 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferrable Surrogates in Expressive Neural Architecture Search Spaces
Apr 18, 2025Neural architecture search (NAS) faces a challenge in balancing the exploration of expressive, broad search spaces that enable architectural innovation with the need for efficient evaluation of architectures to effectively search such spaces. We investigate surrogate model training for improving search in highly expressive NAS search spaces based on context-free grammars. We show that i) surrogate models trained either using zero-cost-proxy metrics and neural graph features (GRAF) or by fine-tuning an off-the-shelf LM have high predictive power for the performance of architectures both within and across datasets, ii) these surrogates can be used to filter out bad architectures when searching on novel datasets, thereby significantly speeding up search and achieving better final performances, and iii) the surrogates can be further used directly as the search objective for huge speed-ups.
Surprisingly Strong Performance Prediction with Neural Graph Features
Apr 25, 2024



Performance prediction has been a key part of the neural architecture search (NAS) process, allowing to speed up NAS algorithms by avoiding resource-consuming network training. Although many performance predictors correlate well with ground truth performance, they require training data in the form of trained networks. Recently, zero-cost proxies have been proposed as an efficient method to estimate network performance without any training. However, they are still poorly understood, exhibit biases with network properties, and their performance is limited. Inspired by the drawbacks of zero-cost proxies, we propose neural graph features (GRAF), simple to compute properties of architectural graphs. GRAF offers fast and interpretable performance prediction while outperforming zero-cost proxies and other common encodings. In combination with other zero-cost proxies, GRAF outperforms most existing performance predictors at a fraction of the cost.
ProMap: Datasets for Product Mapping in E-commerce
Sep 13, 2023The goal of product mapping is to decide, whether two listings from two different e-shops describe the same products. Existing datasets of matching and non-matching pairs of products, however, often suffer from incomplete product information or contain only very distant non-matching products. Therefore, while predictive models trained on these datasets achieve good results on them, in practice, they are unusable as they cannot distinguish very similar but non-matching pairs of products. This paper introduces two new datasets for product mapping: ProMapCz consisting of 1,495 Czech product pairs and ProMapEn consisting of 1,555 English product pairs of matching and non-matching products manually scraped from two pairs of e-shops. The datasets contain both images and textual descriptions of the products, including their specifications, making them one of the most complete datasets for product mapping. Additionally, the non-matching products were selected in two phases, creating two types of non-matches -- close non-matches and medium non-matches. Even the medium non-matches are pairs of products that are much more similar than non-matches in other datasets -- for example, they still need to have the same brand and similar name and price. After simple data preprocessing, several machine learning algorithms were trained on these and two the other datasets to demonstrate the complexity and completeness of ProMap datasets. ProMap datasets are presented as a golden standard for further research of product mapping filling the gaps in existing ones.
Training Electric Vehicle Charging Controllers with Imitation Learning
Jul 21, 2021

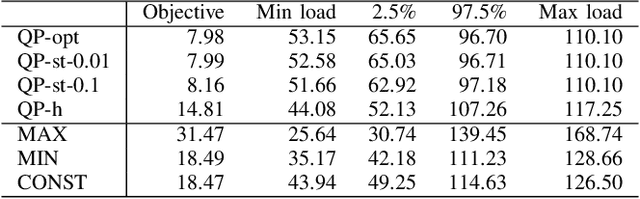
The problem of coordinating the charging of electric vehicles gains more importance as the number of such vehicles grows. In this paper, we develop a method for the training of controllers for the coordination of EV charging. In contrast to most existing works on this topic, we require the controllers to preserve the privacy of the users, therefore we do not allow any communication from the controller to any third party. In order to train the controllers, we use the idea of imitation learning -- we first find an optimum solution for a relaxed version of the problem using quadratic optimization and then train the controllers to imitate this solution. We also investigate the effects of regularization of the optimum solution on the performance of the controllers. The method is evaluated on realistic data and shows improved performance and training speed compared to similar controllers trained using evolutionary algorithms.
Online Parallel Portfolio Selection with Heterogeneous Island Model
Jun 12, 2018
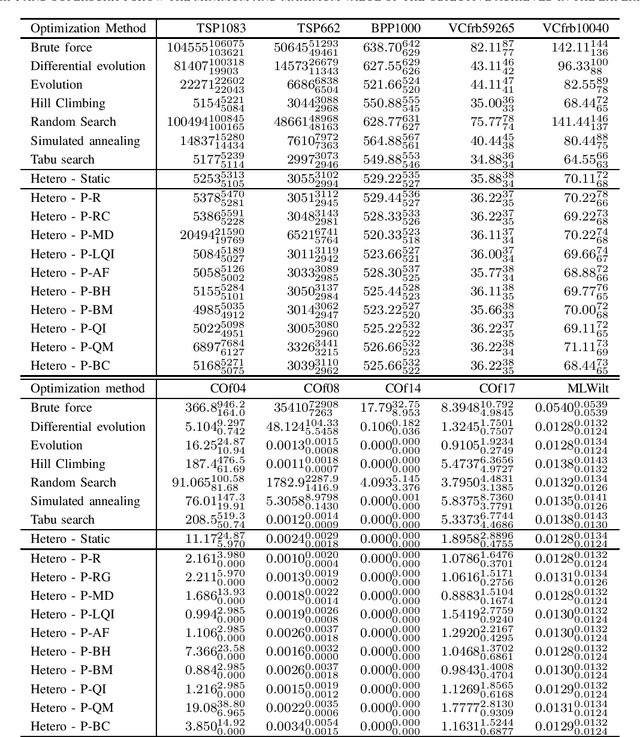
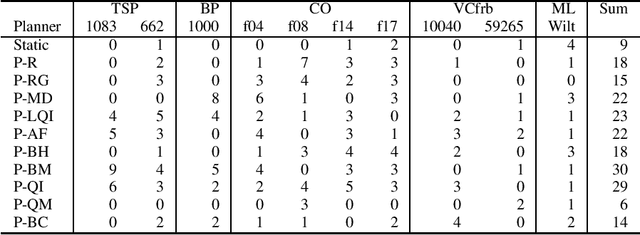
We present an online parallel portfolio selection algorithm based on the island model commonly used for parallelization of evolutionary algorithms. In our case each of the islands runs a different optimization algorithm. The distributed computation is managed by a central planner which periodically changes the running methods during the execution of the algorithm -- less successful methods are removed while new instances of more successful methods are added. We compare different types of planners in the heterogeneous island model among themselves and also to the traditional homogeneous model on a wide set of problems. The tests include experiments with different representations of the individuals and different duration of fitness function evaluations. The results show that heterogeneous models are a more general and universal computational tool compared to homogeneous models.
Controlling the Charging of Electric Vehicles with Neural Networks
Apr 16, 2018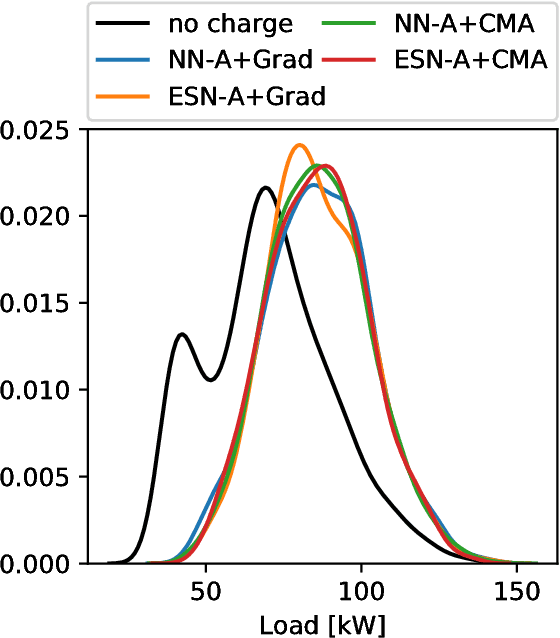
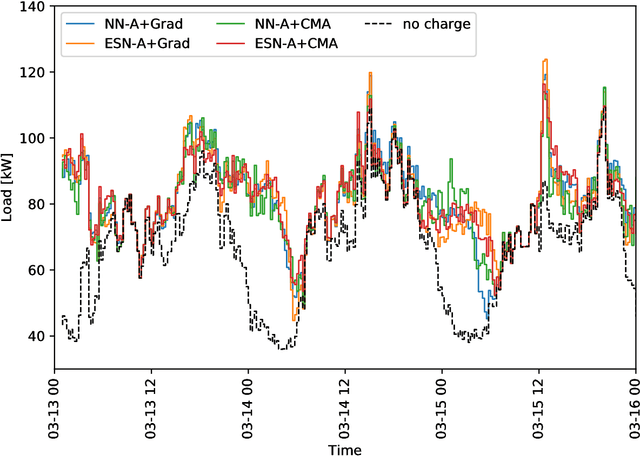
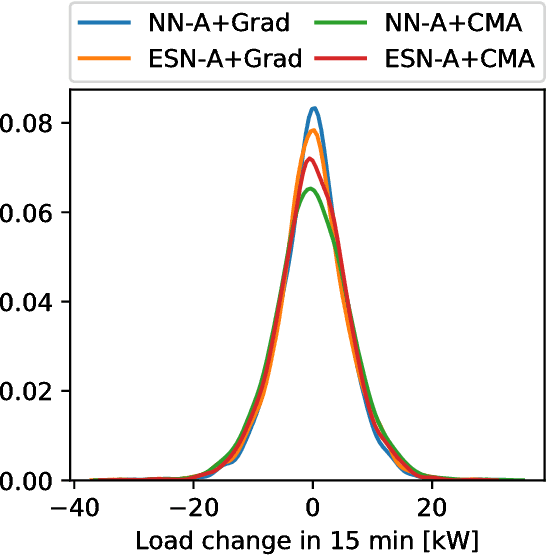
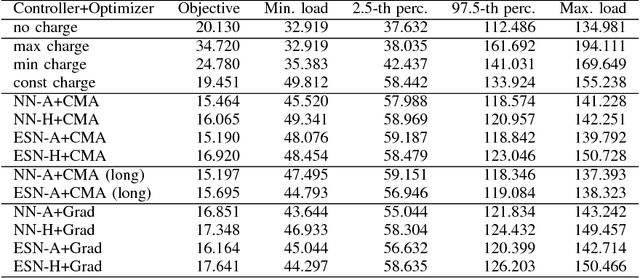
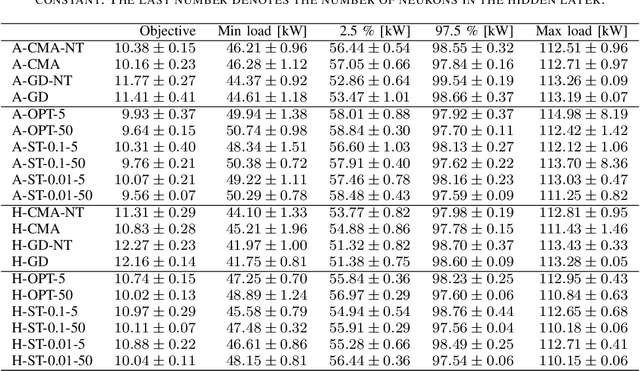
We propose and evaluate controllers for the coordination of the charging of electric vehicles. The controllers are based on neural networks and are completely de-centralized, in the sense that the charging current is completely decided by the controller itself. One of the versions of the controllers does not require any outside communication at all. We test controllers based on two different architectures of neural networks - the feed-forward networks and the echo state networks. The networks are optimized by either an evolutionary algorithm (CMA-ES) or by a gradient-based method. The results of the different architectures and the different optimization algorithms are compared in a realistic scenario. We show that the controllers are able to charge the cars while keeping the peak consumptions almost the same as when no charging is performed. Moreover, the controllers fill the valleys of the consumption thus reducing the difference between the maximum and minimum consumption in the grid.