 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-Aware Models for Stream Temperature Prediction across Different Spatial Regions and Scales
Oct 10, 2025Understanding environmental ecosystems is vital for the sustainable management of our planet. However,existing physics-based and data-driven models often fail to generalize to varying spatial regions and scales due to the inherent data heterogeneity presented in real environmental ecosystems. This generalization issue is further exacerbated by the limited observation samples available for model training. To address these issues, we propose Geo-STARS, a geo-aware spatio-temporal modeling framework for predicting stream water temperature across different watersheds and spatial scales. The major innovation of Geo-STARS is the introduction of geo-aware embedding, which leverages geographic information to explicitly capture shared principles and patterns across spatial regions and scales. We further integrate the geo-aware embedding into a gated spatio-temporal graph neural network. This design enables the model to learn complex spatial and temporal patterns guided by geographic and hydrological context, even with sparse or no observational data. We evaluate Geo-STARS's efficacy in predicting stream water temperature, which is a master factor for water quality. Using real-world datasets spanning 37 years across multiple watersheds along the eastern coast of the United States, Geo-STARS demonstrates its superior generalization performance across both regions and scales, outperforming state-of-the-art baselines. These results highlight the promise of Geo-STARS for scalable, data-efficient environmental monitoring and decision-making.
Action-Adaptive Continual Learning: Enabling Policy Generalization under Dynamic Action Spaces
Jun 06, 2025Continual Learning (CL) is a powerful tool that enables agents to learn a sequence of tasks, accumulating knowledge learned in the past and using it for problem-solving or future task learning. However, existing CL methods often assume that the agent's capabilities remain static within dynamic environments, which doesn't reflect real-world scenarios where capabilities dynamically change. This paper introduces a new and realistic problem: Continual Learning with Dynamic Capabilities (CL-DC), posing a significant challenge for CL agents: How can policy generalization across different action spaces be achieved? Inspired by the cortical functions, we propose an Action-Adaptive Continual Learning framework (AACL) to address this challenge. Our framework decouples the agent's policy from the specific action space by building an action representation space. For a new action space, the encoder-decoder of action representations is adaptively fine-tuned to maintain a balance between stability and plasticity. Furthermore, we release a benchmark based on three environments to validate the effectiveness of methods for CL-DC. Experimental results demonstrate that our framework outperforms popular methods by generalizing the policy across action spaces.
UrbanMind: Urban Dynamics Prediction with Multifaceted Spatial-Temporal Large Language Models
May 16, 2025Understanding and predicting urban dynamics is crucial for managing transportation systems, optimizing urban planning, and enhancing public services. While neural network-based approaches have achieved success, they often rely on task-specific architectures and large volumes of data, limiting their ability to generalize across diverse urban scenarios. Meanwhile, Large Language Models (LLMs) offer strong reasoning and generalization capabilities, yet their application to spatial-temporal urban dynamics remains underexplored. Existing LLM-based methods struggle to effectively integrate multifaceted spatial-temporal data and fail to address distributional shifts between training and testing data, limiting their predictive reliability in real-world applications. To bridge this gap, we propose UrbanMind, a novel spatial-temporal LLM framework for multifaceted urban dynamics prediction that ensures both accurate forecasting and robust generalization. At its core, UrbanMind introduces Muffin-MAE, a multifaceted fusion masked autoencoder with specialized masking strategies that capture intricate spatial-temporal dependencies and intercorrelations among multifaceted urban dynamics. Additionally, we design a semantic-aware prompting and fine-tuning strategy that encodes spatial-temporal contextual details into prompts, enhancing LLMs' ability to reason over spatial-temporal patterns. To further improve generalization, we introduce a test time adaptation mechanism with a test data reconstructor, enabling UrbanMind to dynamically adjust to unseen test data by reconstructing LLM-generated embeddings. Extensive experiments on real-world urban datasets across multiple cities demonstrate that UrbanMind consistently outperforms state-of-the-art baselines, achieving high accuracy and robust generalization, even in zero-shot settings.
Multi-Granularity Open Intent Classification via Adaptive Granular-Ball Decision Boundary
Dec 18, 2024



Open intent classification is critical for the development of dialogue systems, aiming to accurately classify known intents into their corresponding classes while identifying unknown intents. Prior boundary-based methods assumed known intents fit within compact spherical regions, focusing on coarse-grained representation and precise spherical decision boundaries. However, these assumptions are often violated in practical scenarios, making it difficult to distinguish known intent classes from unknowns using a single spherical boundary. To tackle these issues, we propose a Multi-granularity Open intent classification method via adaptive Granular-Ball decision boundary (MOGB). Our MOGB method consists of two modules: representation learning and decision boundary acquiring. To effectively represent the intent distribution, we design a hierarchical representation learning method. This involves iteratively alternating between adaptive granular-ball clustering and nearest sub-centroid classification to capture fine-grained semantic structures within known intent classes. Furthermore, multi-granularity decision boundaries are constructed for open intent classification by employing granular-balls with varying centroids and radii. Extensive experiments conducted on three public datasets demonstrate the effectiveness of our proposed method.
* This paper has been Accepted on AAAI2025
Adaptive Process-Guided Learning: An Application in Predicting Lake DO Concentrations
Nov 20, 2024



This paper introduces a \textit{Process-Guided Learning (Pril)} framework that integrates physical models with recurrent neural networks (RNNs) to enhance the prediction of dissolved oxygen (DO) concentrations in lakes, which is crucial for sustaining water quality and ecosystem health. Unlike traditional RNNs, which may deliver high accuracy but often lack physical consistency and broad applicability, the \textit{Pril} method incorporates differential DO equations for each lake layer, modeling it as a first-order linear solution using a forward Euler scheme with a daily timestep. However, this method is sensitive to numerical instabilities. When drastic fluctuations occur, the numerical integration is neither mass-conservative nor stable. Especially during stratified conditions, exogenous fluxes into each layer cause significant within-day changes in DO concentrations. To address this challenge, we further propose an \textit{Adaptive Process-Guided Learning (April)} model, which dynamically adjusts timesteps from daily to sub-daily intervals with the aim of mitigating the discrepancies caused by variations in entrainment fluxes. \textit{April} uses a generator-discriminator architecture to identify days with significant DO fluctuations and employs a multi-step Euler scheme with sub-daily timesteps to effectively manage these variations. We have tested our methods on a wide range of lakes in the Midwestern USA, and demonstrated robust capability in predicting DO concentrations even with limited training data. While primarily focused on aquatic ecosystems, this approach is broadly applicable to diverse scientific and engineering disciplines that utilize process-based models, such as power engineering, climate science, and biomedicine.
Loss Distillation via Gradient Matching for Point Cloud Completion with Weighted Chamfer Distance
Sep 10, 2024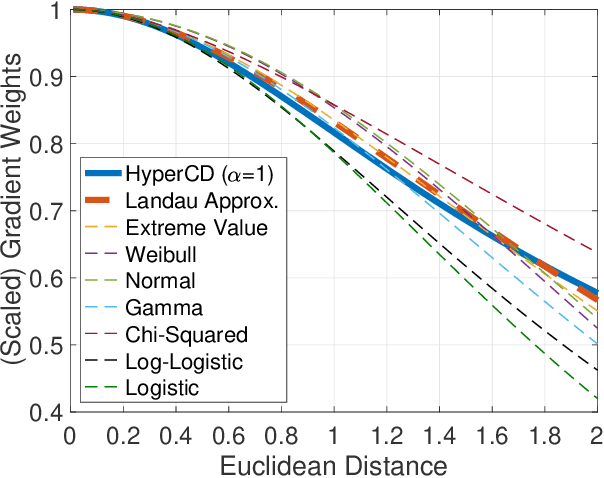
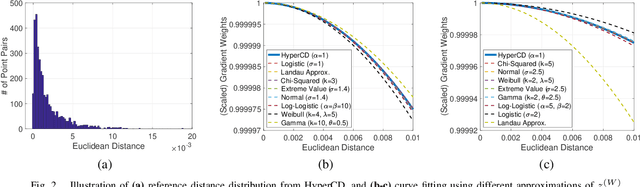


3D point clouds enhanced the robot's ability to perceive the geometrical information of the environments, making it possible for many downstream tasks such as grasp pose detection and scene understanding. The performance of these tasks, though, heavily relies on the quality of data input, as incomplete can lead to poor results and failure cases. Recent training loss functions designed for deep learning-based point cloud completion, such as Chamfer distance (CD) and its variants (\eg HyperCD ), imply a good gradient weighting scheme can significantly boost performance. However, these CD-based loss functions usually require data-related parameter tuning, which can be time-consuming for data-extensive tasks. To address this issue, we aim to find a family of weighted training losses ({\em weighted CD}) that requires no parameter tuning. To this end, we propose a search scheme, {\em Loss Distillation via Gradient Matching}, to find good candidate loss functions by mimicking the learning behavior in backpropagation between HyperCD and weighted CD. Once this is done, we propose a novel bilevel optimization formula to train the backbone network based on the weighted CD loss. We observe that: (1) with proper weighted functions, the weighted CD can always achieve similar performance to HyperCD, and (2) the Landau weighted CD, namely {\em Landau CD}, can outperform HyperCD for point cloud completion and lead to new state-of-the-art results on several benchmark datasets. {\it Our demo code is available at \url{https://github.com/Zhang-VISLab/IROS2024-LossDistillationWeightedCD}.}
Urban-Focused Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing
Jun 20, 2024Enhancing diverse human decision-making processes in an urban environment is a critical issue across various applications, including ride-sharing vehicle dispatching, public transportation management, and autonomous driving. Offline reinforcement learning (RL) is a promising approach to learn and optimize human urban strategies (or policies) from pre-collected human-generated spatial-temporal urban data. However, standard offline RL faces two significant challenges: (1) data scarcity and data heterogeneity, and (2) distributional shift. In this paper, we introduce MODA -- a Multi-Task Offline Reinforcement Learning with Contrastive Data Sharing approach. MODA addresses the challenges of data scarcity and heterogeneity in a multi-task urban setting through Contrastive Data Sharing among tasks. This technique involves extracting latent representations of human behaviors by contrasting positive and negative data pairs. It then shares data presenting similar representations with the target task, facilitating data augmentation for each task. Moreover, MODA develops a novel model-based multi-task offline RL algorithm. This algorithm constructs a robust Markov Decision Process (MDP) by integrating a dynamics model with a Generative Adversarial Network (GAN). Once the robust MDP is established, any online RL or planning algorithm can be applied. Extensive experiments conducted in a real-world multi-task urban setting validate the effectiveness of MODA. The results demonstrate that MODA exhibits significant improvements compared to state-of-the-art baselines, showcasing its capability in advancing urban decision-making processes. We also made our code available to the research community.
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Apr 17, 2024



Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
Multi-State Brain Network Discovery
Nov 04, 2023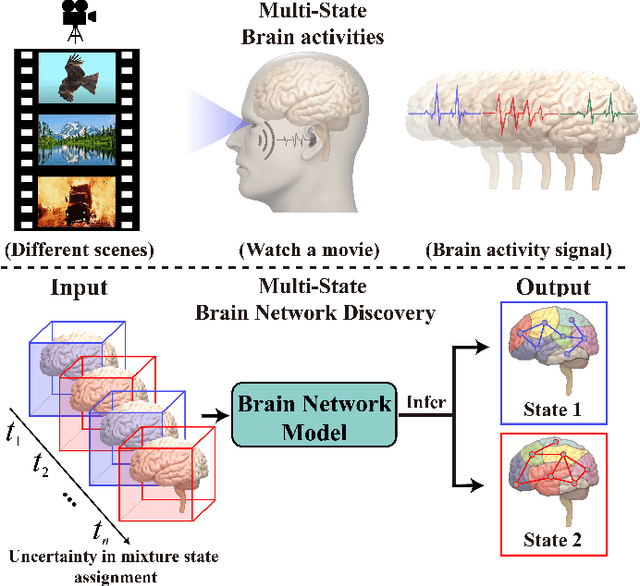
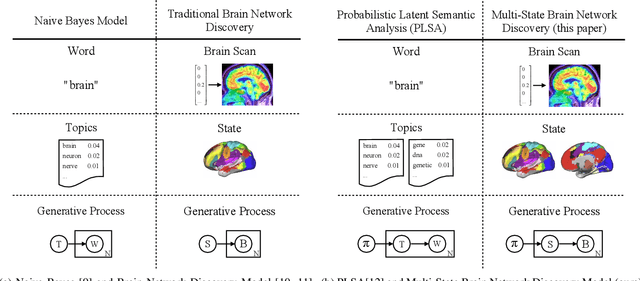
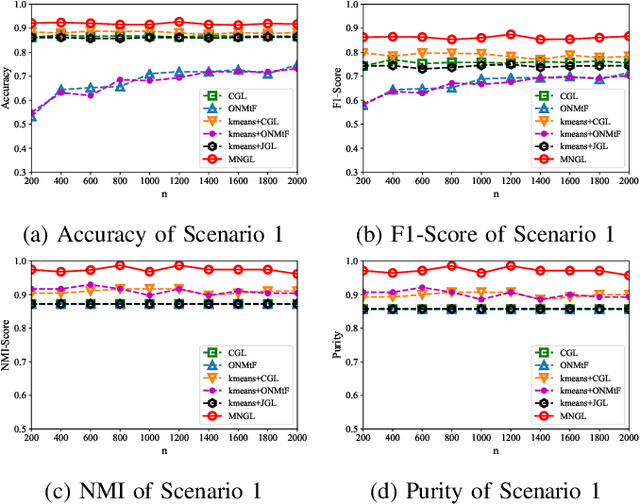
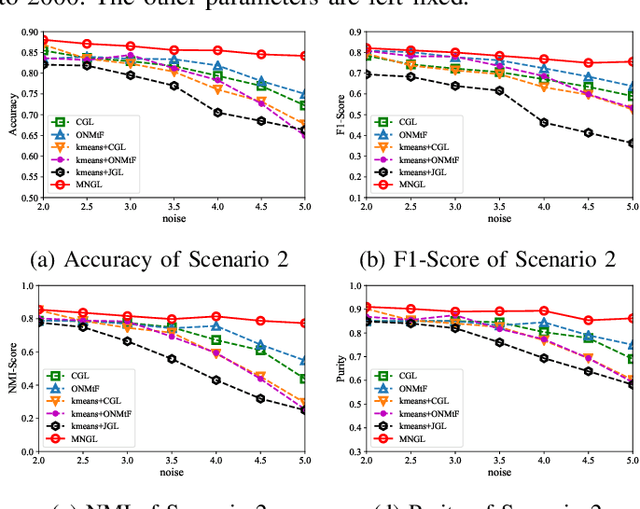
Brain network discovery aims to find nodes and edges from the spatio-temporal signals obtained by neuroimaging data, such as fMRI scans of human brains. Existing methods tend to derive representative or average brain networks, assuming observed signals are generated by only a single brain activity state. However, the human brain usually involves multiple activity states, which jointly determine the brain activities. The brain regions and their connectivity usually exhibit intricate patterns that are difficult to capture with only a single-state network. Recent studies find that brain parcellation and connectivity change according to the brain activity state. We refer to such brain networks as multi-state, and this mixture can help us understand human behavior. Thus, compared to a single-state network, a multi-state network can prevent us from losing crucial information of cognitive brain network. To achieve this, we propose a new model called MNGL (Multi-state Network Graphical Lasso), which successfully models multi-state brain networks by combining CGL (coherent graphical lasso) with GMM (Gaussian Mixture Model). Using both synthetic and real world ADHD 200 fMRI datasets, we demonstrate that MNGL outperforms recent state-of-the-art alternatives by discovering more explanatory and realistic results.
STORM-GAN: Spatio-Temporal Meta-GAN for Cross-City Estimation of Human Mobility Responses to COVID-19
Jan 20, 2023Human mobility estimation is crucial during the COVID-19 pandemic due to its significant guidance for policymakers to make non-pharmaceutical interventions. While deep learning approaches outperform conventional estimation techniques on tasks with abundant training data, the continuously evolving pandemic poses a significant challenge to solving this problem due to data nonstationarity, limited observations, and complex social contexts. Prior works on mobility estimation either focus on a single city or lack the ability to model the spatio-temporal dependencies across cities and time periods. To address these issues, we make the first attempt to tackle the cross-city human mobility estimation problem through a deep meta-generative framework. We propose a Spatio-Temporal Meta-Generative Adversarial Network (STORM-GAN) model that estimates dynamic human mobility responses under a set of social and policy conditions related to COVID-19. Facilitated by a novel spatio-temporal task-based graph (STTG) embedding, STORM-GAN is capable of learning shared knowledge from a spatio-temporal distribution of estimation tasks and quickly adapting to new cities and time periods with limited training samples. The STTG embedding component is designed to capture the similarities among cities to mitigate cross-task heterogeneity. Experimental results on real-world data show that the proposed approach can greatly improve estimation performance and out-perform baselines.