 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Metafeatures to Explain Model Differences on Tabular Data
May 28, 2026With the rise of tabular foundation models alongside traditional models still performing well on many tasks, choosing the right model for a tabular dataset remains difficult. We investigate whether dataset meta-features can explain performance gaps between model families on tabular prediction tasks. Using the TabArena benchmark results, we analyze dataset-level performance gaps and relate them to model-agnostic dataset descriptors. After strict statistical tests with false discovery control, we find that (1) for neural network vs. tree gaps, no meta-feature survives false discovery control, (2) for non-foundation vs. foundation model gaps, one association is robust but does not generalize when tested in leave-one-dataset-out prediction, and (3) for TabICLv2 vs. TabPFN-2.6, one robust association also improves held-out prediction. Furthermore, we conduct a leave-one-dataset-out analysis and find that meta-feature predictors fail to improve meaningfully over a simple baseline. Overall, our results show the heterogeneity of tabular datasets and that global meta-feature approaches are not robust enough to offer explanations on the 51 TabArena datasets.
Learning Tree-Based Models with Gradient Descent
Mar 11, 2026Tree-based models are widely recognized for their interpretability and have proven effective in various application domains, particularly in high-stakes domains. However, learning decision trees (DTs) poses a significant challenge due to their combinatorial complexity and discrete, non-differentiable nature. As a result, traditional methods such as CART, which rely on greedy search procedures, remain the most widely used approaches. These methods make locally optimal decisions at each node, constraining the search space and often leading to suboptimal tree structures. Additionally, their demand for custom training methods precludes a seamless integration into modern machine learning (ML) approaches. In this thesis, we propose a novel method for learning hard, axis-aligned DTs through gradient descent. Our approach utilizes backpropagation with a straight-through operator on a dense DT representation, enabling the joint optimization of all tree parameters, thereby addressing the two primary limitations of traditional DT algorithms. First, gradient-based training is not constrained by the sequential selection of locally optimal splits but, instead, jointly optimizes all tree parameters. Second, by leveraging gradient descent for optimization, our approach seamlessly integrates into existing ML approaches e.g., for multimodal and reinforcement learning tasks, which inherently rely on gradient descent. These advancements allow us to achieve state-of-the-art results across multiple domains, including interpretable DTs rees for small tabular datasets, advanced models for complex tabular data, multimodal learning, and interpretable reinforcement learning without information loss. By bridging the gap between DTs and gradient-based optimization, our method significantly enhances the performance and applicability of tree-based models across various ML domains.
Which LIME should I trust? Concepts, Challenges, and Solutions
Mar 31, 2025As neural networks become dominant in essential systems, Explainable Artificial Intelligence (XAI) plays a crucial role in fostering trust and detecting potential misbehavior of opaque models. LIME (Local Interpretable Model-agnostic Explanations) is among the most prominent model-agnostic approaches, generating explanations by approximating the behavior of black-box models around specific instances. Despite its popularity, LIME faces challenges related to fidelity, stability, and applicability to domain-specific problems. Numerous adaptations and enhancements have been proposed to address these issues, but the growing number of developments can be overwhelming, complicating efforts to navigate LIME-related research. To the best of our knowledge, this is the first survey to comprehensively explore and collect LIME's foundational concepts and known limitations. We categorize and compare its various enhancements, offering a structured taxonomy based on intermediate steps and key issues. Our analysis provides a holistic overview of advancements in LIME, guiding future research and helping practitioners identify suitable approaches. Additionally, we provide a continuously updated interactive website (https://patrick-knab.github.io/which-lime-to-trust/), offering a concise and accessible overview of the survey.
Decision Trees That Remember: Gradient-Based Learning of Recurrent Decision Trees with Memory
Feb 06, 2025Neural architectures such as Recurrent Neural Networks (RNNs), Transformers, and State-Space Models have shown great success in handling sequential data by learning temporal dependencies. Decision Trees (DTs), on the other hand, remain a widely used class of models for structured tabular data but are typically not designed to capture sequential patterns directly. Instead, DT-based approaches for time-series data often rely on feature engineering, such as manually incorporating lag features, which can be suboptimal for capturing complex temporal dependencies. To address this limitation, we introduce ReMeDe Trees, a novel recurrent DT architecture that integrates an internal memory mechanism, similar to RNNs, to learn long-term dependencies in sequential data. Our model learns hard, axis-aligned decision rules for both output generation and state updates, optimizing them efficiently via gradient descent. We provide a proof-of-concept study on synthetic benchmarks to demonstrate the effectiveness of our approach.
Aligning Visual and Semantic Interpretability through Visually Grounded Concept Bottleneck Models
Dec 16, 2024The performance of neural networks increases steadily, but our understanding of their decision-making lags behind. Concept Bottleneck Models (CBMs) address this issue by incorporating human-understandable concepts into the prediction process, thereby enhancing transparency and interpretability. Since existing approaches often rely on large language models (LLMs) to infer concepts, their results may contain inaccurate or incomplete mappings, especially in complex visual domains. We introduce visually Grounded Concept Bottleneck Models (GCBM), which derive concepts on the image level using segmentation and detection foundation models. Our method generates inherently interpretable concepts, which can be grounded in the input image using attribution methods, allowing interpretations to be traced back to the image plane. We show that GCBM concepts are meaningful interpretability vehicles, which aid our understanding of model embedding spaces. GCBMs allow users to control the granularity, number, and naming of concepts, providing flexibility and are easily adaptable to new datasets without pre-training or additional data needed. Prediction accuracy is within 0.3-6% of the linear probe and GCBMs perform especially well for fine-grained classification interpretability on CUB, due to their dataset specificity. Our code is available on https://github.com/KathPra/GCBM.
Interpreting Outliers in Time Series Data through Decoding Autoencoder
Sep 03, 2024



Outlier detection is a crucial analytical tool in various fields. In critical systems like manufacturing, malfunctioning outlier detection can be costly and safety-critical. Therefore, there is a significant need for explainable artificial intelligence (XAI) when deploying opaque models in such environments. This study focuses on manufacturing time series data from a German automotive supply industry. We utilize autoencoders to compress the entire time series and then apply anomaly detection techniques to its latent features. For outlier interpretation, we (i) adopt widely used XAI techniques to the autoencoder's encoder. Additionally, (ii) we propose AEE, Aggregated Explanatory Ensemble, a novel approach that fuses explanations of multiple XAI techniques into a single, more expressive interpretation. For evaluation of explanations, (iii) we propose a technique to measure the quality of encoder explanations quantitatively. Furthermore, we qualitatively assess the effectiveness of outlier explanations with domain expertise.
SYMPOL: Symbolic Tree-Based On-Policy Reinforcement Learning
Aug 16, 2024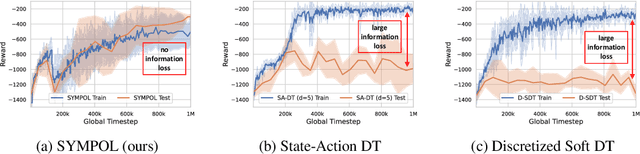



Reinforcement learning (RL) has seen significant success across various domains, but its adoption is often limited by the black-box nature of neural network policies, making them difficult to interpret. In contrast, symbolic policies allow representing decision-making strategies in a compact and interpretable way. However, learning symbolic policies directly within on-policy methods remains challenging. In this paper, we introduce SYMPOL, a novel method for SYMbolic tree-based on-POLicy RL. SYMPOL employs a tree-based model integrated with a policy gradient method, enabling the agent to learn and adapt its actions while maintaining a high level of interpretability. We evaluate SYMPOL on a set of benchmark RL tasks, demonstrating its superiority over alternative tree-based RL approaches in terms of performance and interpretability. To the best of our knowledge, this is the first method, that allows a gradient-based end-to-end learning of interpretable, axis-aligned decision trees on-policy. Therefore, SYMPOL can become the foundation for a new class of interpretable RL based on decision trees. Our implementation is available under: https://github.com/s-marton/SYMPOL
A Data-Centric Perspective on Evaluating Machine Learning Models for Tabular Data
Jul 02, 2024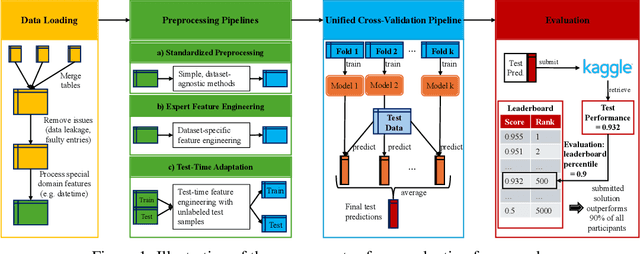
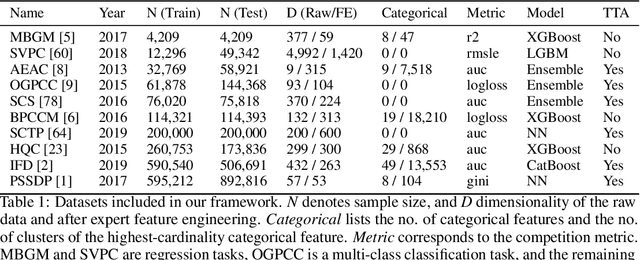

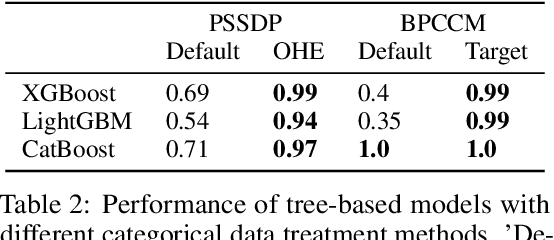
Tabular data is prevalent in real-world machine learning applications, and new models for supervised learning of tabular data are frequently proposed. Comparative studies assessing the performance of models typically consist of model-centric evaluation setups with overly standardized data preprocessing. This paper demonstrates that such model-centric evaluations are biased, as real-world modeling pipelines often require dataset-specific preprocessing and feature engineering. Therefore, we propose a data-centric evaluation framework. We select 10 relevant datasets from Kaggle competitions and implement expert-level preprocessing pipelines for each dataset. We conduct experiments with different preprocessing pipelines and hyperparameter optimization (HPO) regimes to quantify the impact of model selection, HPO, feature engineering, and test-time adaptation. Our main findings are: 1. After dataset-specific feature engineering, model rankings change considerably, performance differences decrease, and the importance of model selection reduces. 2. Recent models, despite their measurable progress, still significantly benefit from manual feature engineering. This holds true for both tree-based models and neural networks. 3. While tabular data is typically considered static, samples are often collected over time, and adapting to distribution shifts can be important even in supposedly static data. These insights suggest that research efforts should be directed toward a data-centric perspective, acknowledging that tabular data requires feature engineering and often exhibits temporal characteristics.
DSEG-LIME - Improving Image Explanation by Hierarchical Data-Driven Segmentation
Mar 12, 2024



Explainable Artificial Intelligence is critical in unraveling decision-making processes in complex machine learning models. LIME (Local Interpretable Model-agnostic Explanations) is a well-known XAI framework for image analysis. It utilizes image segmentation to create features to identify relevant areas for classification. Consequently, poor segmentation can compromise the consistency of the explanation and undermine the importance of the segments, affecting the overall interpretability. Addressing these challenges, we introduce DSEG-LIME (Data-Driven Segmentation LIME), featuring: i) a data-driven segmentation for human-recognized feature generation, and ii) a hierarchical segmentation procedure through composition. We benchmark DSEG-LIME on pre-trained models with images from the ImageNet dataset - scenarios without domain-specific knowledge. The analysis includes a quantitative evaluation using established XAI metrics, complemented by a qualitative assessment through a user study. Our findings demonstrate that DSEG outperforms in most of the XAI metrics and enhances the alignment of explanations with human-recognized concepts, significantly improving interpretability. The code is available under: https://github. com/patrick-knab/DSEG-LIME
GRANDE: Gradient-Based Decision Tree Ensembles
Sep 29, 2023
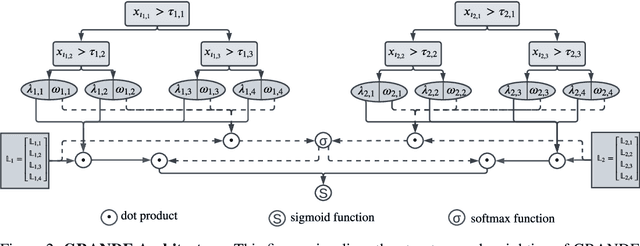


Despite the success of deep learning for text and image data, tree-based ensemble models are still state-of-the-art for machine learning with heterogeneous tabular data. However, there is a significant need for tabular-specific gradient-based methods due to their high flexibility. In this paper, we propose $\text{GRANDE}$, $\text{GRA}$die$\text{N}$t-Based $\text{D}$ecision Tree $\text{E}$nsembles, a novel approach for learning hard, axis-aligned decision tree ensembles using end-to-end gradient descent. GRANDE is based on a dense representation of tree ensembles, which affords to use backpropagation with a straight-through operator to jointly optimize all model parameters. Our method combines axis-aligned splits, which is a useful inductive bias for tabular data, with the flexibility of gradient-based optimization. Furthermore, we introduce an advanced instance-wise weighting that facilitates learning representations for both, simple and complex relations, within a single model. We conducted an extensive evaluation on a predefined benchmark with 19 classification datasets and demonstrate that our method outperforms existing gradient-boosting and deep learning frameworks on most datasets.