 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing
Jun 20, 2024Enhancing diverse human decision-making processes in an urban environment is a critical issue across various applications, including ride-sharing vehicle dispatching, public transportation management, and autonomous driving. Offline reinforcement learning (RL) is a promising approach to learn and optimize human urban strategies (or policies) from pre-collected human-generated spatial-temporal urban data. However, standard offline RL faces two significant challenges: (1) data scarcity and data heterogeneity, and (2) distributional shift. In this paper, we introduce MODA -- a Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing approach. MODA addresses the challenges of data scarcity and heterogeneity in a multi-task urban setting through Contrastive Data Sharing among tasks. This technique involves extracting latent representations of human behaviors by contrasting positive and negative data pairs. It then shares data presenting similar representations with the target task, facilitating data augmentation for each task. Moreover, MODA develops a novel model-based multi-task offline RL algorithm. This algorithm constructs a robust Markov Decision Process (MDP) by integrating a dynamics model with a Generative Adversarial Network (GAN). Once the robust MDP is established, any online RL or planning algorithm can be applied. Extensive experiments conducted in a real-world multi-task urban setting validate the effectiveness of MODA. The results demonstrate that MODA exhibits significant improvements compared to state-of-the-art baselines, showcasing its capability in advancing urban decision-making processes. We also made our code available to the research community.
Broadband Digital Over-the-Air Computation for Wireless Federated Edge Learning
Dec 13, 2022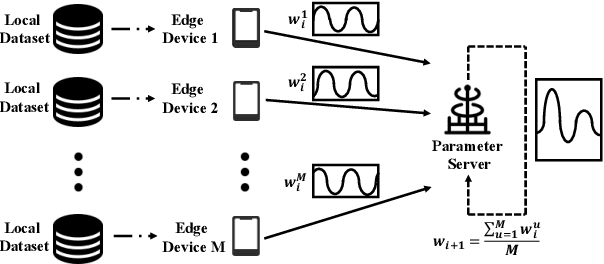
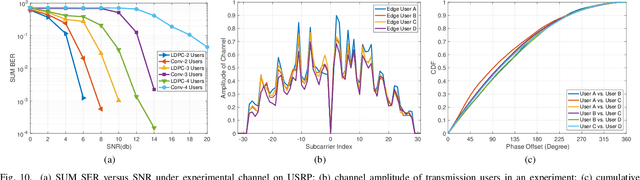
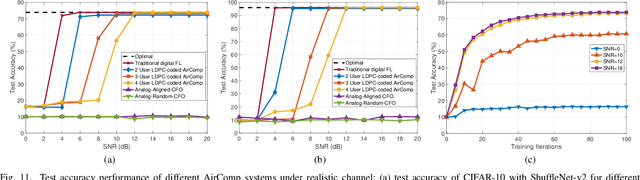
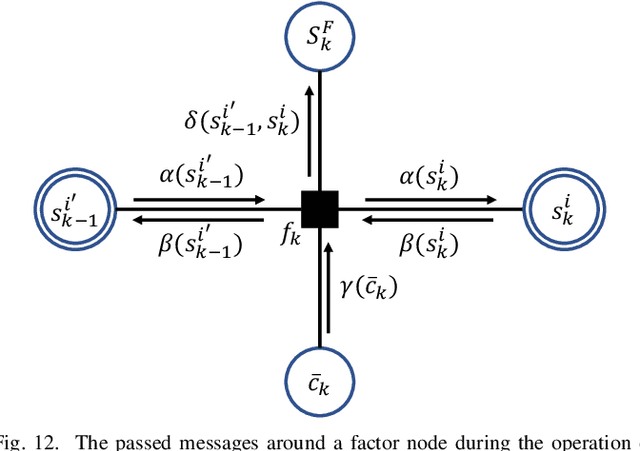
This paper presents the first orthogonal frequency-division multiplexing(OFDM)-based digital over-the-air computation (AirComp) system for wireless federated edge learning, where multiple edge devices transmit model data simultaneously using non-orthogonal wireless resources, and the edge server aggregates data directly from the superimposed signal. Existing analog AirComp systems often assume perfect phase alignment via channel precoding and utilize uncoded analog transmission for model aggregation. In contrast, our digital AirComp system leverages digital modulation and channel codes to overcome phase asynchrony, thereby achieving accurate model aggregation for phase-asynchronous multi-user OFDM systems. To realize a digital AirComp system, we develop a medium access control (MAC) protocol that allows simultaneous transmissions from different users using non-orthogonal OFDM subcarriers, and put forth joint channel decoding and aggregation decoders tailored for convolutional and LDPC codes. To verify the proposed system design, we build a digital AirComp prototype on the USRP software-defined radio platform, and demonstrate a real-time LDPC-coded AirComp system with up to four users. Trace-driven simulation results on test accuracy versus SNR show that: 1) analog AirComp is sensitive to phase asynchrony in practical multi-user OFDM systems, and the test accuracy performance fails to improve even at high SNRs; 2) our digital AirComp system outperforms two analog AirComp systems at all SNRs, and approaches the optimal performance when SNR $\geq$ 6 dB for two-user LDPC-coded AirComp, demonstrating the advantage of digital AirComp in phase-asynchronous multi-user OFDM systems.
A Benchmark for Gait Recognition under Occlusion Collected by Multi-Kinect SDAS
Jul 19, 2021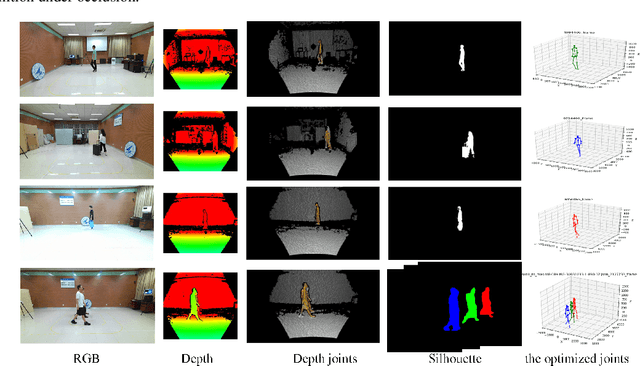
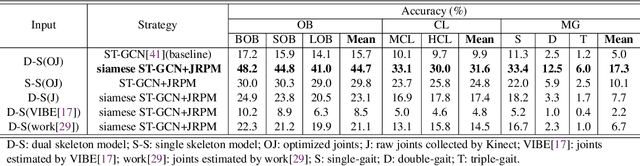
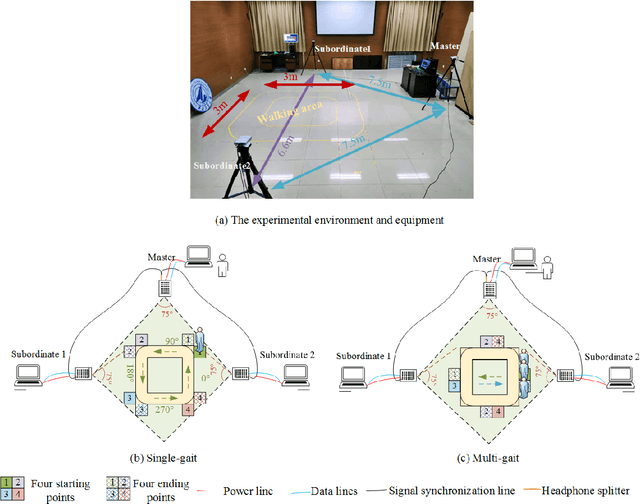
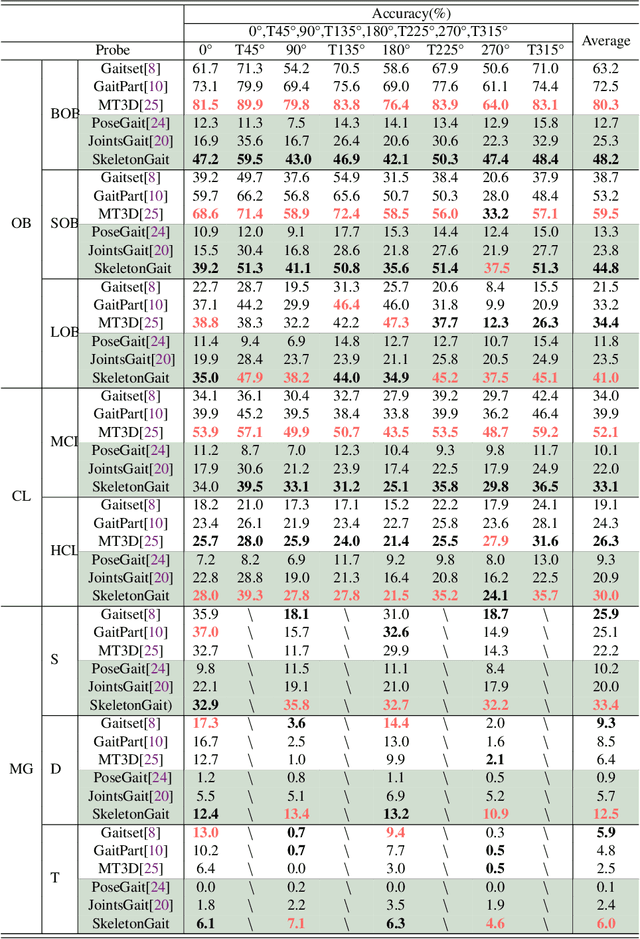
Human gait is one of important biometric characteristics for human identification at a distance. In practice, occlusion usually occurs and seriously affects accuracy of gait recognition. However, there is no available database to support in-depth research of this problem, and state-of-arts gait recognition methods have not paid enough attention to it, thus this paper focuses on gait recognition under occlusion. We collect a new gait recognition database called OG RGB+D database, which breaks through the limitation of other gait databases and includes multimodal gait data of various occlusions (self-occlusion, active occlusion, and passive occlusion) by our multiple synchronous Azure Kinect DK sensors data acquisition system (multi-Kinect SDAS) that can be also applied in security situations. Because Azure Kinect DK can simultaneously collect multimodal data to support different types of gait recognition algorithms, especially enables us to effectively obtain camera-centric multi-person 3D poses, and multi-view is better to deal with occlusion than single-view. In particular, the OG RGB+D database provides accurate silhouettes and the optimized human 3D joints data (OJ) by fusing data collected by multi-Kinects which are more accurate in human pose representation under occlusion. We also use the OJ data to train an advanced 3D multi-person pose estimation model to improve its accuracy of pose estimation under occlusion for universality. Besides, as human pose is less sensitive to occlusion than human appearance, we propose a novel gait recognition method SkeletonGait based on human dual skeleton model using a framework of siamese spatio-temporal graph convolutional networks (siamese ST-GCN). The evaluation results demonstrate that SkeletonGait has competitive performance compared with state-of-art gait recognition methods on OG RGB+D database and popular CAISA-B database.
Large-Scale Unsupervised Person Re-Identification with Contrastive Learning
May 17, 2021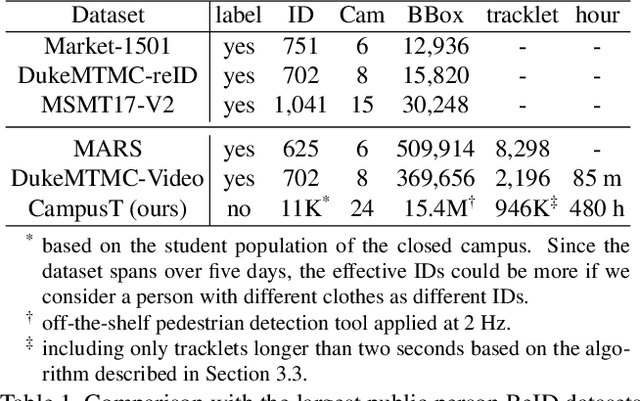
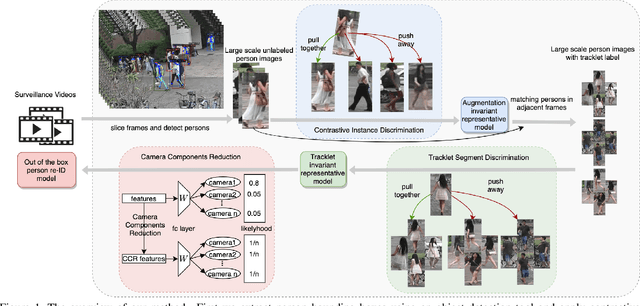

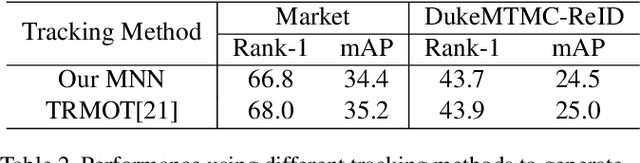
Existing public person Re-Identification~(ReID) datasets are small in modern terms because of labeling difficulty. Although unlabeled surveillance video is abundant and relatively easy to obtain, it is unclear how to leverage these footage to learn meaningful ReID representations. In particular, most existing unsupervised and domain adaptation ReID methods utilize only the public datasets in their experiments, with labels removed. In addition, due to small data sizes, these methods usually rely on fine tuning by the unlabeled training data in the testing domain to achieve good performance. Inspired by the recent progress of large-scale self-supervised image classification using contrastive learning, we propose to learn ReID representation from large-scale unlabeled surveillance video alone. Assisted by off-the-shelf pedestrian detection tools, we apply the contrastive loss at both the image and the tracklet levels. Together with a principal component analysis step using camera labels freely available, our evaluation using a large-scale unlabeled dataset shows far superior performance among unsupervised methods that do not use any training data in the testing domain. Furthermore, the accuracy improves with the data size and therefore our method has great potential with even larger and more diversified datasets.
Dynamic Image Restoration and Fusion Based on Dynamic Degradation
Apr 30, 2021
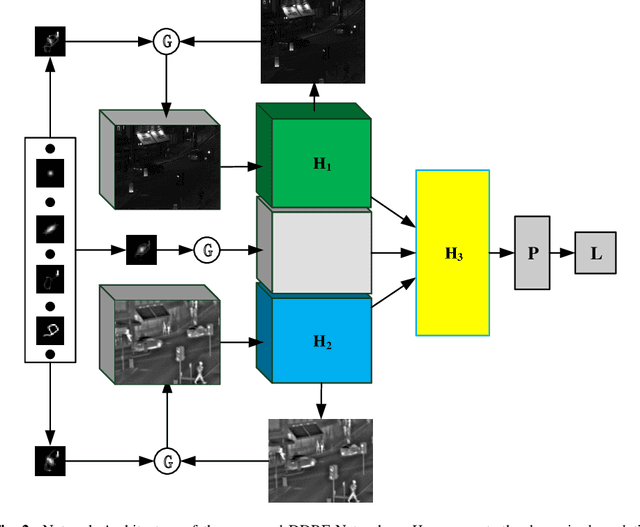


The deep-learning-based image restoration and fusion methods have achieved remarkable results. However, the existing restoration and fusion methods paid little research attention to the robustness problem caused by dynamic degradation. In this paper, we propose a novel dynamic image restoration and fusion neural network, termed as DDRF-Net, which is capable of solving two problems, i.e., static restoration and fusion, dynamic degradation. In order to solve the static fusion problem of existing methods, dynamic convolution is introduced to learn dynamic restoration and fusion weights. In addition, a dynamic degradation kernel is proposed to improve the robustness of image restoration and fusion. Our network framework can effectively combine image degradation with image fusion tasks, provide more detailed information for image fusion tasks through image restoration loss, and optimize image restoration tasks through image fusion loss. Therefore, the stumbling blocks of deep learning in image fusion, e.g., static fusion weight and specifically designed network architecture, are greatly mitigated. Extensive experiments show that our method is more superior compared with the state-of-the-art methods.
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 06, 2020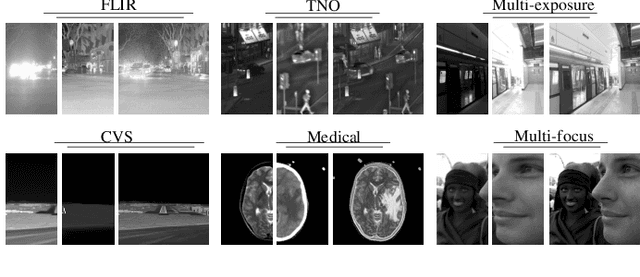
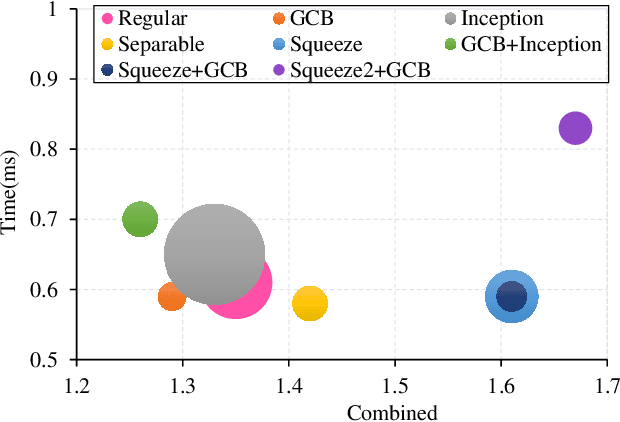

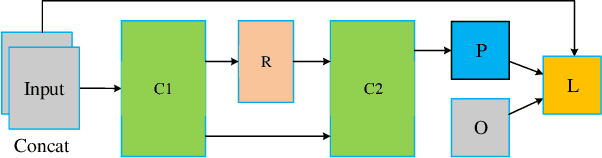
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
AE-Net: Autonomous Evolution Image Fusion Method Inspired by Human Cognitive Mechanism
Jul 17, 2020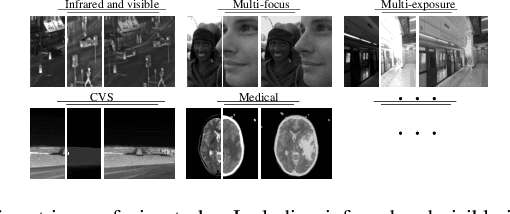
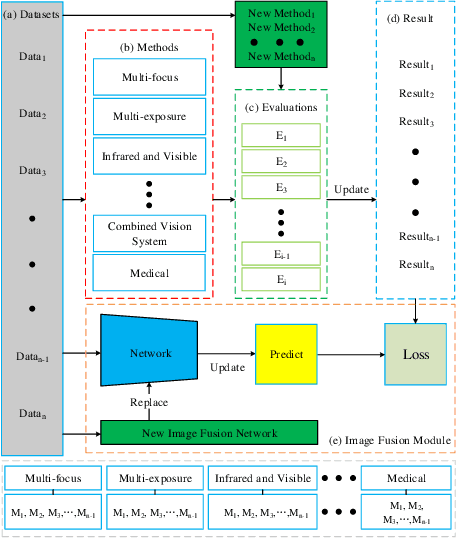

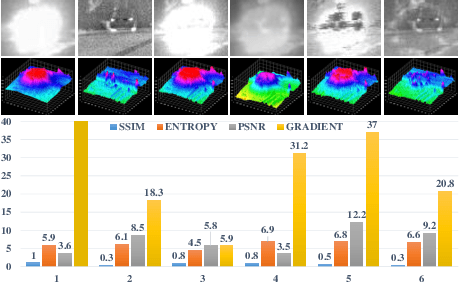
In order to solve the robustness and generality problems of the image fusion task,inspired by the human brain cognitive mechanism, we propose a robust and general image fusion method with autonomous evolution ability, and is therefore denoted with AE-Net. Through the collaborative optimization of multiple image fusion methods to simulate the cognitive process of human brain, unsupervised learning image fusion task can be transformed into semi-supervised image fusion task or supervised image fusion task, thus promoting the evolutionary ability of network model weight. Firstly, the relationship between human brain cognitive mechanism and image fusion task is analyzed and a physical model is established to simulate human brain cognitive mechanism. Secondly, we analyze existing image fusion methods and image fusion loss functions, select the image fusion method with complementary features to construct the algorithm module, establish the multi-loss joint evaluation function to obtain the optimal solution of algorithm module. The optimal solution of each image is used to guide the weight training of network model. Our image fusion method can effectively unify the cross-modal image fusion task and the same modal image fusion task, and effectively overcome the difference of data distribution between different datasets. Finally, extensive numerical results verify the effectiveness and superiority of our method on a variety of image fusion datasets, including multi-focus dataset, infrared and visi-ble dataset, medical image dataset and multi-exposure dataset. Comprehensive experiments demonstrate the superiority of our image fusion method in robustness and generality. In addition, experimental results also demonstate the effectiveness of human brain cognitive mechanism to improve the robustness and generality of image fusion.
A model-based Gait Recognition Method based on Gait Graph Convolutional Networks and Joints Relationship Pyramid Mapping
Apr 27, 2020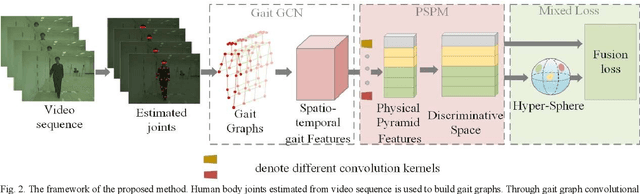
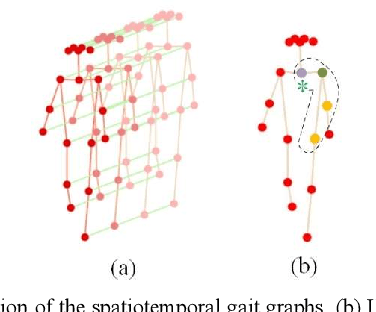
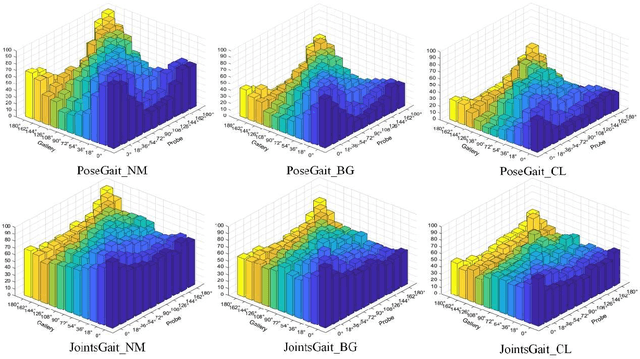
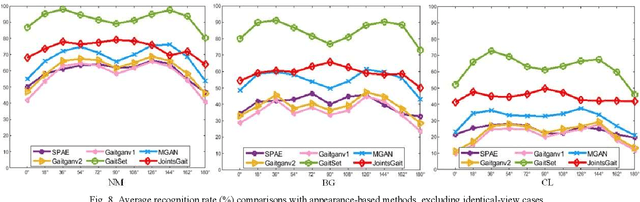
Gait, as a unique biometric feature that can be recognized at a distance, which can be widely applicated in public security. In this paper, we propose a novel model-based gait recognition method, JointsGait, which extracts gait information from human body joints. Early gait recognition methods are mainly based on appearance. The appearance-based features are usually extracted from human body silhouettes, which is not invariant to changes in clothing, and can be subject to drastic variations, due to camera motion or other external factors. In contrast to previous approaches, JointsGait firstly extracted spatio-temporal features using gait graph convolutional networks constructed by 18 2-D joints, which are less interfered by external factors. Then Joints Relationship Pyramid Mapping (JRPM) are proposed to map spatio-temporal gait features into a discriminative feature space with biological advantages according to physical structure and walking habit at various scales. Finally, we research a fusion loss strategy to help the joints features be insensitive to cross-view. Our method is evaluated on large datasets CASIA B. The experimental results show that JointsGait achieves the state-of-art performance, which is less affected by the view variations. Its recognition accuracy is higher than lasted model-based method PoseGait in all walking conditions, even outperforms most of state-of-art appearance-based methods, especially when there is a clothing variation.
A Robust Non-Linear and Feature-Selection Image Fusion Theory
Dec 23, 2019
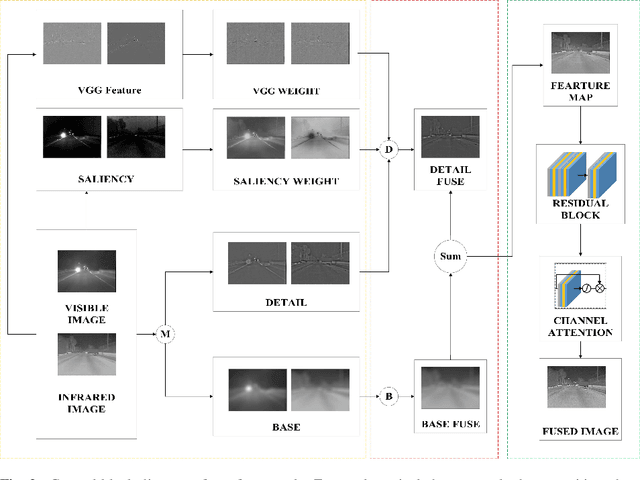

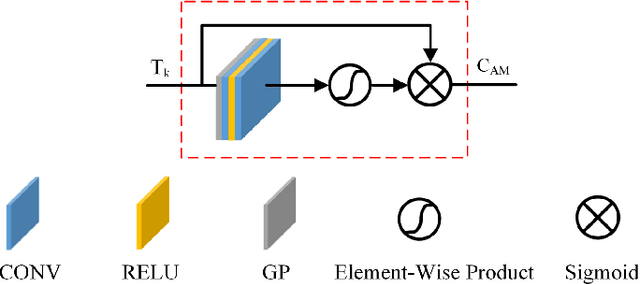
The human visual perception system has strong robustness in image fusion. This robustness is based on human visual perception system's characteristics of feature selection and non-linear fusion of different features. In order to simulate the human visual perception mechanism in image fusion tasks, we propose a multi-source image fusion framework that combines illuminance factors and attention mechanisms. The framework effectively combines traditional image features and modern deep learning features. First, we perform multi-scale decomposition of multi-source images. Then, the visual saliency map and the deep feature map are combined with the illuminance fusion factor to perform high-low frequency nonlinear fusion. Secondly, the characteristics of high and low frequency fusion are selected through the channel attention network to obtain the final fusion map. By simulating the nonlinear characteristics and selection characteristics of the human visual perception system in image fusion, the fused image is more in line with the human visual perception mechanism. Finally, we validate our fusion framework on public datasets of infrared and visible images, medical images and multi-focus images. The experimental results demonstrate the superiority of our fusion framework over state-of-arts in visual quality, objective fusion metrics and robustness.
A Cross-Modal Image Fusion Theory Guided by Human Visual Characteristics
Dec 23, 2019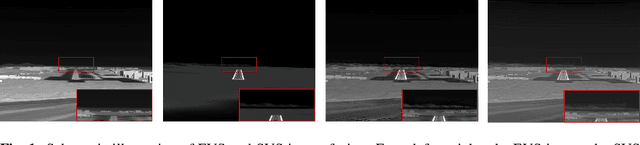
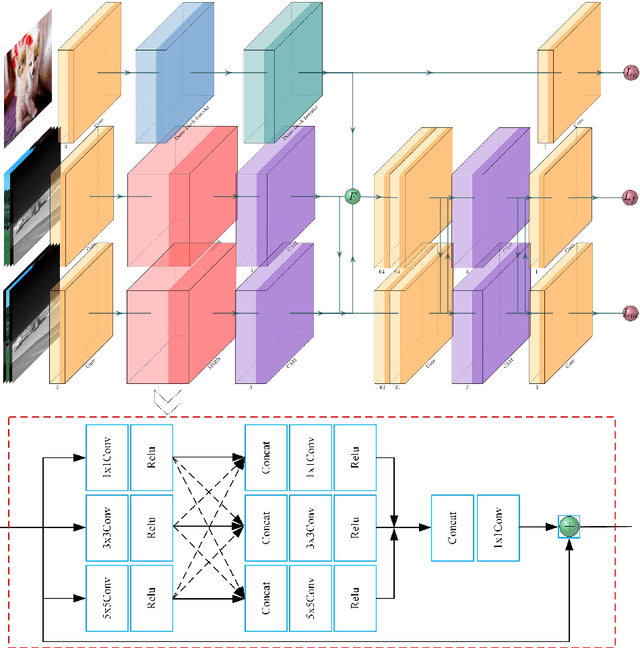
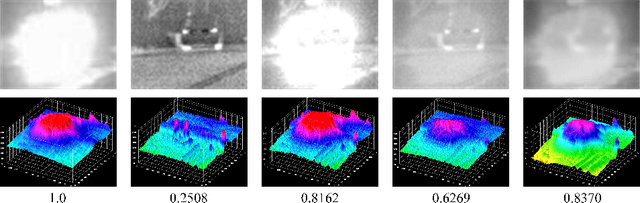

The characteristics of feature selection, nonlinear combination and multi-task auxiliary learning mechanism of the human visual perception system play an important role in real-world scenarios, but the research of image fusion theory based on the characteristics of human visual perception is less. Inspired by the characteristics of human visual perception, we propose a robust multi-task auxiliary learning optimization image fusion theory. Firstly, we combine channel attention model with nonlinear convolutional neural network to select features and fuse nonlinear features. Then, we analyze the impact of the existing image fusion loss on the image fusion quality, and establish the multi-loss function model of unsupervised learning network. Secondly, aiming at the multi-task auxiliary learning mechanism of human visual perception system, we study the influence of multi-task auxiliary learning mechanism on image fusion task on the basis of single task multi-loss network model. By simulating the three characteristics of human visual perception system, the fused image is more consistent with the mechanism of human brain image fusion. Finally, in order to verify the superiority of our algorithm, we carried out experiments on the combined vision system image data set, and extended our algorithm to the infrared and visible image and the multi-focus image public data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in generality and robustness.