 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiably Following Complex Robot Instructions with Foundation Models
Paper and Code
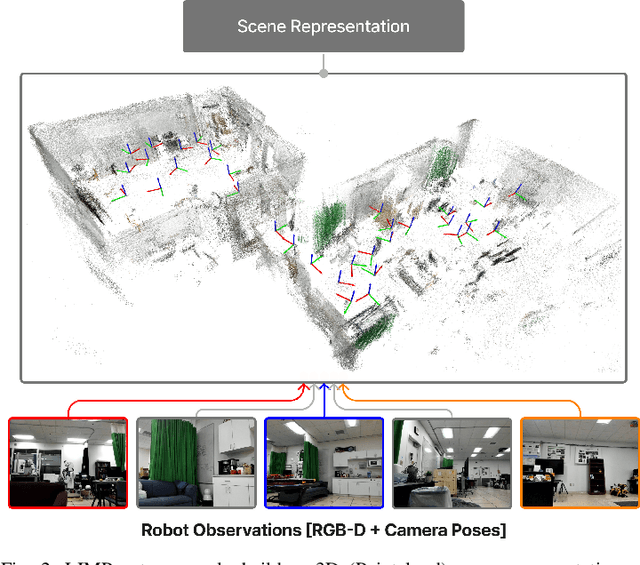
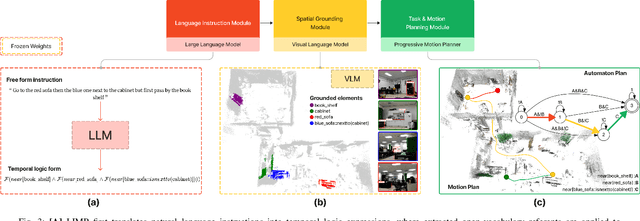


Enabling robots to follow complex natural language instructions is an important yet challenging problem. People want to flexibly express constraints, refer to arbitrary landmarks and verify behavior when instructing robots. Conversely, robots must disambiguate human instructions into specifications and ground instruction referents in the real world. We propose Language Instruction grounding for Motion Planning (LIMP), a system that leverages foundation models and temporal logics to generate instruction-conditioned semantic maps that enable robots to verifiably follow expressive and long-horizon instructions with open vocabulary referents and complex spatiotemporal constraints. In contrast to prior methods for using foundation models in robot task execution, LIMP constructs an explainable instruction representation that reveals the robot's alignment with an instructor's intended motives and affords the synthesis of robot behaviors that are correct-by-construction. We demonstrate LIMP in three real-world environments, across a set of 35 complex spatiotemporal instructions, showing the generality of our approach and the ease of deployment in novel unstructured domains. In our experiments, LIMP can spatially ground open-vocabulary referents and synthesize constraint-satisfying plans in 90% of object-goal navigation and 71% of mobile manipulation instructions. See supplementary videos at https://robotlimp.github.io