 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime-Aware Adaptive Distillation
Aug 04, 2020
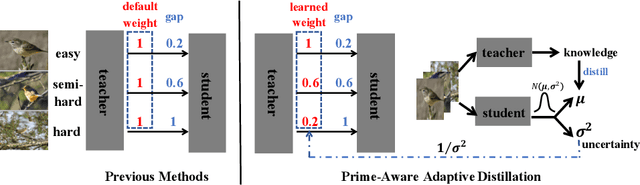
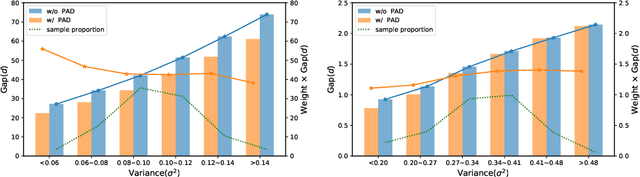

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.
Data Uncertainty Learning in Face Recognition
Mar 25, 2020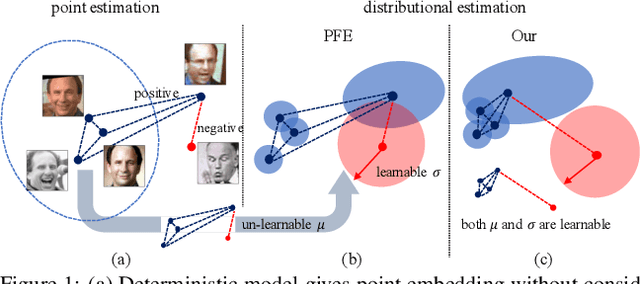
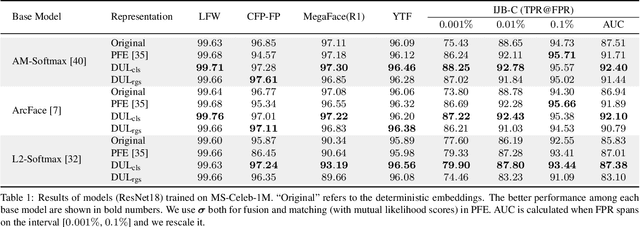

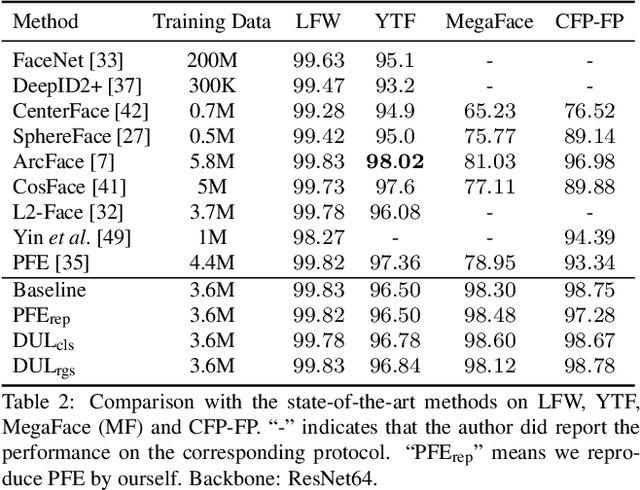
Modeling data uncertainty is important for noisy images, but seldom explored for face recognition. The pioneer work, PFE, considers uncertainty by modeling each face image embedding as a Gaussian distribution. It is quite effective. However, it uses fixed feature (mean of the Gaussian) from an existing model. It only estimates the variance and relies on an ad-hoc and costly metric. Thus, it is not easy to use. It is unclear how uncertainty affects feature learning. This work applies data uncertainty learning to face recognition, such that the feature (mean) and uncertainty (variance) are learnt simultaneously, for the first time. Two learning methods are proposed. They are easy to use and outperform existing deterministic methods as well as PFE on challenging unconstrained scenarios. We also provide insightful analysis on how incorporating uncertainty estimation helps reducing the adverse effects of noisy samples and affects the feature learning.