 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAM: Bi-level Memory-adaptive Algorithmic Evolution for LLM-Powered Heuristic Design
Apr 14, 2026Large Language Model-based Hyper Heuristic (LHH) has recently emerged as an efficient way for automatic heuristic design. However, most existing LHHs just perform well in optimizing a single function within a pre-defined solver. Their single-layer evolution makes them not effective enough to write a competent complete solver. While some variants incorporate hyperparameter tuning or attempt to generate complex code through iterative local modifications, they still lack a high-level algorithmic modeling, leading to limited exploration efficiency. To address this, we reformulate heuristic design as a Bi-level Optimization problem and propose \textbf{BEAM} (Bi-level Memory-adaptive Algorithmic Evolution). BEAM's exterior layer evolves high-level algorithmic structures with function placeholders through genetic algorithm (GA), while the interior layer realizes these placeholders via Monte Carlo Tree Search (MCTS). We further introduce an Adaptive Memory module to facilitate complex code generation. To support the evaluation for complex code generation, we point out the limitations of starting LHHs from scratch or from code templates and introduce a Knowledge Augmentation (KA) Pipeline. Experimental results on several optimization problems demonstrate that BEAM significantly outperforms existing LHHs, notably reducing the optimality gap by 37.84\% on aggregate in CVRP hybrid algorithm design. BEAM also designs a heuristic that outperforms SOTA Maximum Independent Set (MIS) solver KaMIS.
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
Deepfake Forensics Adapter: A Dual-Stream Network for Generalizable Deepfake Detection
Mar 02, 2026The rapid advancement of deepfake generation techniques poses significant threats to public safety and causes societal harm through the creation of highly realistic synthetic facial media. While existing detection methods demonstrate limitations in generalizing to emerging forgery patterns, this paper presents Deepfake Forensics Adapter (DFA), a novel dual-stream framework that synergizes vision-language foundation models with targeted forensics analysis. Our approach integrates a pre-trained CLIP model with three core components to achieve specialized deepfake detection by leveraging the powerful general capabilities of CLIP without changing CLIP parameters: 1) A Global Feature Adapter is used to identify global inconsistencies in image content that may indicate forgery, 2) A Local Anomaly Stream enhances the model's ability to perceive local facial forgery cues by explicitly leveraging facial structure priors, and 3) An Interactive Fusion Classifier promotes deep interaction and fusion between global and local features using a transformer encoder. Extensive evaluations of frame-level and video-level benchmarks demonstrate the superior generalization capabilities of DFA, particularly achieving state-of-the-art performance in the challenging DFDC dataset with frame-level AUC/EER of 0.816/0.256 and video-level AUC/EER of 0.836/0.251, representing a 4.8% video AUC improvement over previous methods. Our framework not only demonstrates state-of-the-art performance, but also points out a feasible and effective direction for developing a robust deepfake detection system with enhanced generalization capabilities against the evolving deepfake threats. Our code is available at https://github.com/Liao330/DFA.git
BrainCSD: A Hierarchical Consistency-Driven MoE Foundation Model for Unified Connectome Synthesis and Multitask Brain Trait Prediction
Nov 07, 2025Functional and structural connectivity (FC/SC) are key multimodal biomarkers for brain analysis, yet their clinical utility is hindered by costly acquisition, complex preprocessing, and frequent missing modalities. Existing foundation models either process single modalities or lack explicit mechanisms for cross-modal and cross-scale consistency. We propose BrainCSD, a hierarchical mixture-of-experts (MoE) foundation model that jointly synthesizes FC/SC biomarkers and supports downstream decoding tasks (diagnosis and prediction). BrainCSD features three neuroanatomically grounded components: (1) a ROI-specific MoE that aligns regional activations from canonical networks (e.g., DMN, FPN) with a global atlas via contrastive consistency; (2) a Encoding-Activation MOE that models dynamic cross-time/gradient dependencies in fMRI/dMRI; and (3) a network-aware refinement MoE that enforces structural priors and symmetry at individual and population levels. Evaluated on the datasets under complete and missing-modality settings, BrainCSD achieves SOTA results: 95.6\% accuracy for MCI vs. CN classification without FC, low synthesis error (FC RMSE: 0.038; SC RMSE: 0.006), brain age prediction (MAE: 4.04 years), and MMSE score estimation (MAE: 1.72 points). Code is available in \href{https://github.com/SXR3015/BrainCSD}{BrainCSD}
Pattern-Aware Diffusion Synthesis of fMRI/dMRI with Tissue and Microstructural Refinement
Nov 07, 2025Magnetic resonance imaging (MRI), especially functional MRI (fMRI) and diffusion MRI (dMRI), is essential for studying neurodegenerative diseases. However, missing modalities pose a major barrier to their clinical use. Although GAN- and diffusion model-based approaches have shown some promise in modality completion, they remain limited in fMRI-dMRI synthesis due to (1) significant BOLD vs. diffusion-weighted signal differences between fMRI and dMRI in time/gradient axis, and (2) inadequate integration of disease-related neuroanatomical patterns during generation. To address these challenges, we propose PDS, introducing two key innovations: (1) a pattern-aware dual-modal 3D diffusion framework for cross-modality learning, and (2) a tissue refinement network integrated with a efficient microstructure refinement to maintain structural fidelity and fine details. Evaluated on OASIS-3, ADNI, and in-house datasets, our method achieves state-of-the-art results, with PSNR/SSIM scores of 29.83 dB/90.84\% for fMRI synthesis (+1.54 dB/+4.12\% over baselines) and 30.00 dB/77.55\% for dMRI synthesis (+1.02 dB/+2.2\%). In clinical validation, the synthesized data show strong diagnostic performance, achieving 67.92\%/66.02\%/64.15\% accuracy (NC vs. MCI vs. AD) in hybrid real-synthetic experiments. Code is available in \href{https://github.com/SXR3015/PDS}{PDS GitHub Repository}
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

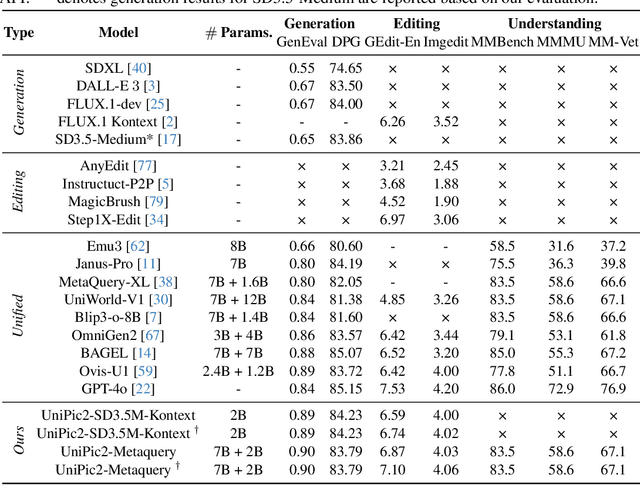
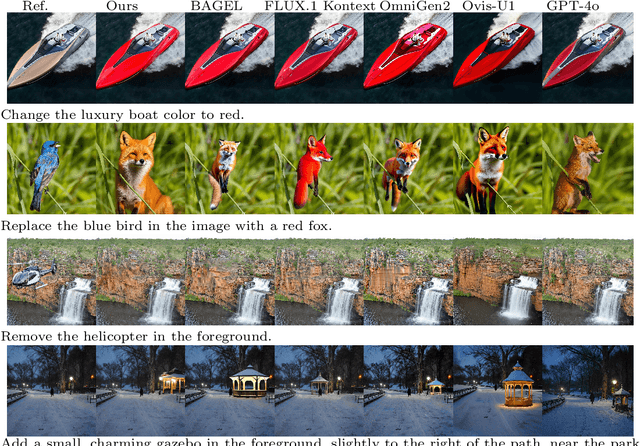
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
May 30, 2025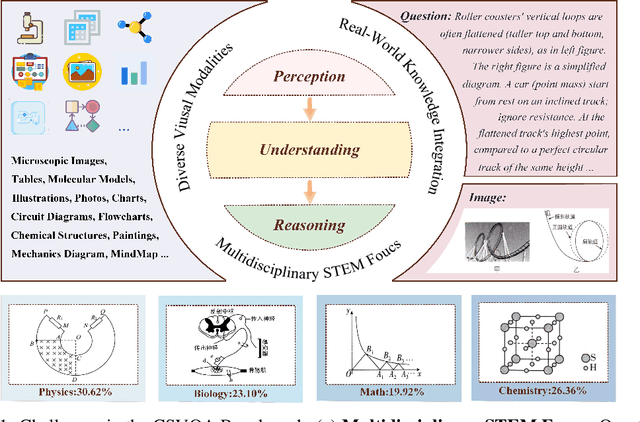
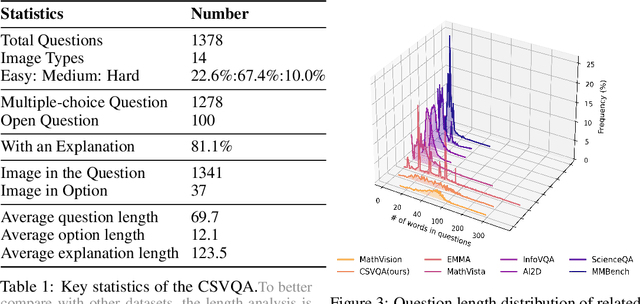
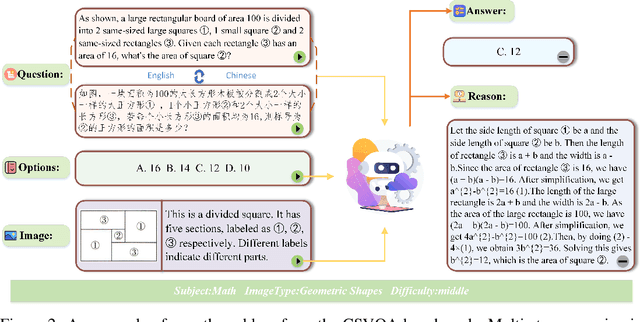
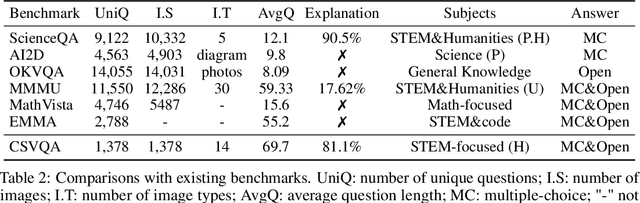
Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding, yet their capabilities for scientific reasoning remains inadequately assessed. Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. To fill this gap, we present CSVQA, a diagnostic multimodal benchmark specifically designed for evaluating scientific reasoning through domain-grounded visual question answering.Our benchmark features 1,378 carefully constructed question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to prior multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning.We additionally propose a rigorous evaluation protocol to systematically assess whether model predictions are substantiated by valid intermediate reasoning steps based on curated explanations. Our comprehensive evaluation of 15 VLMs on this benchmark reveals notable performance disparities, as even the top-ranked proprietary model attains only 49.6\% accuracy.This empirical evidence underscores the pressing need for advancing scientific reasoning capabilities in VLMs. Our CSVQA is released at https://huggingface.co/datasets/Skywork/CSVQA.
Beyond Task and Motion Planning: Hierarchical Robot Planning with General-Purpose Policies
Apr 24, 2025

Task and motion planning is a well-established approach for solving long-horizon robot planning problems. However, traditional methods assume that each task-level robot action, or skill, can be reduced to kinematic motion planning. In this work, we address the challenge of planning with both kinematic skills and closed-loop motor controllers that go beyond kinematic considerations. We propose a novel method that integrates these controllers into motion planning using Composable Interaction Primitives (CIPs), enabling the use of diverse, non-composable pre-learned skills in hierarchical robot planning. Toward validating our Task and Skill Planning (TASP) approach, we describe ongoing robot experiments in real-world scenarios designed to demonstrate how CIPs can allow a mobile manipulator robot to effectively combine motion planning with general-purpose skills to accomplish complex tasks.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.