robot, to demonstrate the benchmark's applicability in development and evaluation, as well as making models more sample efficient. The models performed suboptimally compared to humans; however, showed promise in increasing model sample efficiency, indicating significant room for developing more sample efficient multimodal mobile manipulation models using our benchmark.
Verifiably Following Complex Robot Instructions with Foundation Models
Feb 18, 2024
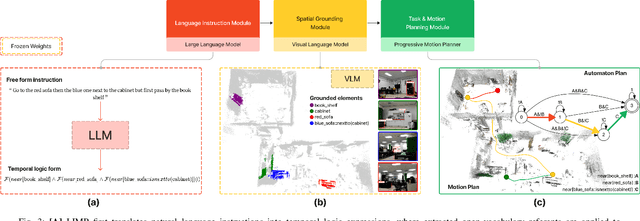


Enabling robots to follow complex natural language instructions is an important yet challenging problem. People want to flexibly express constraints, refer to arbitrary landmarks and verify behavior when instructing robots. Conversely, robots must disambiguate human instructions into specifications and ground instruction referents in the real world. We propose Language Instruction grounding for Motion Planning (LIMP), a system that leverages foundation models and temporal logics to generate instruction-conditioned semantic maps that enable robots to verifiably follow expressive and long-horizon instructions with open vocabulary referents and complex spatiotemporal constraints. In contrast to prior methods for using foundation models in robot task execution, LIMP constructs an explainable instruction representation that reveals the robot's alignment with an instructor's intended motives and affords the synthesis of robot behaviors that are correct-by-construction. We demonstrate LIMP in three real-world environments, across a set of 35 complex spatiotemporal instructions, showing the generality of our approach and the ease of deployment in novel unstructured domains. In our experiments, LIMP can spatially ground open-vocabulary referents and synthesize constraint-satisfying plans in 90% of object-goal navigation and 71% of mobile manipulation instructions. See supplementary videos at https://robotlimp.github.io
Exploiting Contextual Structure to Generate Useful Auxiliary Tasks
Mar 09, 2023Reinforcement learning requires interaction with an environment, which is expensive for robots. This constraint necessitates approaches that work with limited environmental interaction by maximizing the reuse of previous experiences. We propose an approach that maximizes experience reuse while learning to solve a given task by generating and simultaneously learning useful auxiliary tasks. To generate these tasks, we construct an abstract temporal logic representation of the given task and leverage large language models to generate context-aware object embeddings that facilitate object replacements. Counterfactual reasoning and off-policy methods allow us to simultaneously learn these auxiliary tasks while solving the given target task. We combine these insights into a novel framework for multitask reinforcement learning and experimentally show that our generated auxiliary tasks share similar underlying exploration requirements as the given task, thereby maximizing the utility of directed exploration. Our approach allows agents to automatically learn additional useful policies without extra environment interaction.
Affordable Modular Autonomous Vehicle Development Platform
Jun 20, 2020
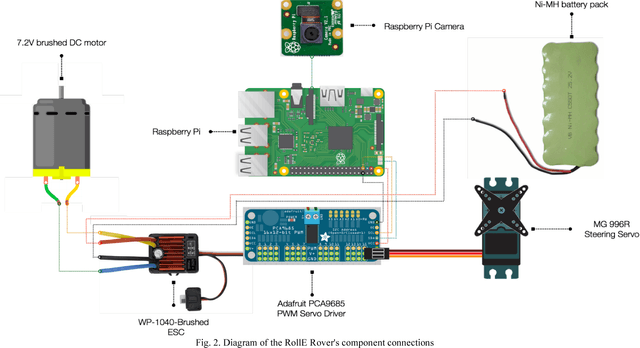
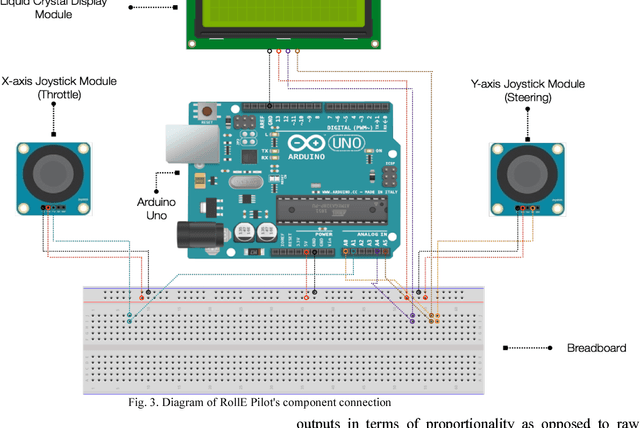

Road accidents are estimated to be the ninth leading cause of death across all age groups globally. 1.25 million people die annually from road accidents and Africa has the highest rate of road fatalities [1]. Research shows that three out of five road accidents are caused by driver-related behavioral factors [2]. Self-driving technology has the potential of saving lives lost to these preventable road accidents. Africa accounts for the majority of road fatalities and as such would benefit immensely from this technology. However, financial constraints prevent viable experimentation and research into self-driving technology in Africa. This paper describes the design of RollE, an affordable modular autonomous vehicle development platform. It is capable of driving via remote control for data collection and also capable of autonomous driving using a convolutional neural network. This system is aimed at providing students and researchers with an affordable autonomous vehicle to develop and test self-driving car technology.
* ICAST 2018