 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Image Fusion Theory Guided by Subjective Visual Attention
Paper and Code
Dec 23, 2019


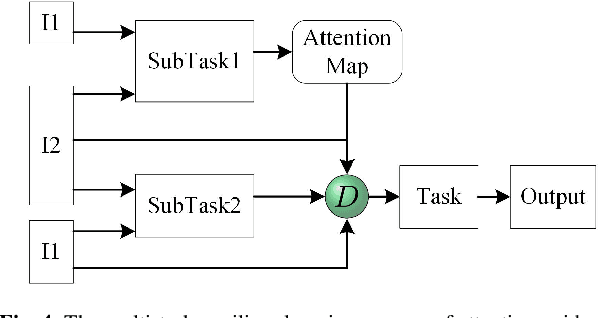
The human visual perception system has very strong robustness and contextual awareness in a variety of image processing tasks. This robustness and the perception ability of contextual awareness is closely related to the characteristics of multi-task auxiliary learning and subjective attention of the human visual perception system. In order to improve the robustness and contextual awareness of image fusion tasks, we proposed a multi-task auxiliary learning image fusion theory guided by subjective attention. The image fusion theory effectively unifies the subjective task intention and prior knowledge of human brain. In order to achieve our proposed image fusion theory, we first analyze the mechanism of multi-task auxiliary learning, build a multi-task auxiliary learning network. Secondly, based on the human visual attention perception mechanism, we introduce the human visual attention network guided by subjective tasks on the basis of the multi-task auxiliary learning network. The subjective intention is introduced by the subjective attention task model, so that the network can fuse images according to the subjective intention. Finally, in order to verify the superiority of our image fusion theory, we carried out experiments on the combined vision system image data set, and the infrared and visible image data set for experimental verification. The experimental results demonstrate the superiority of our fusion theory over state-of-arts in contextual awareness and robustness.