 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
Mar 16, 2026Recent advancements extend Multimodal Large Language Models (MLLMs) beyond standard visual question answering to utilizing external tools for advanced visual tasks. Despite this progress, precisely executing and effectively composing diverse tools for complex tasks remain persistent bottleneck. Constrained by sparse tool-sets and simple tool-use trajectories, existing benchmarks fail to capture complex and diverse tool interactions, falling short in evaluating model performance under practical, real-world conditions. To bridge this gap, we introduce VisualToolChain-Bench~(VTC-Bench), a comprehensive benchmark designed to evaluate tool-use proficiency in MLLMs. To align with realistic computer vision pipelines, our framework features 32 diverse OpenCV-based visual operations. This rich tool-set enables extensive combinations, allowing VTC-Bench to rigorously assess multi-tool composition and long-horizon, multi-step plan execution. For precise evaluation, we provide 680 curated problems structured across a nine-category cognitive hierarchy, each with ground-truth execution trajectories. Extensive experiments on 19 leading MLLMs reveal critical limitations in current models' visual agentic capabilities. Specifically, models struggle to adapt to diverse tool-sets and generalize to unseen operations, with the leading model Gemini-3.0-Pro only achieving 51\% on our benchmark. Furthermore, multi-tool composition remains a persistent challenge. When facing complex tasks, models struggle to formulate efficient execution plans, relying heavily on a narrow, suboptimal subset of familiar functions rather than selecting the optimal tools. By identifying these fundamental challenges, VTC-Bench establishes a rigorous baseline to guide the development of more generalized visual agentic models.
Scalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
GLRD: Global-Local Collaborative Reason and Debate with PSL for 3D Open-Vocabulary Detection
Mar 26, 2025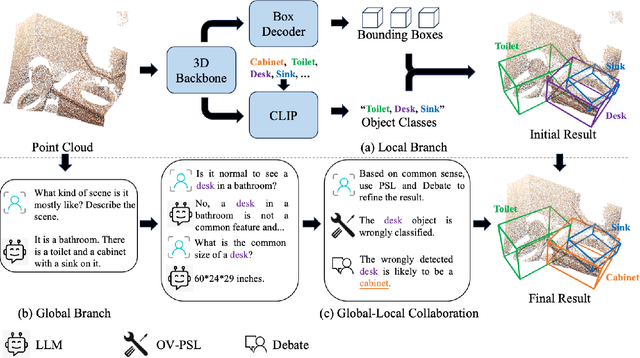
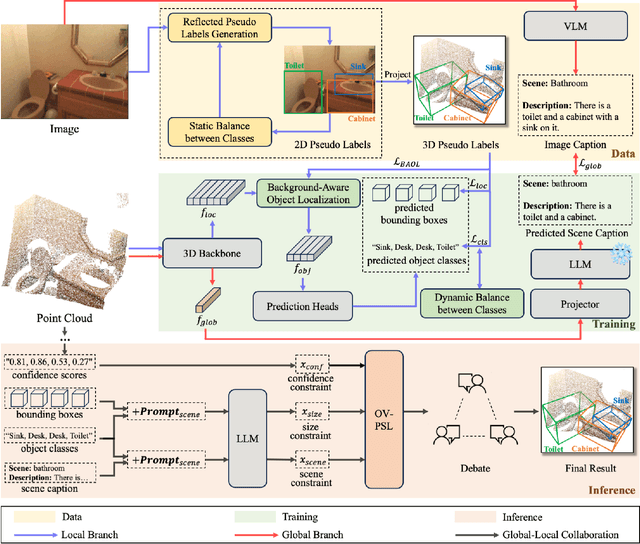
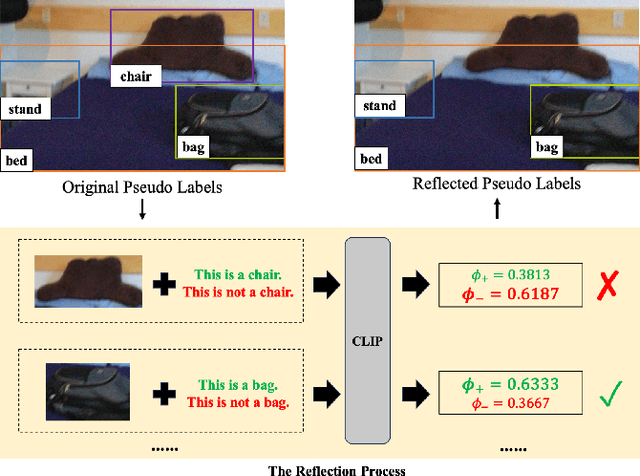
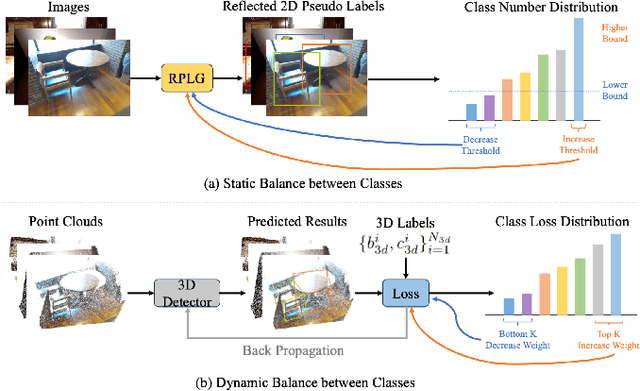
The task of LiDAR-based 3D Open-Vocabulary Detection (3D OVD) requires the detector to learn to detect novel objects from point clouds without off-the-shelf training labels. Previous methods focus on the learning of object-level representations and ignore the scene-level information, thus it is hard to distinguish objects with similar classes. In this work, we propose a Global-Local Collaborative Reason and Debate with PSL (GLRD) framework for the 3D OVD task, considering both local object-level information and global scene-level information. Specifically, LLM is utilized to perform common sense reasoning based on object-level and scene-level information, where the detection result is refined accordingly. To further boost the LLM's ability of precise decisions, we also design a probabilistic soft logic solver (OV-PSL) to search for the optimal solution, and a debate scheme to confirm the class of confusable objects. In addition, to alleviate the uneven distribution of classes, a static balance scheme (SBC) and a dynamic balance scheme (DBC) are designed. In addition, to reduce the influence of noise in data and training, we further propose Reflected Pseudo Labels Generation (RPLG) and Background-Aware Object Localization (BAOL). Extensive experiments conducted on ScanNet and SUN RGB-D demonstrate the superiority of GLRD, where absolute improvements in mean average precision are $+2.82\%$ on SUN RGB-D and $+3.72\%$ on ScanNet in the partial open-vocabulary setting. In the full open-vocabulary setting, the absolute improvements in mean average precision are $+4.03\%$ on ScanNet and $+14.11\%$ on SUN RGB-D.
Training Video Foundation Models with NVIDIA NeMo
Mar 17, 2025Video Foundation Models (VFMs) have recently been used to simulate the real world to train physical AI systems and develop creative visual experiences. However, there are significant challenges in training large-scale, high quality VFMs that can generate high-quality videos. We present a scalable, open-source VFM training pipeline with NVIDIA NeMo, providing accelerated video dataset curation, multimodal data loading, and parallelized video diffusion model training and inference. We also provide a comprehensive performance analysis highlighting best practices for efficient VFM training and inference.
Global-Local Collaborative Inference with LLM for Lidar-Based Open-Vocabulary Detection
Jul 12, 2024Open-Vocabulary Detection (OVD) is the task of detecting all interesting objects in a given scene without predefined object classes. Extensive work has been done to deal with the OVD for 2D RGB images, but the exploration of 3D OVD is still limited. Intuitively, lidar point clouds provide 3D information, both object level and scene level, to generate trustful detection results. However, previous lidar-based OVD methods only focus on the usage of object-level features, ignoring the essence of scene-level information. In this paper, we propose a Global-Local Collaborative Scheme (GLIS) for the lidar-based OVD task, which contains a local branch to generate object-level detection result and a global branch to obtain scene-level global feature. With the global-local information, a Large Language Model (LLM) is applied for chain-of-thought inference, and the detection result can be refined accordingly. We further propose Reflected Pseudo Labels Generation (RPLG) to generate high-quality pseudo labels for supervision and Background-Aware Object Localization (BAOL) to select precise object proposals. Extensive experiments on ScanNetV2 and SUN RGB-D demonstrate the superiority of our methods. Code is released at https://github.com/GradiusTwinbee/GLIS.
Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
Dec 08, 2022



Continual Test-Time Adaptation (CTTA) aims to adapt the source model to continually changing unlabeled target domains without access to the source data. Existing methods mainly focus on model-based adaptation in a self-training manner, such as predicting pseudo labels for new domain datasets. Since pseudo labels are noisy and unreliable, these methods suffer from catastrophic forgetting and error accumulation when dealing with dynamic data distributions. Motivated by the prompt learning in NLP, in this paper, we propose to learn an image-level visual domain prompt for target domains while having the source model parameters frozen. During testing, the changing target datasets can be adapted to the source model by reformulating the input data with the learned visual prompts. Specifically, we devise two types of prompts, i.e., domains-specific prompts and domains-agnostic prompts, to extract current domain knowledge and maintain the domain-shared knowledge in the continual adaptation. Furthermore, we design a homeostasis-based prompt adaptation strategy to suppress domain-sensitive parameters in domain-invariant prompts to learn domain-shared knowledge more effectively. This transition from the model-dependent paradigm to the model-free one enables us to bypass the catastrophic forgetting and error accumulation problems. Experiments show that our proposed method achieves significant performance gains over state-of-the-art methods on four widely-used benchmarks, including CIFAR-10C, CIFAR-100C, ImageNet-C, and VLCS datasets.
Trusted Multi-Scale Classification Framework for Whole Slide Image
Jul 12, 2022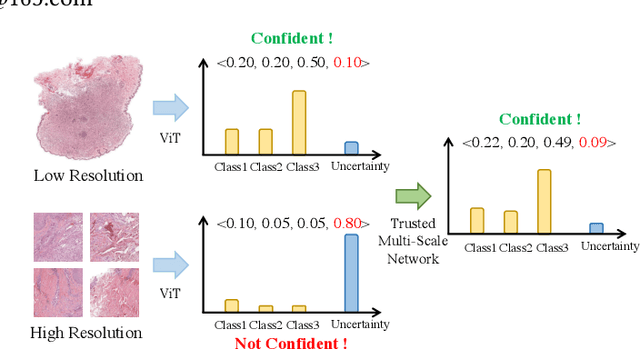


Despite remarkable efforts been made, the classification of gigapixels whole-slide image (WSI) is severely restrained from either the constrained computing resources for the whole slides, or limited utilizing of the knowledge from different scales. Moreover, most of the previous attempts lacked of the ability of uncertainty estimation. Generally, the pathologists often jointly analyze WSI from the different magnifications. If the pathologists are uncertain by using single magnification, then they will change the magnification repeatedly to discover various features of the tissues. Motivated by the diagnose process of the pathologists, in this paper, we propose a trusted multi-scale classification framework for the WSI. Leveraging the Vision Transformer as the backbone for multi branches, our framework can jointly classification modeling, estimating the uncertainty of each magnification of a microscope and integrate the evidence from different magnification. Moreover, to exploit discriminative patches from WSIs and reduce the requirement for computation resources, we propose a novel patch selection schema using attention rollout and non-maximum suppression. To empirically investigate the effectiveness of our approach, empirical experiments are conducted on our WSI classification tasks, using two benchmark databases. The obtained results suggest that the trusted framework can significantly improve the WSI classification performance compared with the state-of-the-art methods.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022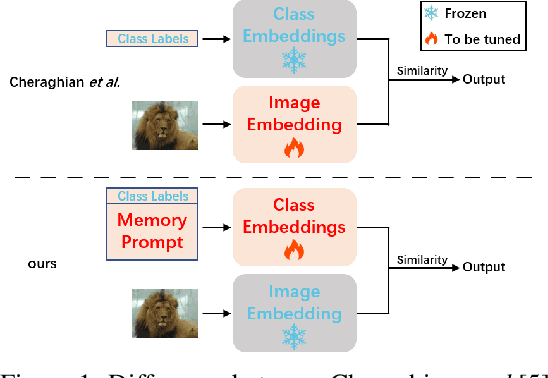
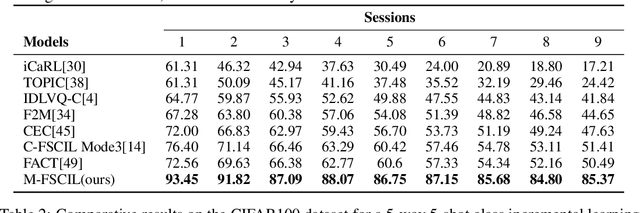
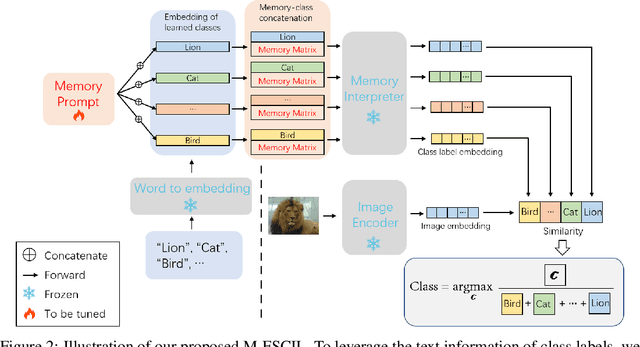
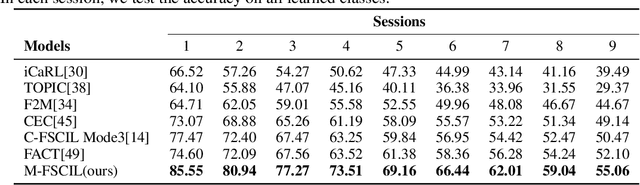
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Switchable Representation Learning Framework with Self-compatibility
Jun 16, 2022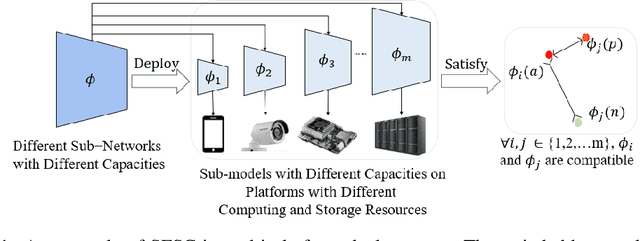

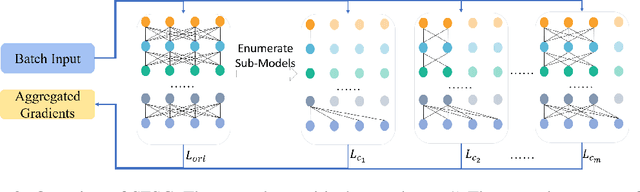
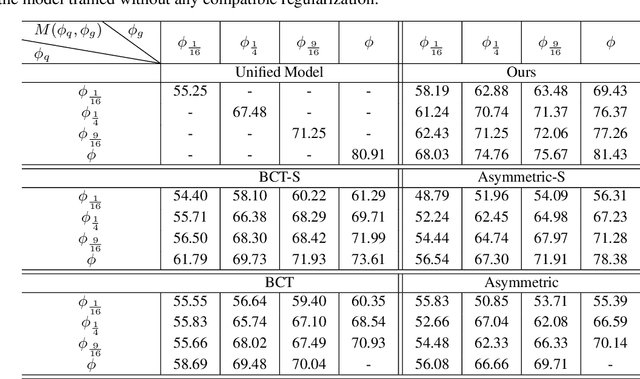
Real-world visual search systems involve deployments on multiple platforms with different computing and storage resources. Deploying a unified model that suits the minimal-constrain platforms leads to limited accuracy. It is expected to deploy models with different capacities adapting to the resource constraints, which requires features extracted by these models to be aligned in the metric space. The method to achieve feature alignments is called "compatible learning". Existing research mainly focuses on the one-to-one compatible paradigm, which is limited in learning compatibility among multiple models. We propose a Switchable representation learning Framework with Self-Compatibility (SFSC). SFSC generates a series of compatible sub-models with different capacities through one training process. The optimization of sub-models faces gradients conflict, and we mitigate it from the perspective of the magnitude and direction. We adjust the priorities of sub-models dynamically through uncertainty estimation to co-optimize sub-models properly. Besides, the gradients with conflicting directions are projected to avoid mutual interference. SFSC achieves state-of-art performance on the evaluated dataset.
Neighborhood Consensus Contrastive Learning for Backward-Compatible Representation
Sep 09, 2021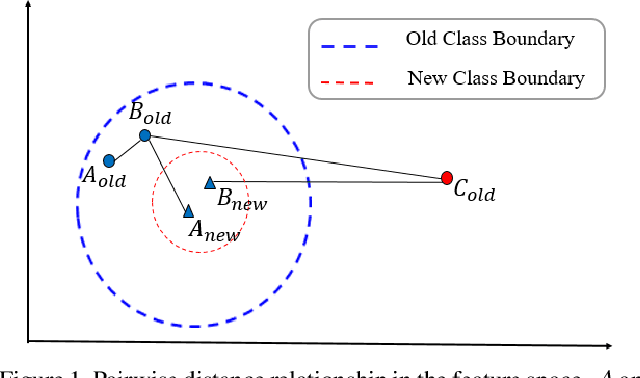
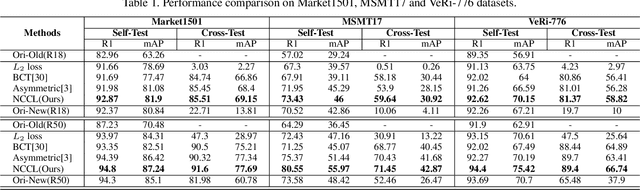
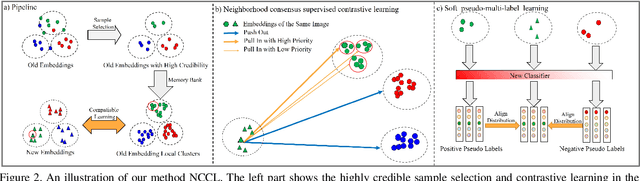
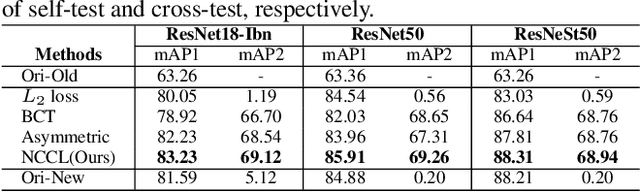
In object re-identification (ReID), the development of deep learning techniques often involves model updates and deployment. It is unbearable to re-embedding and re-index with the system suspended when deploying new models. Therefore, backward-compatible representation is proposed to enable "new" features to be compared with "old" features directly, which means that the database is active when there are both "new" and "old" features in it. Thus we can scroll-refresh the database or even do nothing on the database to update. The existing backward-compatible methods either require a strong overlap between old and new training data or simply conduct constraints at the instance level. Thus they are difficult in handling complicated cluster structures and are limited in eliminating the impact of outliers in old embeddings, resulting in a risk of damaging the discriminative capability of new features. In this work, we propose a Neighborhood Consensus Contrastive Learning (NCCL) method. With no assumptions about the new training data, we estimate the sub-cluster structures of old embeddings. A new embedding is constrained with multiple old embeddings in both embedding space and discrimination space at the sub-class level. The effect of outliers diminished, as the multiple samples serve as "mean teachers". Besides, we also propose a scheme to filter the old embeddings with low credibility, further improving the compatibility robustness. Our method ensures backward compatibility without impairing the accuracy of the new model. And it can even improve the new model's accuracy in most scenarios.