 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSORCE: Small Object Retrieval in Complex Environments
May 30, 2025Text-to-Image Retrieval (T2IR) is a highly valuable task that aims to match a given textual query to images in a gallery. Existing benchmarks primarily focus on textual queries describing overall image semantics or foreground salient objects, possibly overlooking inconspicuous small objects, especially in complex environments. Such small object retrieval is crucial, as in real-world applications, the targets of interest are not always prominent in the image. Thus, we introduce SORCE (Small Object Retrieval in Complex Environments), a new subfield of T2IR, focusing on retrieving small objects in complex images with textual queries. We propose a new benchmark, SORCE-1K, consisting of images with complex environments and textual queries describing less conspicuous small objects with minimal contextual cues from other salient objects. Preliminary analysis on SORCE-1K finds that existing T2IR methods struggle to capture small objects and encode all the semantics into a single embedding, leading to poor retrieval performance on SORCE-1K. Therefore, we propose to represent each image with multiple distinctive embeddings. We leverage Multimodal Large Language Models (MLLMs) to extract multiple embeddings for each image instructed by a set of Regional Prompts (ReP). Experimental results show that our multi-embedding approach through MLLM and ReP significantly outperforms existing T2IR methods on SORCE-1K. Our experiments validate the effectiveness of SORCE-1K for benchmarking SORCE performances, highlighting the potential of multi-embedding representation and text-customized MLLM features for addressing this task.
On the Suitability of Reinforcement Fine-Tuning to Visual Tasks
Apr 08, 2025
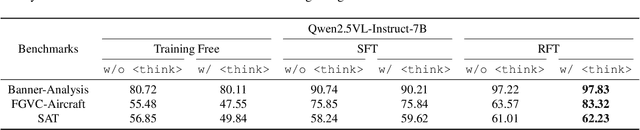
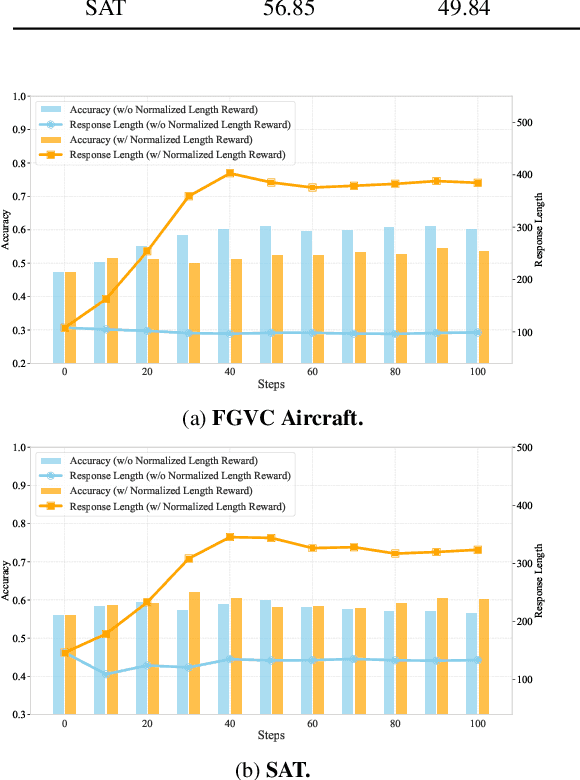
Reinforcement Fine-Tuning (RFT) is proved to be greatly valuable for enhancing the reasoning ability of LLMs. Researchers have been starting to apply RFT to MLLMs, hoping it will also enhance the capabilities of visual understanding. However, these works are at a very early stage and have not examined how suitable RFT actually is for visual tasks. In this work, we endeavor to understand the suitabilities and limitations of RFT for visual tasks, through experimental analysis and observations. We start by quantitative comparisons on various tasks, which shows RFT is generally better than SFT on visual tasks. %especially when the number of training samples are limited. To check whether such advantages are brought up by the reasoning process, we design a new reward that encourages the model to ``think'' more, whose results show more thinking can be beneficial for complicated tasks but harmful for simple tasks. We hope this study can provide more insight for the rapid advancements on this topic.
FocusLLaVA: A Coarse-to-Fine Approach for Efficient and Effective Visual Token Compression
Nov 21, 2024



Recent advances on Multi-modal Large Language Models have demonstrated that high-resolution image input is crucial for model capabilities, especially for fine-grained tasks. However, high-resolution images lead to a quadratic increase in the number of visual tokens input into LLMs, resulting in significant computational costs. Current work develop visual token compression methods to achieve efficiency improvements, often at the expense of performance. We argue that removing visual redundancy can simultaneously improve both efficiency and performance. We build a coarse-to-fine visual token compression method, with a vision-guided sampler for compressing redundant regions with low information density, and a text-guided sampler for selecting visual tokens that are strongly correlated with the user instructions.With these two modules, the proposed FocusLLaVA achieves improvements in both efficiency and performance. We validate the effectiveness of our approach on a wide range of evaluation datasets.
Compositional Learning in Transformer-Based Human-Object Interaction Detection
Aug 11, 2023Human-object interaction (HOI) detection is an important part of understanding human activities and visual scenes. The long-tailed distribution of labeled instances is a primary challenge in HOI detection, promoting research in few-shot and zero-shot learning. Inspired by the combinatorial nature of HOI triplets, some existing approaches adopt the idea of compositional learning, in which object and action features are learned individually and re-composed as new training samples. However, these methods follow the CNN-based two-stage paradigm with limited feature extraction ability, and often rely on auxiliary information for better performance. Without introducing any additional information, we creatively propose a transformer-based framework for compositional HOI learning. Human-object pair representations and interaction representations are re-composed across different HOI instances, which involves richer contextual information and promotes the generalization of knowledge. Experiments show our simple but effective method achieves state-of-the-art performance, especially on rare HOI classes.
Exposing the Troublemakers in Described Object Detection
Jul 24, 2023



Detecting objects based on language descriptions is a popular task that includes Open-Vocabulary object Detection (OVD) and Referring Expression Comprehension (REC). In this paper, we advance them to a more practical setting called Described Object Detection (DOD) by expanding category names to flexible language expressions for OVD and overcoming the limitation of REC to only grounding the pre-existing object. We establish the research foundation for DOD tasks by constructing a Description Detection Dataset ($D^3$), featuring flexible language expressions and annotating all described objects without omission. By evaluating previous SOTA methods on $D^3$, we find some troublemakers that fail current REC, OVD, and bi-functional methods. REC methods struggle with confidence scores, rejecting negative instances, and multi-target scenarios, while OVD methods face constraints with long and complex descriptions. Recent bi-functional methods also do not work well on DOD due to their separated training procedures and inference strategies for REC and OVD tasks. Building upon the aforementioned findings, we propose a baseline that largely improves REC methods by reconstructing the training data and introducing a binary classification sub-task, outperforming existing methods. Data and code is available at https://github.com/shikras/d-cube.
Category Query Learning for Human-Object Interaction Classification
Mar 24, 2023
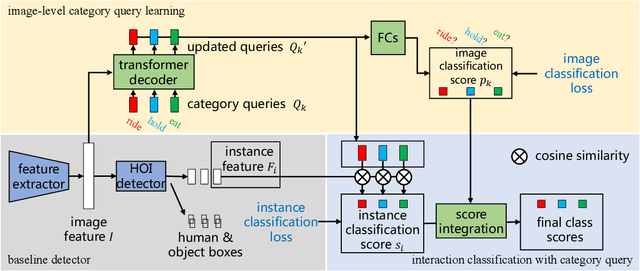
Unlike most previous HOI methods that focus on learning better human-object features, we propose a novel and complementary approach called category query learning. Such queries are explicitly associated to interaction categories, converted to image specific category representation via a transformer decoder, and learnt via an auxiliary image-level classification task. This idea is motivated by an earlier multi-label image classification method, but is for the first time applied for the challenging human-object interaction classification task. Our method is simple, general and effective. It is validated on three representative HOI baselines and achieves new state-of-the-art results on two benchmarks.