 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Faithfulness Alignment for Cross-Model Circuit Transfer
Apr 27, 2026Mechanistic interpretability has made it possible to localize circuits underlying specific behaviors in language models, but existing methods are expensive, model-specific, and difficult to scale to larger architectures. We introduce \textbf{Differentiable Faithfulness Alignment (DFA)}, a framework that transfers circuit information from a smaller source model to a larger target model through a learned differentiable alignment. DFA projects source-model node importance scores into the target model and trains this mapping with a soft faithfulness objective, avoiding full circuit discovery on the target model. We evaluate DFA on Llama-3 and Qwen-2.5 across six tasks spanning factual retrieval, multiple-choice reasoning, and arithmetic. The strongest results occur on Llama-3 $1$B$\rightarrow3$B, where aligned circuits are often competitive with direct node attribution and zero-shot transfer remains effective. Recovery weakens for larger source--target gaps and is substantially lower on Qwen-2.5, suggesting that transfer becomes harder as architectural and scaling differences increase. Overall, DFA consistently outperforms simple baselines and, in some settings, recovers target-model circuits with faithfulness comparable to or stronger than direct attribution. These results suggest that smaller models can provide useful mechanistic priors for larger ones, while highlighting both the promise and the limits of node-level cross-model circuit alignment.\footnote{Code is available at https://github.com/jasonshaoshun/dfa-circuits.
Self Knowledge Re-expression: A Fully Local Method for Adapting LLMs to Tasks Using Intrinsic Knowledge
Apr 24, 2026While the next-token prediction (NTP) paradigm enables large language models (LLMs) to express their intrinsic knowledge, its sequential nature constrains performance on specialized, non-generative tasks. We attribute this performance bottleneck to the LLMs' knowledge expression mechanism, rather than to deficiencies in knowledge acquisition. To address this, we propose Self-Knowledge Re-expression (SKR), a novel, task-agnostic adaptation method. SKR transforms the LLM's output from generic token generation to highly efficient, task-specific expression. SKR is a fully local method that uses only unannotated data, requiring neither human supervision nor model distillation. Experiments on a large financial document dataset demonstrate substantial improvements: over 40% in Recall@1 for information retrieval tasks, over 76% reduction in object detection latency, and over 33% increase in anomaly detection AUPRC. Our results on the MMDocRAG dataset surpass those of leading retrieval models by at least 12.6%.
Spectral Attention Steering for Prompt Highlighting
Mar 01, 2026Attention steering is an important technique for controlling model focus, enabling capabilities such as prompt highlighting, where the model prioritises user-specified text. However, existing attention steering methods require explicit storage of the full attention matrix, making them incompatible with memory-efficient implementations like FlashAttention. We introduce Spectral Editing Key Amplification (SEKA), a training-free steering method that tackles this by directly editing key embeddings before attention computation. SEKA uses spectral decomposition to steer key embeddings towards latent directions that amplify attention scores for certain tokens. We extend this to Adaptive SEKA (AdaSEKA), a query-adaptive variant that uses a training-free routing mechanism to dynamically combine multiple expert subspaces based on the prompt's semantic intent. Our experiments show both methods significantly outperform strong baselines on standard steering benchmarks while adding much lower latency and memory overhead, in compatibility with optimised attention.
Can I Have Your Order? Monte-Carlo Tree Search for Slot Filling Ordering in Diffusion Language Models
Feb 13, 2026While plan-and-infill decoding in Masked Diffusion Models (MDMs) shows promise for mathematical and code reasoning, performance remains highly sensitive to slot infilling order, often yielding substantial output variance. We introduce McDiffuSE, a framework that formulates slot selection as decision making and optimises infilling orders through Monte Carlo Tree Search (MCTS). McDiffuSE uses look-ahead simulations to evaluate partial completions before commitment, systematically exploring the combinatorial space of generation orders. Experiments show an average improvement of 3.2% over autoregressive baselines and 8.0% over baseline plan-and-infill, with notable gains of 19.5% on MBPP and 4.9% on MATH500. Our analysis reveals that while McDiffuSE predominantly follows sequential ordering, incorporating non-sequential generation is essential for maximising performance. We observe that larger exploration constants, rather than increased simulations, are necessary to overcome model confidence biases and discover effective orderings. These findings establish MCTS-based planning as an effective approach for enhancing generation quality in MDMs.
Self-Improving World Modelling with Latent Actions
Feb 05, 2026Internal modelling of the world -- predicting transitions between previous states $X$ and next states $Y$ under actions $Z$ -- is essential to reasoning and planning for LLMs and VLMs. Learning such models typically requires costly action-labelled trajectories. We propose SWIRL, a self-improvement framework that learns from state-only sequences by treating actions as a latent variable and alternating between Forward World Modelling (FWM) $P_θ(Y|X,Z)$ and an Inverse Dynamics Modelling (IDM) $Q_φ(Z|X,Y)$. SWIRL iterates two phases: (1) Variational Information Maximisation, which updates the FWM to generate next states that maximise conditional mutual information with latent actions given prior states, encouraging identifiable consistency; and (2) ELBO Maximisation, which updates the IDM to explain observed transitions, effectively performing coordinate ascent. Both models are trained with reinforcement learning (specifically, GRPO) with the opposite frozen model's log-probability as a reward signal. We provide theoretical learnability guarantees for both updates, and evaluate SWIRL on LLMs and VLMs across multiple environments: single-turn and multi-turn open-world visual dynamics and synthetic textual environments for physics, web, and tool calling. SWIRL achieves gains of 16% on AURORABench, 28% on ByteMorph, 16% on WorldPredictionBench, and 14% on StableToolBench.
Lost in Space? Vision-Language Models Struggle with Relative Camera Pose Estimation
Jan 29, 2026Vision-Language Models (VLMs) perform well in 2D perception and semantic reasoning compared to their limited understanding of 3D spatial structure. We investigate this gap using relative camera pose estimation (RCPE), a fundamental vision task that requires inferring relative camera translation and rotation from a pair of images. We introduce VRRPI-Bench, a benchmark derived from unlabeled egocentric videos with verbalized annotations of relative camera motion, reflecting realistic scenarios with simultaneous translation and rotation around a shared object. We further propose VRRPI-Diag, a diagnostic benchmark that isolates individual motion degrees of freedom. Despite the simplicity of RCPE, most VLMs fail to generalize beyond shallow 2D heuristics, particularly for depth changes and roll transformations along the optical axis. Even state-of-the-art models such as GPT-5 ($0.64$) fall short of classic geometric baselines ($0.97$) and human performance ($0.92$). Moreover, VLMs exhibit difficulty in multi-image reasoning, with inconsistent performance (best $59.7\%$) when integrating spatial cues across frames. Our findings reveal limitations in grounding VLMs in 3D and multi-view spatial reasoning.
Can LLMs Compress (and Decompress)? Evaluating Code Understanding and Execution via Invertibility
Jan 19, 2026LLMs demonstrate strong performance on code benchmarks, yet round-trip code execution reveals limitations in their ability to maintain consistent reasoning across forward and backward execution. We present RoundTripCodeEval (RTCE), a comprehensive benchmark consisting of four distinct code execution reasoning tasks designed to rigorously test round-trip consistency. RTCE provides an execution-free, exact-match evaluation of bijection fidelity, assessing whether models preserve a consistent one-to-one mapping between encoding and decoding operations across various algorithms and directions. We systematically evaluate state-of-the-art Code-LLMs using zero-shot prompting, supervised fine-tuning on execution traces, and self-reflection mechanisms. Each yields modest improvements, but none closes the gap, indicating that current LLMs struggle with true round-trip consistency, which demonstrates that they lack the internal coherence required for trustworthy code reasoning. RTCE surfaces several new and previously unmeasured insights that are not captured by existing I/O-prediction, execution-reasoning, or round-trip natural-language benchmarks. We will release the code and the dataset upon acceptance.
Efficient Seq2seq Coreference Resolution Using Entity Representations
Oct 16, 2025
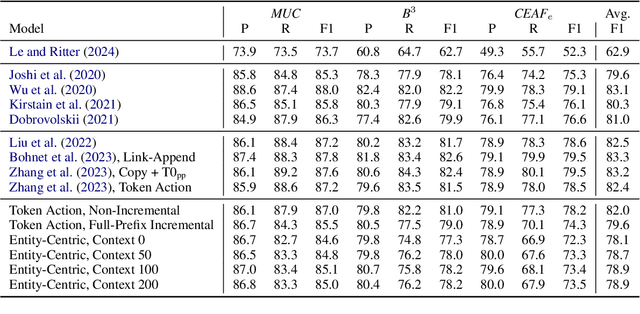
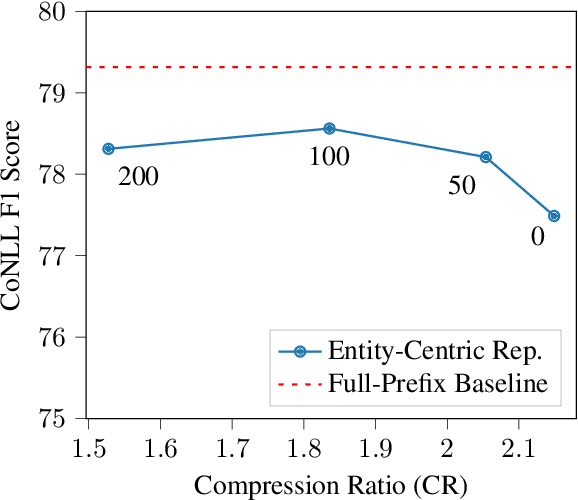
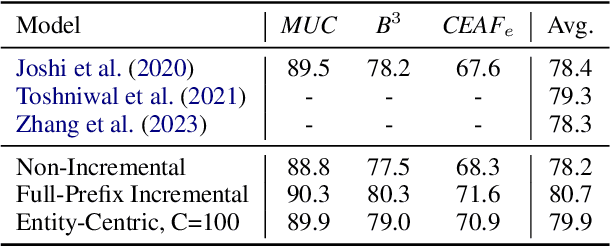
Seq2seq coreference models have introduced a new paradigm for coreference resolution by learning to generate text corresponding to coreference labels, without requiring task-specific parameters. While these models achieve new state-of-the-art performance, they do so at the cost of flexibility and efficiency. In particular, they do not efficiently handle incremental settings such as dialogue, where text must processed sequentially. We propose a compressed representation in order to improve the efficiency of these methods in incremental settings. Our method works by extracting and re-organizing entity-level tokens, and discarding the majority of other input tokens. On OntoNotes, our best model achieves just 0.6 CoNLL F1 points below a full-prefix, incremental baseline while achieving a compression ratio of 1.8. On LitBank, where singleton mentions are annotated, it passes state-of-the-art performance. Our results indicate that discarding a wide portion of tokens in seq2seq resolvers is a feasible strategy for incremental coreference resolution.
ONNX-Net: Towards Universal Representations and Instant Performance Prediction for Neural Architectures
Oct 06, 2025



Neural architecture search (NAS) automates the design process of high-performing architectures, but remains bottlenecked by expensive performance evaluation. Most existing studies that achieve faster evaluation are mostly tied to cell-based search spaces and graph encodings tailored to those individual search spaces, limiting their flexibility and scalability when applied to more expressive search spaces. In this work, we aim to close the gap of individual search space restrictions and search space dependent network representations. We present ONNX-Bench, a benchmark consisting of a collection of neural networks in a unified format based on ONNX files. ONNX-Bench includes all open-source NAS-bench-based neural networks, resulting in a total size of more than 600k {architecture, accuracy} pairs. This benchmark allows creating a shared neural network representation, ONNX-Net, able to represent any neural architecture using natural language descriptions acting as an input to a performance predictor. This text-based encoding can accommodate arbitrary layer types, operation parameters, and heterogeneous topologies, enabling a single surrogate to generalise across all neural architectures rather than being confined to cell-based search spaces. Experiments show strong zero-shot performance across disparate search spaces using only a small amount of pretraining samples, enabling the unprecedented ability to evaluate any neural network architecture instantly.
One More Question is Enough, Expert Question Decomposition (EQD) Model for Domain Quantitative Reasoning
Oct 01, 2025Domain-specific quantitative reasoning remains a major challenge for large language models (LLMs), especially in fields requiring expert knowledge and complex question answering (QA). In this work, we propose Expert Question Decomposition (EQD), an approach designed to balance the use of domain knowledge with computational efficiency. EQD is built on a two-step fine-tuning framework and guided by a reward function that measures the effectiveness of generated sub-questions in improving QA outcomes. It requires only a few thousand training examples and a single A100 GPU for fine-tuning, with inference time comparable to zero-shot prompting. Beyond its efficiency, EQD outperforms state-of-the-art domain-tuned models and advanced prompting strategies. We evaluate EQD in the financial domain, characterized by specialized knowledge and complex quantitative reasoning, across four benchmark datasets. Our method consistently improves QA performance by 0.6% to 10.5% across different LLMs. Our analysis reveals an important insight: in domain-specific QA, a single supporting question often provides greater benefit than detailed guidance steps.