 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered Quantum Architecture Search for 3D Point Cloud Classification
Mar 20, 2026We introduce layered Quantum Architecture Search (layered-QAS), a strategy inspired by classical network morphism that designs Parametrised Quantum Circuit (PQC) architectures by progressively growing and adapting them. PQCs offer strong expressiveness with relatively few parameters, yet they lack standard architectural layers (e.g., convolution, attention) that encode inductive biases for a given learning task. To assess the effectiveness of our method, we focus on 3D point cloud classification as a challenging yet highly structured problem. Whereas prior work on this task has used PQCs only as feature extractors for classical classifiers, our approach uses the PQC as the main building block of the classification model. Simulations show that our layered-QAS mitigates barren plateau, outperforms quantum-adapted local and evolutionary QAS baselines, and achieves state-of-the-art results among PQC-based methods on the ModelNet dataset.
ONNX-Net: Towards Universal Representations and Instant Performance Prediction for Neural Architectures
Oct 06, 2025



Neural architecture search (NAS) automates the design process of high-performing architectures, but remains bottlenecked by expensive performance evaluation. Most existing studies that achieve faster evaluation are mostly tied to cell-based search spaces and graph encodings tailored to those individual search spaces, limiting their flexibility and scalability when applied to more expressive search spaces. In this work, we aim to close the gap of individual search space restrictions and search space dependent network representations. We present ONNX-Bench, a benchmark consisting of a collection of neural networks in a unified format based on ONNX files. ONNX-Bench includes all open-source NAS-bench-based neural networks, resulting in a total size of more than 600k {architecture, accuracy} pairs. This benchmark allows creating a shared neural network representation, ONNX-Net, able to represent any neural architecture using natural language descriptions acting as an input to a performance predictor. This text-based encoding can accommodate arbitrary layer types, operation parameters, and heterogeneous topologies, enabling a single surrogate to generalise across all neural architectures rather than being confined to cell-based search spaces. Experiments show strong zero-shot performance across disparate search spaces using only a small amount of pretraining samples, enabling the unprecedented ability to evaluate any neural network architecture instantly.
Smooth Model Compression without Fine-Tuning
May 30, 2025Compressing and pruning large machine learning models has become a critical step towards their deployment in real-world applications. Standard pruning and compression techniques are typically designed without taking the structure of the network's weights into account, limiting their effectiveness. We explore the impact of smooth regularization on neural network training and model compression. By applying nuclear norm, first- and second-order derivative penalties of the weights during training, we encourage structured smoothness while preserving predictive performance on par with non-smooth models. We find that standard pruning methods often perform better when applied to these smooth models. Building on this observation, we apply a Singular-Value-Decomposition-based compression method that exploits the underlying smooth structure and approximates the model's weight tensors by smaller low-rank tensors. Our approach enables state-of-the-art compression without any fine-tuning - reaching up to $91\%$ accuracy on a smooth ResNet-18 on CIFAR-10 with $70\%$ fewer parameters.
Transferrable Surrogates in Expressive Neural Architecture Search Spaces
Apr 18, 2025Neural architecture search (NAS) faces a challenge in balancing the exploration of expressive, broad search spaces that enable architectural innovation with the need for efficient evaluation of architectures to effectively search such spaces. We investigate surrogate model training for improving search in highly expressive NAS search spaces based on context-free grammars. We show that i) surrogate models trained either using zero-cost-proxy metrics and neural graph features (GRAF) or by fine-tuning an off-the-shelf LM have high predictive power for the performance of architectures both within and across datasets, ii) these surrogates can be used to filter out bad architectures when searching on novel datasets, thereby significantly speeding up search and achieving better final performances, and iii) the surrogates can be further used directly as the search objective for huge speed-ups.
Surprisingly Strong Performance Prediction with Neural Graph Features
Apr 25, 2024



Performance prediction has been a key part of the neural architecture search (NAS) process, allowing to speed up NAS algorithms by avoiding resource-consuming network training. Although many performance predictors correlate well with ground truth performance, they require training data in the form of trained networks. Recently, zero-cost proxies have been proposed as an efficient method to estimate network performance without any training. However, they are still poorly understood, exhibit biases with network properties, and their performance is limited. Inspired by the drawbacks of zero-cost proxies, we propose neural graph features (GRAF), simple to compute properties of architectural graphs. GRAF offers fast and interpretable performance prediction while outperforming zero-cost proxies and other common encodings. In combination with other zero-cost proxies, GRAF outperforms most existing performance predictors at a fraction of the cost.
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024



Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
An Evaluation of Zero-Cost Proxies -- from Neural Architecture Performance to Model Robustness
Jul 18, 2023Zero-cost proxies are nowadays frequently studied and used to search for neural architectures. They show an impressive ability to predict the performance of architectures by making use of their untrained weights. These techniques allow for immense search speed-ups. So far the joint search for well-performing and robust architectures has received much less attention in the field of NAS. Therefore, the main focus of zero-cost proxies is the clean accuracy of architectures, whereas the model robustness should play an evenly important part. In this paper, we analyze the ability of common zero-cost proxies to serve as performance predictors for robustness in the popular NAS-Bench-201 search space. We are interested in the single prediction task for robustness and the joint multi-objective of clean and robust accuracy. We further analyze the feature importance of the proxies and show that predicting the robustness makes the prediction task from existing zero-cost proxies more challenging. As a result, the joint consideration of several proxies becomes necessary to predict a model's robustness while the clean accuracy can be regressed from a single such feature.
Neural Architecture Design and Robustness: A Dataset
Jun 11, 2023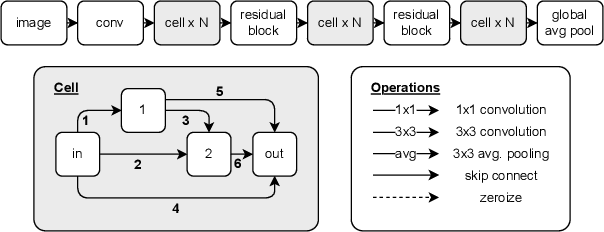
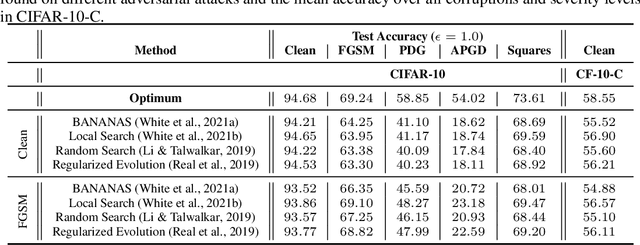
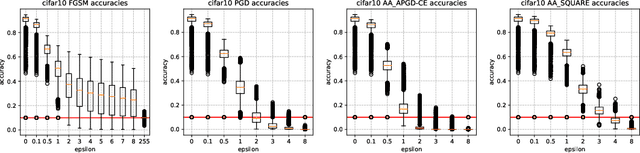

Deep learning models have proven to be successful in a wide range of machine learning tasks. Yet, they are often highly sensitive to perturbations on the input data which can lead to incorrect decisions with high confidence, hampering their deployment for practical use-cases. Thus, finding architectures that are (more) robust against perturbations has received much attention in recent years. Just like the search for well-performing architectures in terms of clean accuracy, this usually involves a tedious trial-and-error process with one additional challenge: the evaluation of a network's robustness is significantly more expensive than its evaluation for clean accuracy. Thus, the aim of this paper is to facilitate better streamlined research on architectural design choices with respect to their impact on robustness as well as, for example, the evaluation of surrogate measures for robustness. We therefore borrow one of the most commonly considered search spaces for neural architecture search for image classification, NAS-Bench-201, which contains a manageable size of 6466 non-isomorphic network designs. We evaluate all these networks on a range of common adversarial attacks and corruption types and introduce a database on neural architecture design and robustness evaluations. We further present three exemplary use cases of this dataset, in which we (i) benchmark robustness measurements based on Jacobian and Hessian matrices for their robustness predictability, (ii) perform neural architecture search on robust accuracies, and (iii) provide an initial analysis of how architectural design choices affect robustness. We find that carefully crafting the topology of a network can have substantial impact on its robustness, where networks with the same parameter count range in mean adversarial robust accuracy from 20%-41%. Code and data is available at http://robustness.vision/.
Learning Where To Look -- Generative NAS is Surprisingly Efficient
Mar 16, 2022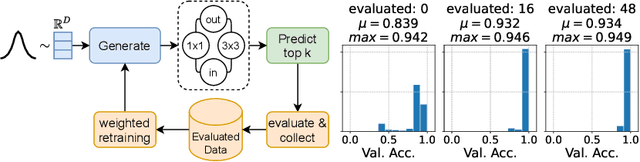



The efficient, automated search for well-performing neural architectures (NAS) has drawn increasing attention in the recent past. Thereby, the predominant research objective is to reduce the necessity of costly evaluations of neural architectures while efficiently exploring large search spaces. To this aim, surrogate models embed architectures in a latent space and predict their performance, while generative models for neural architectures enable optimization-based search within the latent space the generator draws from. Both, surrogate and generative models, have the aim of facilitating query-efficient search in a well-structured latent space. In this paper, we further improve the trade-off between query-efficiency and promising architecture generation by leveraging advantages from both, efficient surrogate models and generative design. To this end, we propose a generative model, paired with a surrogate predictor, that iteratively learns to generate samples from increasingly promising latent subspaces. This approach leads to very effective and efficient architecture search, while keeping the query amount low. In addition, our approach allows in a straightforward manner to jointly optimize for multiple objectives such as accuracy and hardware latency. We show the benefit of this approach not only w.r.t. the optimization of architectures for highest classification accuracy but also in the context of hardware constraints and outperform state-of-the art methods on several NAS benchmarks for single and multiple objectives. We also achieve state-of-the-art performance on ImageNet.
DARTS for Inverse Problems: a Study on Hyperparameter Sensitivity
Aug 12, 2021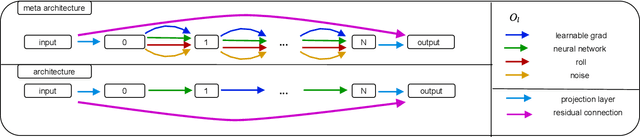
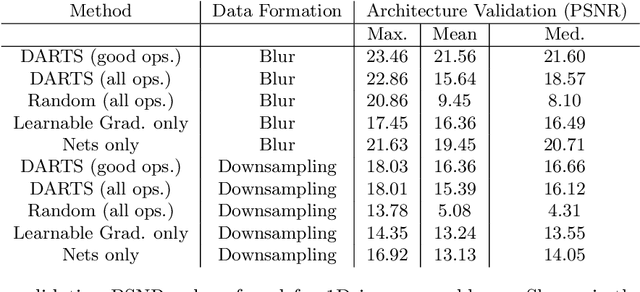
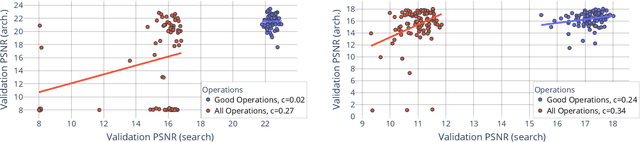
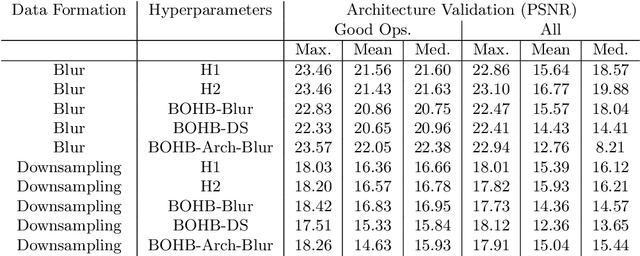
Differentiable architecture search (DARTS) is a widely researched tool for neural architecture search, due to its promising results for image classification. The main benefit of DARTS is the effectiveness achieved through the weight-sharing one-shot paradigm, which allows efficient architecture search. In this work, we investigate DARTS in a systematic case study of inverse problems, which allows us to analyze these potential benefits in a controlled manner. Although we demonstrate that the success of DARTS can be extended from image classification to reconstruction, our experiments yield three fundamental difficulties in the evaluation of DARTS-based methods: First, the results show a large variance in all test cases. Second, the final performance is highly dependent on the hyperparameters of the optimizer. And third, the performance of the weight-sharing architecture used during training does not reflect the final performance of the found architecture well. Thus, we conclude the necessity to 1) report the results of any DARTS-based methods from several runs along with its underlying performance statistics, 2) show the correlation of the training and final architecture performance, and 3) carefully consider if the computational efficiency of DARTS outweighs the costs of hyperparameter optimization and multiple runs.