 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Motif Signatures for Temporal Graph Neural Networks
May 31, 2026Real temporal interaction streams carry predictive structure in short-horizon motif patterns -- repetition, reciprocity, star diversity, triadic flow -- that vanilla temporal graph neural networks (TGNNs) often fail to expose to their edge scorers. We show this concretely on MOOC interaction prediction, where a small four-feature family of past-window star counts already delivers most of the lift over a strong static GNN. Across a wide set of real and synthetic temporal datasets we find that motif activity organizes consistently along three scale-stable axes (dyadic recency/reciprocity, star diversity, triadic flow), and we use this empirical structure to design a compact 13-coordinate, leakage-safe, candidate-local motif feature map h(u, v, t) that linearly embeds into any static or temporal encoder without architectural changes. A temporal Weisfeiler-Leman (WL) analysis places the augmentation relative to the first level of an anchored temporal-WL hierarchy and exhibits a candidate-anchored pair on which motif features distinguish. We demonstrate empirically that the same augmentation consistently lifts performance across heterogeneous tasks: TGB link-property prediction across all five baselines, edge classification on Bitcoin Alpha/OTC and MOOC, and graph-level classification of synthetic temporal generators.
A Bipartite Graph Approach to U.S.-China Cross-Market Return Forecasting
Mar 11, 2026This paper studies cross-market return predictability through a machine learning framework that preserves economic structure. Exploiting the non-overlapping trading hours of the U.S. and Chinese equity markets, we construct a directed bipartite graph that captures time-ordered predictive linkages between stocks across markets. Edges are selected via rolling-window hypothesis testing, and the resulting graph serves as a sparse, economically interpretable feature-selection layer for downstream machine learning models. We apply a range of regularized and ensemble methods to forecast open-to-close returns using lagged foreign-market information. Our results reveal a pronounced directional asymmetry: U.S. previous-close-to-close returns contain substantial predictive information for Chinese intraday returns, whereas the reverse effect is limited. This informational asymmetry translates into economically meaningful performance differences and highlights how structured machine learning frameworks can uncover cross-market dependencies while maintaining interpretability.
Data-Driven Graph Filters via Adaptive Spectral Shaping
Feb 03, 2026We introduce Adaptive Spectral Shaping, a data-driven framework for graph filtering that learns a reusable baseline spectral kernel and modulates it with a small set of Gaussian factors. The resulting multi-peak, multi-scale responses allocate energy to heterogeneous regions of the Laplacian spectrum while remaining interpretable via explicit centers and bandwidths. To scale, we implement filters with Chebyshev polynomial expansions, avoiding eigendecompositions. We further propose Transferable Adaptive Spectral Shaping (TASS): the baseline kernel is learned on source graphs and, on a target graph, kept fixed while only the shaping parameters are adapted, enabling few-shot transfer under matched compute. Across controlled synthetic benchmarks spanning graph families and signal regimes, Adaptive Spectral Shaping reduces reconstruction error relative to fixed-prototype wavelets and learned linear banks, and TASS yields consistent positive transfer. The framework provides compact spectral modules that plug into graph signal processing pipelines and graph neural networks, combining scalability, interpretability, and cross-graph generalization.
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?
May 11, 2025



Large Language Models (LLMs) have recently been leveraged for asset pricing tasks and stock trading applications, enabling AI agents to generate investment decisions from unstructured financial data. However, most evaluations of LLM timing-based investing strategies are conducted on narrow timeframes and limited stock universes, overstating effectiveness due to survivorship and data-snooping biases. We critically assess their generalizability and robustness by proposing FINSABER, a backtesting framework evaluating timing-based strategies across longer periods and a larger universe of symbols. Systematic backtests over two decades and 100+ symbols reveal that previously reported LLM advantages deteriorate significantly under broader cross-section and over a longer-term evaluation. Our market regime analysis further demonstrates that LLM strategies are overly conservative in bull markets, underperforming passive benchmarks, and overly aggressive in bear markets, incurring heavy losses. These findings highlight the need to develop LLM strategies that are able to prioritise trend detection and regime-aware risk controls over mere scaling of framework complexity.
Split Conformal Prediction under Data Contamination
Jul 10, 2024



Conformal prediction is a non-parametric technique for constructing prediction intervals or sets from arbitrary predictive models under the assumption that the data is exchangeable. It is popular as it comes with theoretical guarantees on the marginal coverage of the prediction sets and the split conformal prediction variant has a very low computational cost compared to model training. We study the robustness of split conformal prediction in a data contamination setting, where we assume a small fraction of the calibration scores are drawn from a different distribution than the bulk. We quantify the impact of the corrupted data on the coverage and efficiency of the constructed sets when evaluated on "clean" test points, and verify our results with numerical experiments. Moreover, we propose an adjustment in the classification setting which we call Contamination Robust Conformal Prediction, and verify the efficacy of our approach using both synthetic and real datasets.
Dynamic angular synchronization under smoothness constraints
Jun 06, 2024



Given an undirected measurement graph $\mathcal{H} = ([n], \mathcal{E})$, the classical angular synchronization problem consists of recovering unknown angles $\theta_1^*,\dots,\theta_n^*$ from a collection of noisy pairwise measurements of the form $(\theta_i^* - \theta_j^*) \mod 2\pi$, for all $\{i,j\} \in \mathcal{E}$. This problem arises in a variety of applications, including computer vision, time synchronization of distributed networks, and ranking from pairwise comparisons. In this paper, we consider a dynamic version of this problem where the angles, and also the measurement graphs evolve over $T$ time points. Assuming a smoothness condition on the evolution of the latent angles, we derive three algorithms for joint estimation of the angles over all time points. Moreover, for one of the algorithms, we establish non-asymptotic recovery guarantees for the mean-squared error (MSE) under different statistical models. In particular, we show that the MSE converges to zero as $T$ increases under milder conditions than in the static setting. This includes the setting where the measurement graphs are highly sparse and disconnected, and also when the measurement noise is large and can potentially increase with $T$. We complement our theoretical results with experiments on synthetic data.
Maximum Likelihood Estimation on Stochastic Blockmodels for Directed Graph Clustering
Mar 28, 2024



This paper studies the directed graph clustering problem through the lens of statistics, where we formulate clustering as estimating underlying communities in the directed stochastic block model (DSBM). We conduct the maximum likelihood estimation (MLE) on the DSBM and thereby ascertain the most probable community assignment given the observed graph structure. In addition to the statistical point of view, we further establish the equivalence between this MLE formulation and a novel flow optimization heuristic, which jointly considers two important directed graph statistics: edge density and edge orientation. Building on this new formulation of directed clustering, we introduce two efficient and interpretable directed clustering algorithms, a spectral clustering algorithm and a semidefinite programming based clustering algorithm. We provide a theoretical upper bound on the number of misclustered vertices of the spectral clustering algorithm using tools from matrix perturbation theory. We compare, both quantitatively and qualitatively, our proposed algorithms with existing directed clustering methods on both synthetic and real-world data, thus providing further ground to our theoretical contributions.
L2G2G: a Scalable Local-to-Global Network Embedding with Graph Autoencoders
Feb 02, 2024



For analysing real-world networks, graph representation learning is a popular tool. These methods, such as a graph autoencoder (GAE), typically rely on low-dimensional representations, also called embeddings, which are obtained through minimising a loss function; these embeddings are used with a decoder for downstream tasks such as node classification and edge prediction. While GAEs tend to be fairly accurate, they suffer from scalability issues. For improved speed, a Local2Global approach, which combines graph patch embeddings based on eigenvector synchronisation, was shown to be fast and achieve good accuracy. Here we propose L2G2G, a Local2Global method which improves GAE accuracy without sacrificing scalability. This improvement is achieved by dynamically synchronising the latent node representations, while training the GAEs. It also benefits from the decoder computing an only local patch loss. Hence, aligning the local embeddings in each epoch utilises more information from the graph than a single post-training alignment does, while maintaining scalability. We illustrate on synthetic benchmarks, as well as real-world examples, that L2G2G achieves higher accuracy than the standard Local2Global approach and scales efficiently on the larger data sets. We find that for large and dense networks, it even outperforms the slow, but assumed more accurate, GAEs.
Robust Angular Synchronization via Directed Graph Neural Networks
Oct 09, 2023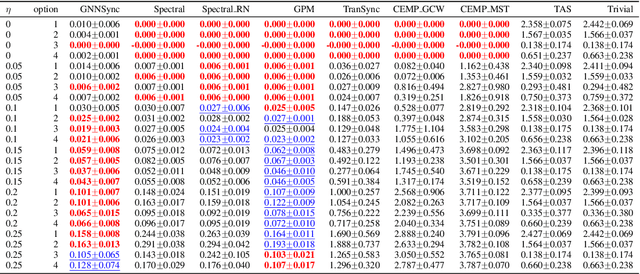

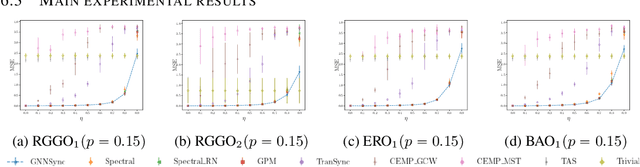
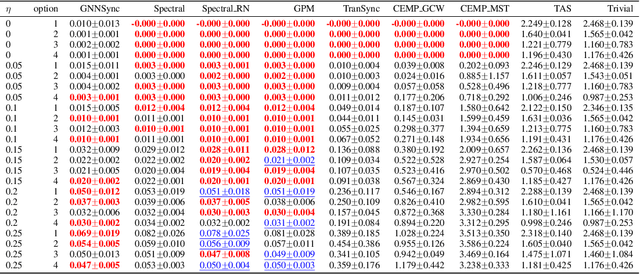
The angular synchronization problem aims to accurately estimate (up to a constant additive phase) a set of unknown angles $\theta_1, \dots, \theta_n\in[0, 2\pi)$ from $m$ noisy measurements of their offsets $\theta_i-\theta_j \;\mbox{mod} \; 2\pi.$ Applications include, for example, sensor network localization, phase retrieval, and distributed clock synchronization. An extension of the problem to the heterogeneous setting (dubbed $k$-synchronization) is to estimate $k$ groups of angles simultaneously, given noisy observations (with unknown group assignment) from each group. Existing methods for angular synchronization usually perform poorly in high-noise regimes, which are common in applications. In this paper, we leverage neural networks for the angular synchronization problem, and its heterogeneous extension, by proposing GNNSync, a theoretically-grounded end-to-end trainable framework using directed graph neural networks. In addition, new loss functions are devised to encode synchronization objectives. Experimental results on extensive data sets demonstrate that GNNSync attains competitive, and often superior, performance against a comprehensive set of baselines for the angular synchronization problem and its extension, validating the robustness of GNNSync even at high noise levels.
Graph Neural Networks for Forecasting Multivariate Realized Volatility with Spillover Effects
Aug 01, 2023


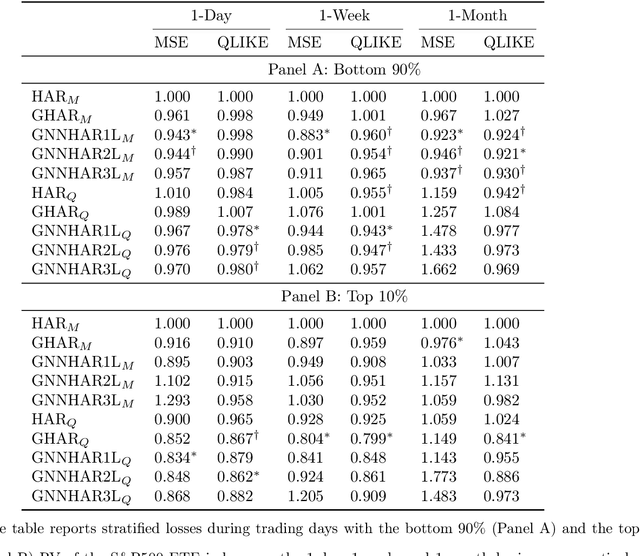
We present a novel methodology for modeling and forecasting multivariate realized volatilities using customized graph neural networks to incorporate spillover effects across stocks. The proposed model offers the benefits of incorporating spillover effects from multi-hop neighbors, capturing nonlinear relationships, and flexible training with different loss functions. Our empirical findings provide compelling evidence that incorporating spillover effects from multi-hop neighbors alone does not yield a clear advantage in terms of predictive accuracy. However, modeling nonlinear spillover effects enhances the forecasting accuracy of realized volatilities, particularly for short-term horizons of up to one week. Moreover, our results consistently indicate that training with the Quasi-likelihood loss leads to substantial improvements in model performance compared to the commonly-used mean squared error. A comprehensive series of empirical evaluations in alternative settings confirm the robustness of our results.