 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary feature fusion network for tooth image segmentation
Sep 06, 2024



Tooth segmentation is a critical technology in the field of medical image segmentation, with applications ranging from orthodontic treatment to human body identification and dental pathology assessment. Despite the development of numerous tooth image segmentation models by researchers, a common shortcoming is the failure to account for the challenges of blurred tooth boundaries. Dental diagnostics require precise delineation of tooth boundaries. This paper introduces an innovative tooth segmentation network that integrates boundary information to address the issue of indistinct boundaries between teeth and adjacent tissues. This network's core is its boundary feature extraction module, which is designed to extract detailed boundary information from high-level features. Concurrently, the feature cross-fusion module merges detailed boundary and global semantic information in a synergistic way, allowing for stepwise layer transfer of feature information. This method results in precise tooth segmentation. In the most recent STS Data Challenge, our methodology was rigorously tested and received a commendable overall score of 0.91. When compared to other existing approaches, this score demonstrates our method's significant superiority in segmenting tooth boundaries.
Category Query Learning for Human-Object Interaction Classification
Mar 24, 2023
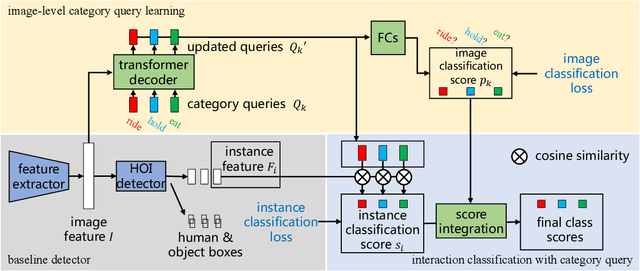
Unlike most previous HOI methods that focus on learning better human-object features, we propose a novel and complementary approach called category query learning. Such queries are explicitly associated to interaction categories, converted to image specific category representation via a transformer decoder, and learnt via an auxiliary image-level classification task. This idea is motivated by an earlier multi-label image classification method, but is for the first time applied for the challenging human-object interaction classification task. Our method is simple, general and effective. It is validated on three representative HOI baselines and achieves new state-of-the-art results on two benchmarks.
SOLQ: Segmenting Objects by Learning Queries
Jun 09, 2021



In this paper, we propose an end-to-end framework for instance segmentation. Based on the recently introduced DETR [1], our method, termed SOLQ, segments objects by learning unified queries. In SOLQ, each query represents one object and has multiple representations: class, location and mask. The object queries learned perform classification, box regression and mask encoding simultaneously in an unified vector form. During training phase, the mask vectors encoded are supervised by the compression coding of raw spatial masks. In inference time, mask vectors produced can be directly transformed to spatial masks by the inverse process of compression coding. Experimental results show that SOLQ can achieve state-of-the-art performance, surpassing most of existing approaches. Moreover, the joint learning of unified query representation can greatly improve the detection performance of original DETR. We hope our SOLQ can serve as a strong baseline for the Transformer-based instance segmentation. Code is available at https://github.com/megvii-research/SOLQ.
MOTR: End-to-End Multiple-Object Tracking with TRansformer
May 07, 2021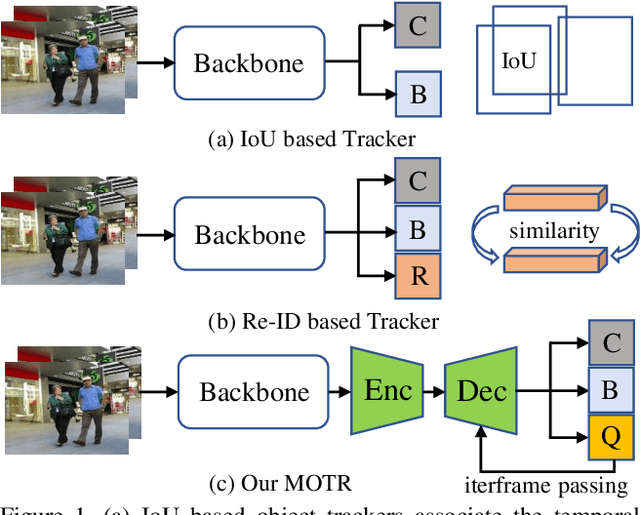



The key challenge in multiple-object tracking (MOT) task is temporal modeling of the object under track. Existing tracking-by-detection methods adopt simple heuristics, such as spatial or appearance similarity. Such methods, in spite of their commonality, are overly simple and insufficient to model complex variations, such as tracking through occlusion. Inherently, existing methods lack the ability to learn temporal variations from data. In this paper, we present MOTR, the first fully end-to-end multiple-object tracking framework. It learns to model the long-range temporal variation of the objects. It performs temporal association implicitly and avoids previous explicit heuristics. Built on Transformer and DETR, MOTR introduces the concept of "track query". Each track query models the entire track of an object. It is transferred and updated frame-by-frame to perform object detection and tracking, in a seamless manner. Temporal aggregation network combined with multi-frame training is proposed to model the long-range temporal relation. Experimental results show that MOTR achieves state-of-the-art performance. Code is available at https://github.com/megvii-model/MOTR.
Prime-Aware Adaptive Distillation
Aug 04, 2020
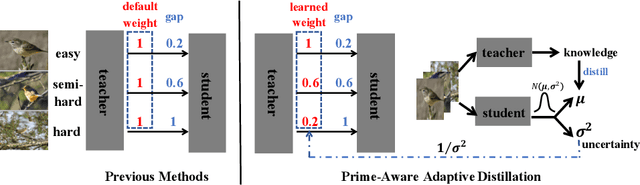
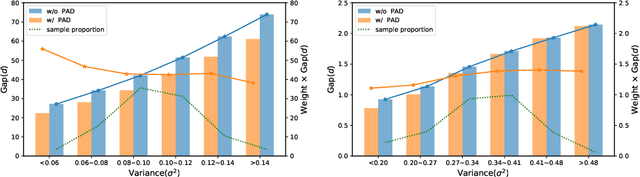

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.