 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Exploration of Large Language Models by Optimal Exploitation
Jan 15, 2025Exploration is a crucial skill for self-improvement and open-ended problem-solving. However, it remains uncertain whether large language models can effectively explore the state-space. Existing evaluations predominantly focus on the trade-off between exploration and exploitation, often assessed in multi-armed bandit problems. In contrast, this work isolates exploration as the sole objective, tasking the agent with delivering information that enhances future returns. For the evaluation, we propose to decompose missing rewards into exploration and exploitation components by measuring the optimal achievable return for the states already explored. Our experiments with various LLMs reveal that most models struggle to sufficiently explore the state-space and that weak exploration is insufficient. We observe a positive correlation between model size and exploration performance, with larger models demonstrating superior capabilities. Furthermore, we show that our decomposition provides insights into differences in behaviors driven by agent instructions during prompt engineering, offering a valuable tool for refining LLM performance in exploratory tasks.
SYMPOL: Symbolic Tree-Based On-Policy Reinforcement Learning
Aug 16, 2024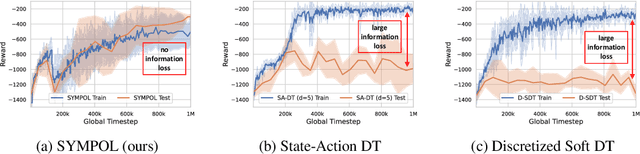



Reinforcement learning (RL) has seen significant success across various domains, but its adoption is often limited by the black-box nature of neural network policies, making them difficult to interpret. In contrast, symbolic policies allow representing decision-making strategies in a compact and interpretable way. However, learning symbolic policies directly within on-policy methods remains challenging. In this paper, we introduce SYMPOL, a novel method for SYMbolic tree-based on-POLicy RL. SYMPOL employs a tree-based model integrated with a policy gradient method, enabling the agent to learn and adapt its actions while maintaining a high level of interpretability. We evaluate SYMPOL on a set of benchmark RL tasks, demonstrating its superiority over alternative tree-based RL approaches in terms of performance and interpretability. To the best of our knowledge, this is the first method, that allows a gradient-based end-to-end learning of interpretable, axis-aligned decision trees on-policy. Therefore, SYMPOL can become the foundation for a new class of interpretable RL based on decision trees. Our implementation is available under: https://github.com/s-marton/SYMPOL
Dynamic Interval Restrictions on Action Spaces in Deep Reinforcement Learning for Obstacle Avoidance
Jun 13, 2023Deep reinforcement learning algorithms typically act on the same set of actions. However, this is not sufficient for a wide range of real-world applications where different subsets are available at each step. In this thesis, we consider the problem of interval restrictions as they occur in pathfinding with dynamic obstacles. When actions that lead to collisions are avoided, the continuous action space is split into variable parts. Recent research learns with strong assumptions on the number of intervals, is limited to convex subsets, and the available actions are learned from the observations. Therefore, we propose two approaches that are independent of the state of the environment by extending parameterized reinforcement learning and ConstraintNet to handle an arbitrary number of intervals. We demonstrate their performance in an obstacle avoidance task and compare the methods to penalties, projection, replacement, as well as discrete and continuous masking from the literature. The results suggest that discrete masking of action-values is the only effective method when constraints did not emerge during training. When restrictions are learned, the decision between projection, masking, and our ConstraintNet modification seems to depend on the task at hand. We compare the results with varying complexity and give directions for future work.