 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountTRuCoLa: Rule Confidence Learning for Temporal Knowledge Graph Forecasting
Sep 11, 2025We address the task of temporal knowledge graph (TKG) forecasting by introducing a fully explainable method based on temporal rules. Motivated by recent work proposing a strong baseline using recurrent facts, our approach learns four simple types of rules with a confidence function that considers both recency and frequency. Evaluated on nine datasets, our method matches or surpasses the performance of eight state-of-the-art models and two baselines, while providing fully interpretable predictions.
Rethinking BPS: A Utility-Based Evaluation Framework
May 28, 2025Business process simulation (BPS) is a key tool for analyzing and optimizing organizational workflows, supporting decision-making by estimating the impact of process changes. The reliability of such estimates depends on the ability of a BPS model to accurately mimic the process under analysis, making rigorous accuracy evaluation essential. However, the state-of-the-art approach to evaluating BPS models has two key limitations. First, it treats simulation as a forecasting problem, testing whether models can predict unseen future events. This fails to assess how well a model captures the as-is process, particularly when process behavior changes from train to test period. Thus, it becomes difficult to determine whether poor results stem from an inaccurate model or the inherent complexity of the data, such as unpredictable drift. Second, the evaluation approach strongly relies on Earth Mover's Distance-based metrics, which can obscure temporal patterns and thus yield misleading conclusions about simulation quality. To address these issues, we propose a novel framework that evaluates simulation quality based on its ability to generate representative process behavior. Instead of comparing simulated logs to future real-world executions, we evaluate whether predictive process monitoring models trained on simulated data perform comparably to those trained on real data for downstream analysis tasks. Empirical results show that our framework not only helps identify sources of discrepancies but also distinguishes between model accuracy and data complexity, offering a more meaningful way to assess BPS quality.
A Divide-and-Conquer Approach for Modeling Arrival Times in Business Process Simulation
May 28, 2025Business Process Simulation (BPS) is a critical tool for analyzing and improving organizational processes by estimating the impact of process changes. A key component of BPS is the case-arrival model, which determines the pattern of new case entries into a process. Although accurate case-arrival modeling is essential for reliable simulations, as it influences waiting and overall cycle times, existing approaches often rely on oversimplified static distributions of inter-arrival times. These approaches fail to capture the dynamic and temporal complexities inherent in organizational environments, leading to less accurate and reliable outcomes. To address this limitation, we propose Auto Time Kernel Density Estimation (AT-KDE), a divide-and-conquer approach that models arrival times of processes by incorporating global dynamics, day-of-week variations, and intraday distributional changes, ensuring both precision and scalability. Experiments conducted across 20 diverse processes demonstrate that AT-KDE is far more accurate and robust than existing approaches while maintaining sensible execution time efficiency.
Unreflected Use of Tabular Data Repositories Can Undermine Research Quality
Mar 12, 2025Data repositories have accumulated a large number of tabular datasets from various domains. Machine Learning researchers are actively using these datasets to evaluate novel approaches. Consequently, data repositories have an important standing in tabular data research. They not only host datasets but also provide information on how to use them in supervised learning tasks. In this paper, we argue that, despite great achievements in usability, the unreflected usage of datasets from data repositories may have led to reduced research quality and scientific rigor. We present examples from prominent recent studies that illustrate the problematic use of datasets from OpenML, a large data repository for tabular data. Our illustrations help users of data repositories avoid falling into the traps of (1) using suboptimal model selection strategies, (2) overlooking strong baselines, and (3) inappropriate preprocessing. In response, we discuss possible solutions for how data repositories can prevent the inappropriate use of datasets and become the cornerstones for improved overall quality of empirical research studies.
A*Net and NBFNet Learn Negative Patterns on Knowledge Graphs
Dec 06, 2024In this technical report, we investigate the predictive performance differences of a rule-based approach and the GNN architectures NBFNet and A*Net with respect to knowledge graph completion. For the two most common benchmarks, we find that a substantial fraction of the performance difference can be explained by one unique negative pattern on each dataset that is hidden from the rule-based approach. Our findings add a unique perspective on the performance difference of different model classes for knowledge graph completion: Models can achieve a predictive performance advantage by penalizing scores of incorrect facts opposed to providing high scores for correct facts.
Reevaluation of Inductive Link Prediction
Sep 30, 2024Within this paper, we show that the evaluation protocol currently used for inductive link prediction is heavily flawed as it relies on ranking the true entity in a small set of randomly sampled negative entities. Due to the limited size of the set of negatives, a simple rule-based baseline can achieve state-of-the-art results, which simply ranks entities higher based on the validity of their type. As a consequence of these insights, we reevaluate current approaches for inductive link prediction on several benchmarks using the link prediction protocol usually applied to the transductive setting. As some inductive methods suffer from scalability issues when evaluated in this setting, we propose and apply additionally an improved sampling protocol, which does not suffer from the problem mentioned above. The results of our evaluation differ drastically from the results reported in so far.
* Published in RuleML+RR 2024
Fact Probability Vector Based Goal Recognition
Aug 26, 2024



We present a new approach to goal recognition that involves comparing observed facts with their expected probabilities. These probabilities depend on a specified goal g and initial state s0. Our method maps these probabilities and observed facts into a real vector space to compute heuristic values for potential goals. These values estimate the likelihood of a given goal being the true objective of the observed agent. As obtaining exact expected probabilities for observed facts in an observation sequence is often practically infeasible, we propose and empirically validate a method for approximating these probabilities. Our empirical results show that the proposed approach offers improved goal recognition precision compared to state-of-the-art techniques while reducing computational complexity.
AgentSimulator: An Agent-based Approach for Data-driven Business Process Simulation
Aug 16, 2024



Business process simulation (BPS) is a versatile technique for estimating process performance across various scenarios. Traditionally, BPS approaches employ a control-flow-first perspective by enriching a process model with simulation parameters. Although such approaches can mimic the behavior of centrally orchestrated processes, such as those supported by workflow systems, current control-flow-first approaches cannot faithfully capture the dynamics of real-world processes that involve distinct resource behavior and decentralized decision-making. Recognizing this issue, this paper introduces AgentSimulator, a resource-first BPS approach that discovers a multi-agent system from an event log, modeling distinct resource behaviors and interaction patterns to simulate the underlying process. Our experiments show that AgentSimulator achieves state-of-the-art simulation accuracy with significantly lower computation times than existing approaches while providing high interpretability and adaptability to different types of process-execution scenarios.
SYMPOL: Symbolic Tree-Based On-Policy Reinforcement Learning
Aug 16, 2024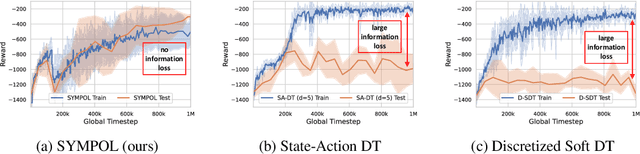



Reinforcement learning (RL) has seen significant success across various domains, but its adoption is often limited by the black-box nature of neural network policies, making them difficult to interpret. In contrast, symbolic policies allow representing decision-making strategies in a compact and interpretable way. However, learning symbolic policies directly within on-policy methods remains challenging. In this paper, we introduce SYMPOL, a novel method for SYMbolic tree-based on-POLicy RL. SYMPOL employs a tree-based model integrated with a policy gradient method, enabling the agent to learn and adapt its actions while maintaining a high level of interpretability. We evaluate SYMPOL on a set of benchmark RL tasks, demonstrating its superiority over alternative tree-based RL approaches in terms of performance and interpretability. To the best of our knowledge, this is the first method, that allows a gradient-based end-to-end learning of interpretable, axis-aligned decision trees on-policy. Therefore, SYMPOL can become the foundation for a new class of interpretable RL based on decision trees. Our implementation is available under: https://github.com/s-marton/SYMPOL
Analytical Uncertainty-Based Loss Weighting in Multi-Task Learning
Aug 15, 2024With the rise of neural networks in various domains, multi-task learning (MTL) gained significant relevance. A key challenge in MTL is balancing individual task losses during neural network training to improve performance and efficiency through knowledge sharing across tasks. To address these challenges, we propose a novel task-weighting method by building on the most prevalent approach of Uncertainty Weighting and computing analytically optimal uncertainty-based weights, normalized by a softmax function with tunable temperature. Our approach yields comparable results to the combinatorially prohibitive, brute-force approach of Scalarization while offering a more cost-effective yet high-performing alternative. We conduct an extensive benchmark on various datasets and architectures. Our method consistently outperforms six other common weighting methods. Furthermore, we report noteworthy experimental findings for the practical application of MTL. For example, larger networks diminish the influence of weighting methods, and tuning the weight decay has a low impact compared to the learning rate.