 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Image Restoration and Fusion Based on Dynamic Degradation
Apr 30, 2021
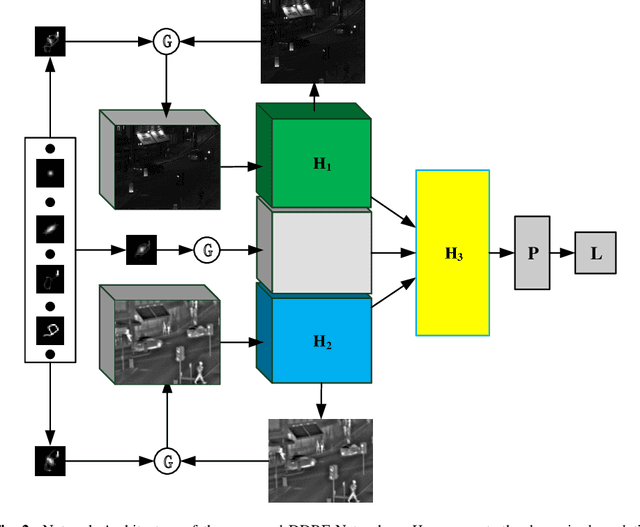


The deep-learning-based image restoration and fusion methods have achieved remarkable results. However, the existing restoration and fusion methods paid little research attention to the robustness problem caused by dynamic degradation. In this paper, we propose a novel dynamic image restoration and fusion neural network, termed as DDRF-Net, which is capable of solving two problems, i.e., static restoration and fusion, dynamic degradation. In order to solve the static fusion problem of existing methods, dynamic convolution is introduced to learn dynamic restoration and fusion weights. In addition, a dynamic degradation kernel is proposed to improve the robustness of image restoration and fusion. Our network framework can effectively combine image degradation with image fusion tasks, provide more detailed information for image fusion tasks through image restoration loss, and optimize image restoration tasks through image fusion loss. Therefore, the stumbling blocks of deep learning in image fusion, e.g., static fusion weight and specifically designed network architecture, are greatly mitigated. Extensive experiments show that our method is more superior compared with the state-of-the-art methods.
AE-Netv2: Optimization of Image Fusion Efficiency and Network Architecture
Oct 06, 2020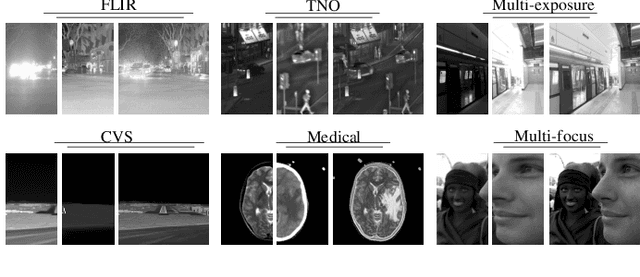
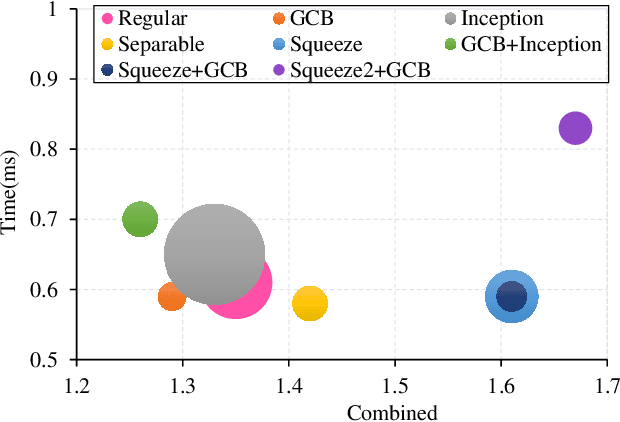

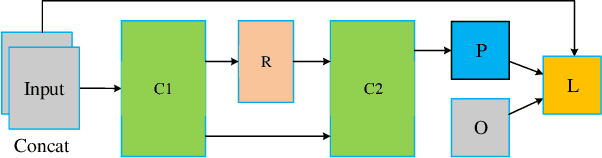
Existing image fusion methods pay few research attention to image fusion efficiency and network architecture. However, the efficiency and accuracy of image fusion has an important impact in practical applications. To solve this problem, we propose an \textit{efficient autonomous evolution image fusion method, dubed by AE-Netv2}. Different from other image fusion methods based on deep learning, AE-Netv2 is inspired by human brain cognitive mechanism. Firstly, we discuss the influence of different network architecture on image fusion quality and fusion efficiency, which provides a reference for the design of image fusion architecture. Secondly, we explore the influence of pooling layer on image fusion task and propose an image fusion method with pooling layer. Finally, we explore the commonness and characteristics of different image fusion tasks, which provides a research basis for further research on the continuous learning characteristics of human brain in the field of image fusion. Comprehensive experiments demonstrate the superiority of AE-Netv2 compared with state-of-the-art methods in different fusion tasks at a real time speed of 100+ FPS on GTX 2070. Among all tested methods based on deep learning, AE-Netv2 has the faster speed, the smaller model size and the better robustness.
AE-Net: Autonomous Evolution Image Fusion Method Inspired by Human Cognitive Mechanism
Jul 17, 2020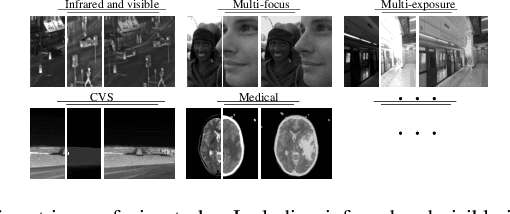
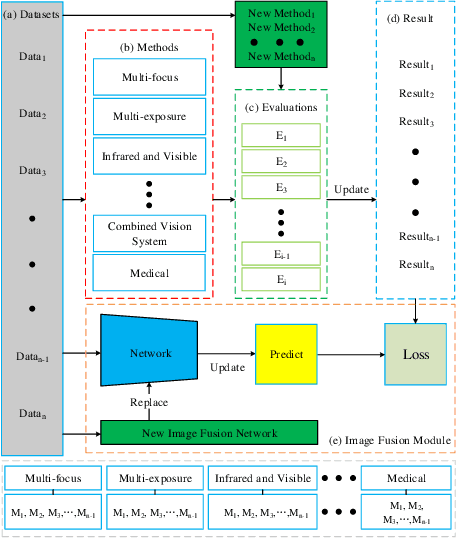

In order to solve the robustness and generality problems of the image fusion task,inspired by the human brain cognitive mechanism, we propose a robust and general image fusion method with autonomous evolution ability, and is therefore denoted with AE-Net. Through the collaborative optimization of multiple image fusion methods to simulate the cognitive process of human brain, unsupervised learning image fusion task can be transformed into semi-supervised image fusion task or supervised image fusion task, thus promoting the evolutionary ability of network model weight. Firstly, the relationship between human brain cognitive mechanism and image fusion task is analyzed and a physical model is established to simulate human brain cognitive mechanism. Secondly, we analyze existing image fusion methods and image fusion loss functions, select the image fusion method with complementary features to construct the algorithm module, establish the multi-loss joint evaluation function to obtain the optimal solution of algorithm module. The optimal solution of each image is used to guide the weight training of network model. Our image fusion method can effectively unify the cross-modal image fusion task and the same modal image fusion task, and effectively overcome the difference of data distribution between different datasets. Finally, extensive numerical results verify the effectiveness and superiority of our method on a variety of image fusion datasets, including multi-focus dataset, infrared and visi-ble dataset, medical image dataset and multi-exposure dataset. Comprehensive experiments demonstrate the superiority of our image fusion method in robustness and generality. In addition, experimental results also demonstate the effectiveness of human brain cognitive mechanism to improve the robustness and generality of image fusion.
A Robust Non-Linear and Feature-Selection Image Fusion Theory
Dec 23, 2019
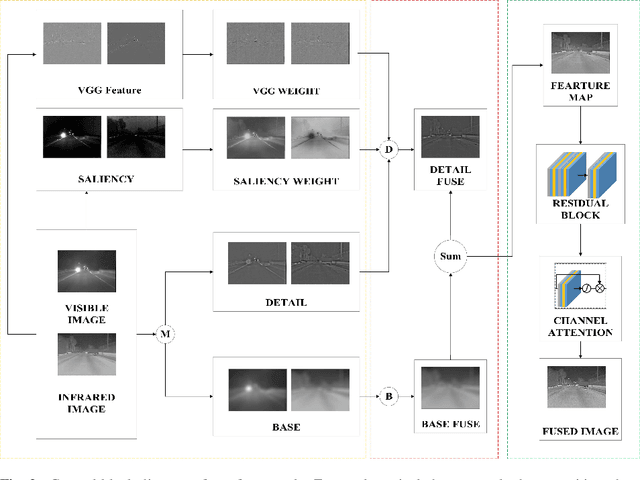

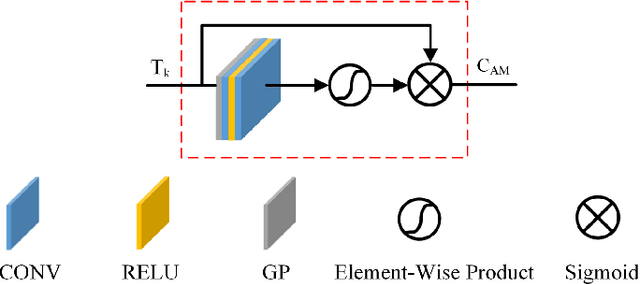
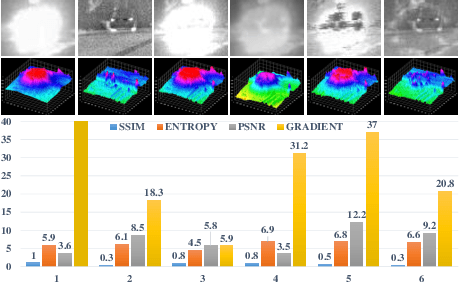
The human visual perception system has strong robustness in image fusion. This robustness is based on human visual perception system's characteristics of feature selection and non-linear fusion of different features. In order to simulate the human visual perception mechanism in image fusion tasks, we propose a multi-source image fusion framework that combines illuminance factors and attention mechanisms. The framework effectively combines traditional image features and modern deep learning features. First, we perform multi-scale decomposition of multi-source images. Then, the visual saliency map and the deep feature map are combined with the illuminance fusion factor to perform high-low frequency nonlinear fusion. Secondly, the characteristics of high and low frequency fusion are selected through the channel attention network to obtain the final fusion map. By simulating the nonlinear characteristics and selection characteristics of the human visual perception system in image fusion, the fused image is more in line with the human visual perception mechanism. Finally, we validate our fusion framework on public datasets of infrared and visible images, medical images and multi-focus images. The experimental results demonstrate the superiority of our fusion framework over state-of-arts in visual quality, objective fusion metrics and robustness.
A Cross-Modal Image Fusion Theory Guided by Human Visual Characteristics
Dec 23, 2019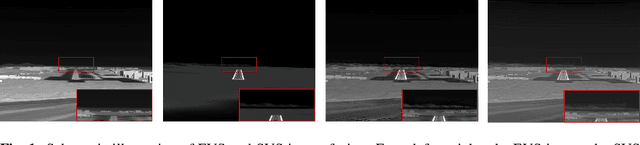
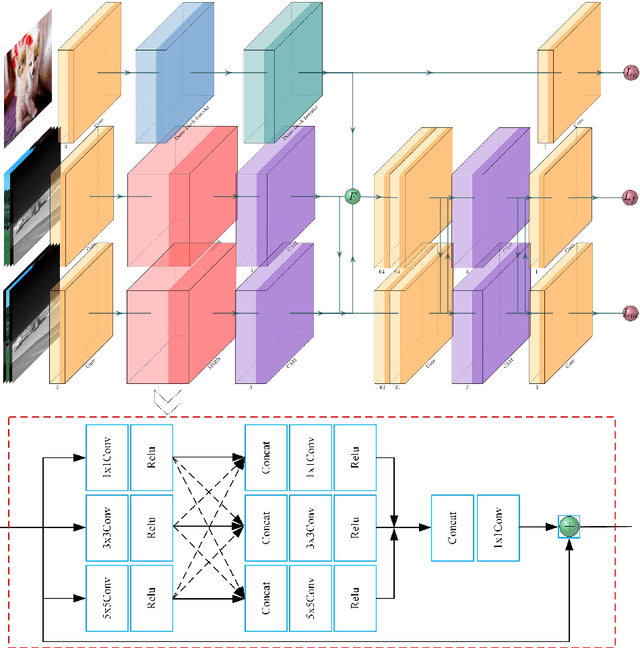
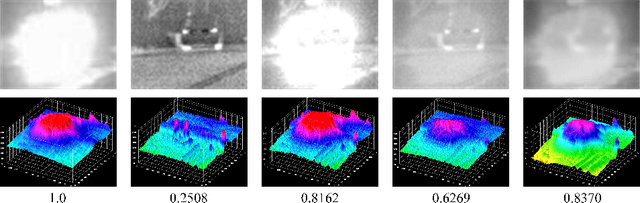

The characteristics of feature selection, nonlinear combination and multi-task auxiliary learning mechanism of the human visual perception system play an important role in real-world scenarios, but the research of image fusion theory based on the characteristics of human visual perception is less. Inspired by the characteristics of human visual perception, we propose a robust multi-task auxiliary learning optimization image fusion theory. Firstly, we combine channel attention model with nonlinear convolutional neural network to select features and fuse nonlinear features. Then, we analyze the impact of the existing image fusion loss on the image fusion quality, and establish the multi-loss function model of unsupervised learning network. Secondly, aiming at the multi-task auxiliary learning mechanism of human visual perception system, we study the influence of multi-task auxiliary learning mechanism on image fusion task on the basis of single task multi-loss network model. By simulating the three characteristics of human visual perception system, the fused image is more consistent with the mechanism of human brain image fusion. Finally, in order to verify the superiority of our algorithm, we carried out experiments on the combined vision system image data set, and extended our algorithm to the infrared and visible image and the multi-focus image public data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in generality and robustness.
Cross-Modal Image Fusion Theory Guided by Subjective Visual Attention
Dec 23, 2019


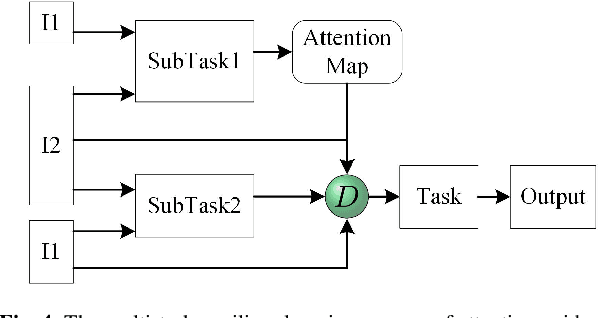
The human visual perception system has very strong robustness and contextual awareness in a variety of image processing tasks. This robustness and the perception ability of contextual awareness is closely related to the characteristics of multi-task auxiliary learning and subjective attention of the human visual perception system. In order to improve the robustness and contextual awareness of image fusion tasks, we proposed a multi-task auxiliary learning image fusion theory guided by subjective attention. The image fusion theory effectively unifies the subjective task intention and prior knowledge of human brain. In order to achieve our proposed image fusion theory, we first analyze the mechanism of multi-task auxiliary learning, build a multi-task auxiliary learning network. Secondly, based on the human visual attention perception mechanism, we introduce the human visual attention network guided by subjective tasks on the basis of the multi-task auxiliary learning network. The subjective intention is introduced by the subjective attention task model, so that the network can fuse images according to the subjective intention. Finally, in order to verify the superiority of our image fusion theory, we carried out experiments on the combined vision system image data set, and the infrared and visible image data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in contextual awareness and robustness.