 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime is Not a Label: Continuous Phase Rotation for Temporal Knowledge Graphs and Agentic Memory
Apr 13, 2026Structured memory representations such as knowledge graphs are central to autonomous agents and other long-lived systems. However, most existing approaches model time as discrete metadata, either sorting by recency (burying old-yet-permanent knowledge), simply overwriting outdated facts, or requiring an expensive LLM call at every ingestion step, leaving them unable to distinguish persistent facts from evolving ones. To address this, we introduce RoMem, a drop-in temporal knowledge graph module for structured memory systems, applicable to agentic memory and beyond. A pretrained Semantic Speed Gate maps each relation's text embedding to a volatility score, learning from data that evolving relations (e.g., "president of") should rotate fast while persistent ones (e.g., "born in") should remain stable. Combined with continuous phase rotation, this enables geometric shadowing: obsolete facts are rotated out of phase in complex vector space, so temporally correct facts naturally outrank contradictions without deletion. On temporal knowledge graph completion, RoMem achieves state-of-the-art results on ICEWS05-15 (72.6 MRR). Applied to agentic memory, it delivers 2-3x MRR and answer accuracy on temporal reasoning (MultiTQ), dominates hybrid benchmark (LoCoMo), preserves static memory with zero degradation (DMR-MSC), and generalises zero-shot to unseen financial domains (FinTMMBench).
Spectral Attention Steering for Prompt Highlighting
Mar 01, 2026Attention steering is an important technique for controlling model focus, enabling capabilities such as prompt highlighting, where the model prioritises user-specified text. However, existing attention steering methods require explicit storage of the full attention matrix, making them incompatible with memory-efficient implementations like FlashAttention. We introduce Spectral Editing Key Amplification (SEKA), a training-free steering method that tackles this by directly editing key embeddings before attention computation. SEKA uses spectral decomposition to steer key embeddings towards latent directions that amplify attention scores for certain tokens. We extend this to Adaptive SEKA (AdaSEKA), a query-adaptive variant that uses a training-free routing mechanism to dynamically combine multiple expert subspaces based on the prompt's semantic intent. Our experiments show both methods significantly outperform strong baselines on standard steering benchmarks while adding much lower latency and memory overhead, in compatibility with optimised attention.
One More Question is Enough, Expert Question Decomposition (EQD) Model for Domain Quantitative Reasoning
Oct 01, 2025Domain-specific quantitative reasoning remains a major challenge for large language models (LLMs), especially in fields requiring expert knowledge and complex question answering (QA). In this work, we propose Expert Question Decomposition (EQD), an approach designed to balance the use of domain knowledge with computational efficiency. EQD is built on a two-step fine-tuning framework and guided by a reward function that measures the effectiveness of generated sub-questions in improving QA outcomes. It requires only a few thousand training examples and a single A100 GPU for fine-tuning, with inference time comparable to zero-shot prompting. Beyond its efficiency, EQD outperforms state-of-the-art domain-tuned models and advanced prompting strategies. We evaluate EQD in the financial domain, characterized by specialized knowledge and complex quantitative reasoning, across four benchmark datasets. Our method consistently improves QA performance by 0.6% to 10.5% across different LLMs. Our analysis reveals an important insight: in domain-specific QA, a single supporting question often provides greater benefit than detailed guidance steps.
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?
May 11, 2025



Large Language Models (LLMs) have recently been leveraged for asset pricing tasks and stock trading applications, enabling AI agents to generate investment decisions from unstructured financial data. However, most evaluations of LLM timing-based investing strategies are conducted on narrow timeframes and limited stock universes, overstating effectiveness due to survivorship and data-snooping biases. We critically assess their generalizability and robustness by proposing FINSABER, a backtesting framework evaluating timing-based strategies across longer periods and a larger universe of symbols. Systematic backtests over two decades and 100+ symbols reveal that previously reported LLM advantages deteriorate significantly under broader cross-section and over a longer-term evaluation. Our market regime analysis further demonstrates that LLM strategies are overly conservative in bull markets, underperforming passive benchmarks, and overly aggressive in bear markets, incurring heavy losses. These findings highlight the need to develop LLM strategies that are able to prioritise trend detection and regime-aware risk controls over mere scaling of framework complexity.
TSPRank: Bridging Pairwise and Listwise Methods with a Bilinear Travelling Salesman Model
Nov 18, 2024



Traditional Learning-To-Rank (LETOR) approaches, including pairwise methods like RankNet and LambdaMART, often fall short by solely focusing on pairwise comparisons, leading to sub-optimal global rankings. Conversely, deep learning based listwise methods, while aiming to optimise entire lists, require complex tuning and yield only marginal improvements over robust pairwise models. To overcome these limitations, we introduce Travelling Salesman Problem Rank (TSPRank), a hybrid pairwise-listwise ranking method. TSPRank reframes the ranking problem as a Travelling Salesman Problem (TSP), a well-known combinatorial optimisation challenge that has been extensively studied for its numerous solution algorithms and applications. This approach enables the modelling of pairwise relationships and leverages combinatorial optimisation to determine the listwise ranking. This approach can be directly integrated as an additional component into embeddings generated by existing backbone models to enhance ranking performance. Our extensive experiments across three backbone models on diverse tasks, including stock ranking, information retrieval, and historical events ordering, demonstrate that TSPRank significantly outperforms both pure pairwise and listwise methods. Our qualitative analysis reveals that TSPRank's main advantage over existing methods is its ability to harness global information better while ranking. TSPRank's robustness and superior performance across different domains highlight its potential as a versatile and effective LETOR solution. The code and preprocessed data are available at https://github.com/waylonli/TSPRank-KDD2025.
Modeling News Interactions and Influence for Financial Market Prediction
Oct 14, 2024The diffusion of financial news into market prices is a complex process, making it challenging to evaluate the connections between news events and market movements. This paper introduces FININ (Financial Interconnected News Influence Network), a novel market prediction model that captures not only the links between news and prices but also the interactions among news items themselves. FININ effectively integrates multi-modal information from both market data and news articles. We conduct extensive experiments on two datasets, encompassing the S&P 500 and NASDAQ 100 indices over a 15-year period and over 2.7 million news articles. The results demonstrate FININ's effectiveness, outperforming advanced market prediction models with an improvement of 0.429 and 0.341 in the daily Sharpe ratio for the two markets respectively. Moreover, our results reveal insights into the financial news, including the delayed market pricing of news, the long memory effect of news, and the limitations of financial sentiment analysis in fully extracting predictive power from news data.
MANA-Net: Mitigating Aggregated Sentiment Homogenization with News Weighting for Enhanced Market Prediction
Sep 09, 2024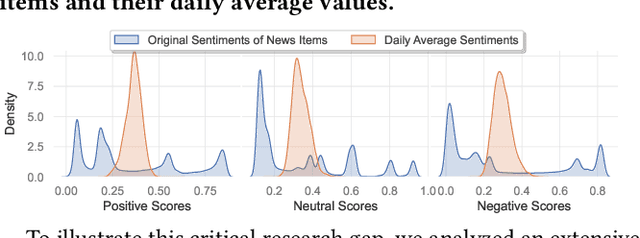
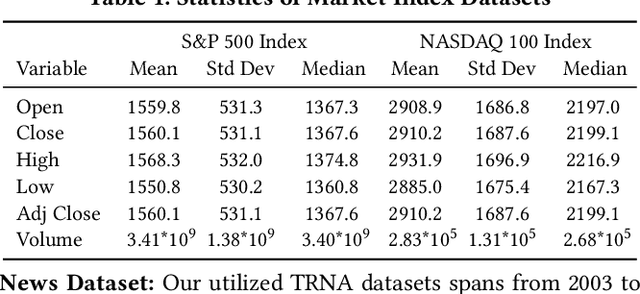
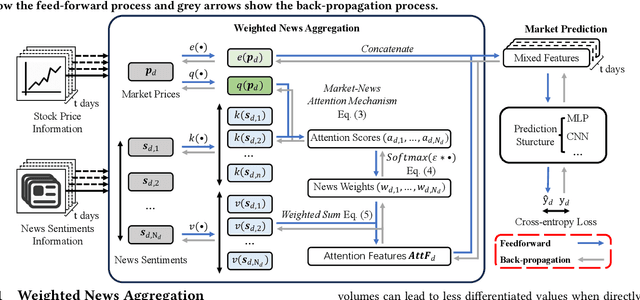
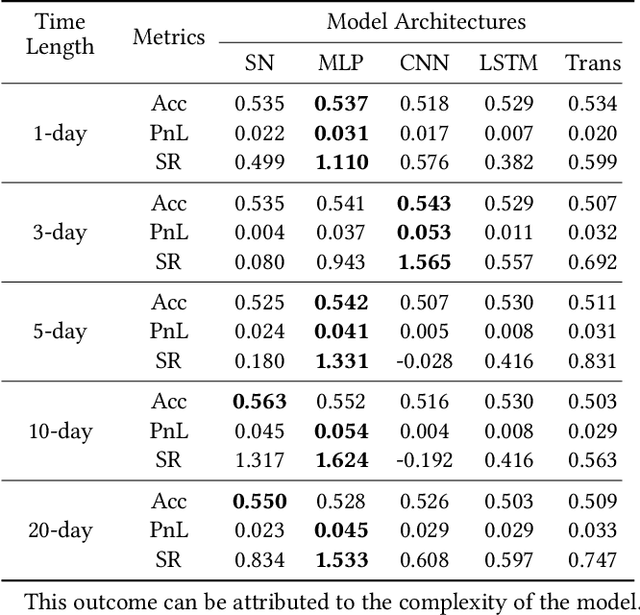
It is widely acknowledged that extracting market sentiments from news data benefits market predictions. However, existing methods of using financial sentiments remain simplistic, relying on equal-weight and static aggregation to manage sentiments from multiple news items. This leads to a critical issue termed ``Aggregated Sentiment Homogenization'', which has been explored through our analysis of a large financial news dataset from industry practice. This phenomenon occurs when aggregating numerous sentiments, causing representations to converge towards the mean values of sentiment distributions and thereby smoothing out unique and important information. Consequently, the aggregated sentiment representations lose much predictive value of news data. To address this problem, we introduce the Market Attention-weighted News Aggregation Network (MANA-Net), a novel method that leverages a dynamic market-news attention mechanism to aggregate news sentiments for market prediction. MANA-Net learns the relevance of news sentiments to price changes and assigns varying weights to individual news items. By integrating the news aggregation step into the networks for market prediction, MANA-Net allows for trainable sentiment representations that are optimized directly for prediction. We evaluate MANA-Net using the S&P 500 and NASDAQ 100 indices, along with financial news spanning from 2003 to 2018. Experimental results demonstrate that MANA-Net outperforms various recent market prediction methods, enhancing Profit & Loss by 1.1% and the daily Sharpe ratio by 0.252.
Can Deep Learning Predict Risky Retail Investors? A Case Study in Financial Risk Behavior Forecasting
Jan 17, 2019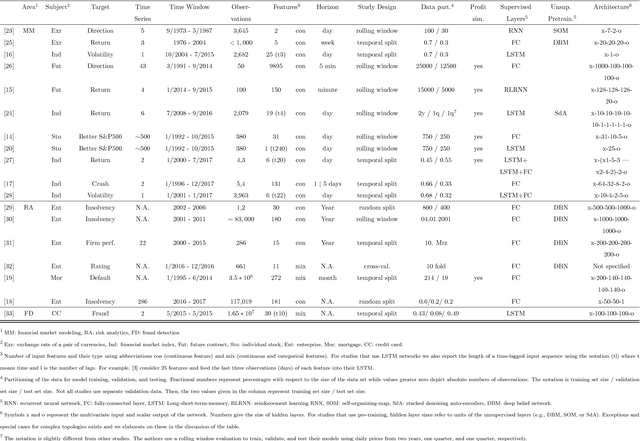
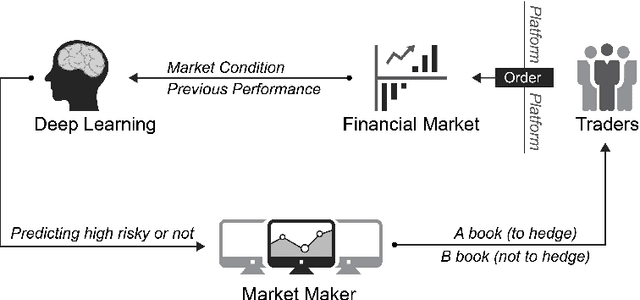
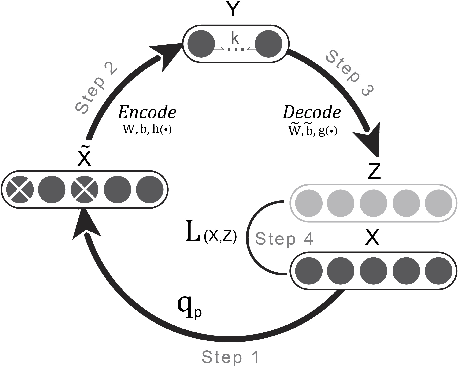
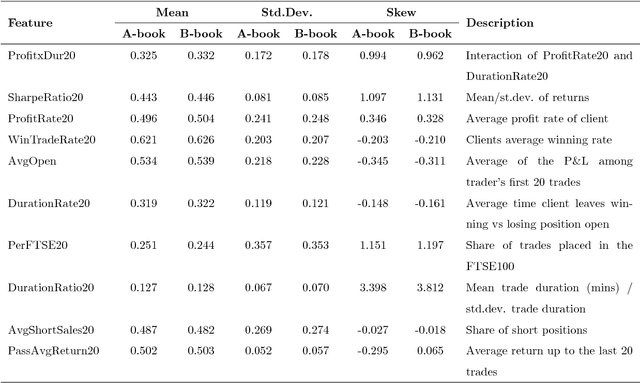
The success of deep learning for unstructured data analysis is well documented but little evidence has emerged related to the structured, tabular datasets used in decision support. We address this research gap by considering the potential of deep learning to support financial risk management. In particular, we develop a deep learning model for predicting whether individual spread traders are likely to secure profits from future trades. This embodies typical modeling challenges faced in risk and behavior forecasting. Conventional machine learning requires data that is representative of the feature-target relationship and relies on the often costly development, maintenance, and revision of handcrafted features. Consequently, modeling highly variable, heterogeneous patterns such as the behavior of traders is challenging. Deep learning promises a remedy. Learning hierarchical distributed representations of the raw data in an automatic manner (e.g. risk taking behavior), it uncovers generative features that determine the target (e.g., trader's profitability), avoids manual feature engineering, and is more robust toward change (e.g. dynamic market conditions). The results of employing a deep network for operational risk forecasting confirm the feature learning capability of deep learning, provide guidance on designing a suitable network architecture and demonstrate the superiority of deep learning over powerful machine learning benchmarks. Empirical results suggest that the financial institution which provided the data can increase annual profits by 16% through implementing a deep learning based risk management policy. The findings demonstrate the potential of applying deep learning methods for management science problems in finance, marketing, and accounting.