 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed, but Not Always Improved: Challenging the Benefit of Background Knowledge in GNNs
May 16, 2025In complex and low-data domains such as biomedical research, incorporating background knowledge (BK) graphs, such as protein-protein interaction (PPI) networks, into graph-based machine learning pipelines is a promising research direction. However, while BK is often assumed to improve model performance, its actual contribution and the impact of imperfect knowledge remain poorly understood. In this work, we investigate the role of BK in an important real-world task: cancer subtype classification. Surprisingly, we find that (i) state-of-the-art GNNs using BK perform no better than uninformed models like linear regression, and (ii) their performance remains largely unchanged even when the BK graph is heavily perturbed. To understand these unexpected results, we introduce an evaluation framework, which employs (i) a synthetic setting where the BK is clearly informative and (ii) a set of perturbations that simulate various imperfections in BK graphs. With this, we test the robustness of BK-aware models in both synthetic and real-world biomedical settings. Our findings reveal that careful alignment of GNN architectures and BK characteristics is necessary but holds the potential for significant performance improvements.
Unreflected Use of Tabular Data Repositories Can Undermine Research Quality
Mar 12, 2025


Data repositories have accumulated a large number of tabular datasets from various domains. Machine Learning researchers are actively using these datasets to evaluate novel approaches. Consequently, data repositories have an important standing in tabular data research. They not only host datasets but also provide information on how to use them in supervised learning tasks. In this paper, we argue that, despite great achievements in usability, the unreflected usage of datasets from data repositories may have led to reduced research quality and scientific rigor. We present examples from prominent recent studies that illustrate the problematic use of datasets from OpenML, a large data repository for tabular data. Our illustrations help users of data repositories avoid falling into the traps of (1) using suboptimal model selection strategies, (2) overlooking strong baselines, and (3) inappropriate preprocessing. In response, we discuss possible solutions for how data repositories can prevent the inappropriate use of datasets and become the cornerstones for improved overall quality of empirical research studies.
SYMPOL: Symbolic Tree-Based On-Policy Reinforcement Learning
Aug 16, 2024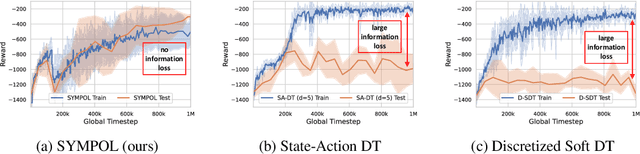



Reinforcement learning (RL) has seen significant success across various domains, but its adoption is often limited by the black-box nature of neural network policies, making them difficult to interpret. In contrast, symbolic policies allow representing decision-making strategies in a compact and interpretable way. However, learning symbolic policies directly within on-policy methods remains challenging. In this paper, we introduce SYMPOL, a novel method for SYMbolic tree-based on-POLicy RL. SYMPOL employs a tree-based model integrated with a policy gradient method, enabling the agent to learn and adapt its actions while maintaining a high level of interpretability. We evaluate SYMPOL on a set of benchmark RL tasks, demonstrating its superiority over alternative tree-based RL approaches in terms of performance and interpretability. To the best of our knowledge, this is the first method, that allows a gradient-based end-to-end learning of interpretable, axis-aligned decision trees on-policy. Therefore, SYMPOL can become the foundation for a new class of interpretable RL based on decision trees. Our implementation is available under: https://github.com/s-marton/SYMPOL
A Data-Centric Perspective on Evaluating Machine Learning Models for Tabular Data
Jul 02, 2024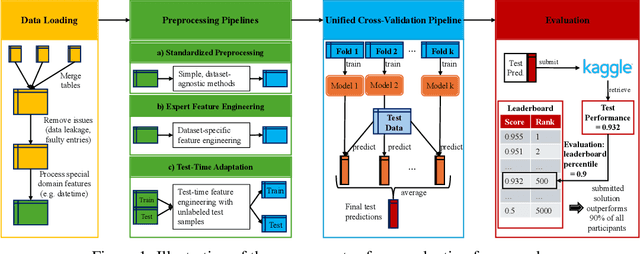
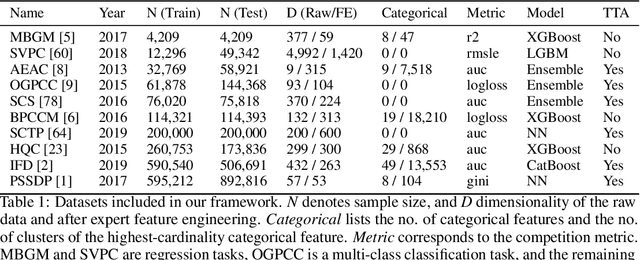

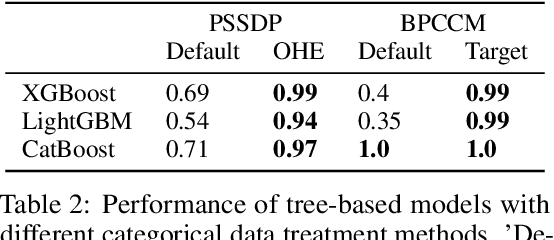
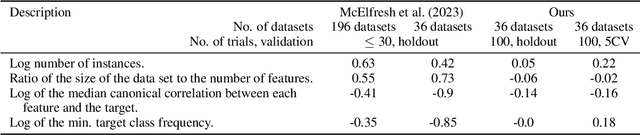
Tabular data is prevalent in real-world machine learning applications, and new models for supervised learning of tabular data are frequently proposed. Comparative studies assessing the performance of models typically consist of model-centric evaluation setups with overly standardized data preprocessing. This paper demonstrates that such model-centric evaluations are biased, as real-world modeling pipelines often require dataset-specific preprocessing and feature engineering. Therefore, we propose a data-centric evaluation framework. We select 10 relevant datasets from Kaggle competitions and implement expert-level preprocessing pipelines for each dataset. We conduct experiments with different preprocessing pipelines and hyperparameter optimization (HPO) regimes to quantify the impact of model selection, HPO, feature engineering, and test-time adaptation. Our main findings are: 1. After dataset-specific feature engineering, model rankings change considerably, performance differences decrease, and the importance of model selection reduces. 2. Recent models, despite their measurable progress, still significantly benefit from manual feature engineering. This holds true for both tree-based models and neural networks. 3. While tabular data is typically considered static, samples are often collected over time, and adapting to distribution shifts can be important even in supposedly static data. These insights suggest that research efforts should be directed toward a data-centric perspective, acknowledging that tabular data requires feature engineering and often exhibits temporal characteristics.
Enabling Mixed Effects Neural Networks for Diverse, Clustered Data Using Monte Carlo Methods
Jul 01, 2024



Neural networks often assume independence among input data samples, disregarding correlations arising from inherent clustering patterns in real-world datasets (e.g., due to different sites or repeated measurements). Recently, mixed effects neural networks (MENNs) which separate cluster-specific 'random effects' from cluster-invariant 'fixed effects' have been proposed to improve generalization and interpretability for clustered data. However, existing methods only allow for approximate quantification of cluster effects and are limited to regression and binary targets with only one clustering feature. We present MC-GMENN, a novel approach employing Monte Carlo methods to train Generalized Mixed Effects Neural Networks. We empirically demonstrate that MC-GMENN outperforms existing mixed effects deep learning models in terms of generalization performance, time complexity, and quantification of inter-cluster variance. Additionally, MC-GMENN is applicable to a wide range of datasets, including multi-class classification tasks with multiple high-cardinality categorical features. For these datasets, we show that MC-GMENN outperforms conventional encoding and embedding methods, simultaneously offering a principled methodology for interpreting the effects of clustering patterns.
GRANDE: Gradient-Based Decision Tree Ensembles
Sep 29, 2023
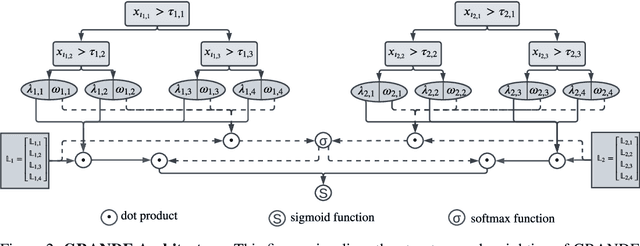


Despite the success of deep learning for text and image data, tree-based ensemble models are still state-of-the-art for machine learning with heterogeneous tabular data. However, there is a significant need for tabular-specific gradient-based methods due to their high flexibility. In this paper, we propose $\text{GRANDE}$, $\text{GRA}$die$\text{N}$t-Based $\text{D}$ecision Tree $\text{E}$nsembles, a novel approach for learning hard, axis-aligned decision tree ensembles using end-to-end gradient descent. GRANDE is based on a dense representation of tree ensembles, which affords to use backpropagation with a straight-through operator to jointly optimize all model parameters. Our method combines axis-aligned splits, which is a useful inductive bias for tabular data, with the flexibility of gradient-based optimization. Furthermore, we introduce an advanced instance-wise weighting that facilitates learning representations for both, simple and complex relations, within a single model. We conducted an extensive evaluation on a predefined benchmark with 19 classification datasets and demonstrate that our method outperforms existing gradient-boosting and deep learning frameworks on most datasets.
On the Aggregation of Rules for Knowledge Graph Completion
Sep 01, 2023



Rule learning approaches for knowledge graph completion are efficient, interpretable and competitive to purely neural models. The rule aggregation problem is concerned with finding one plausibility score for a candidate fact which was simultaneously predicted by multiple rules. Although the problem is ubiquitous, as data-driven rule learning can result in noisy and large rulesets, it is underrepresented in the literature and its theoretical foundations have not been studied before in this context. In this work, we demonstrate that existing aggregation approaches can be expressed as marginal inference operations over the predicting rules. In particular, we show that the common Max-aggregation strategy, which scores candidates based on the rule with the highest confidence, has a probabilistic interpretation. Finally, we propose an efficient and overlooked baseline which combines the previous strategies and is competitive to computationally more expensive approaches.
Towards Machine Learning-based Fish Stock Assessment
Aug 07, 2023



The accurate assessment of fish stocks is crucial for sustainable fisheries management. However, existing statistical stock assessment models can have low forecast performance of relevant stock parameters like recruitment or spawning stock biomass, especially in ecosystems that are changing due to global warming and other anthropogenic stressors. In this paper, we investigate the use of machine learning models to improve the estimation and forecast of such stock parameters. We propose a hybrid model that combines classical statistical stock assessment models with supervised ML, specifically gradient boosted trees. Our hybrid model leverages the initial estimate provided by the classical model and uses the ML model to make a post-hoc correction to improve accuracy. We experiment with five different stocks and find that the forecast accuracy of recruitment and spawning stock biomass improves considerably in most cases.
Learning Decision Trees with Gradient Descent
May 05, 2023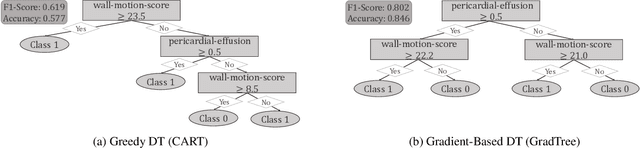

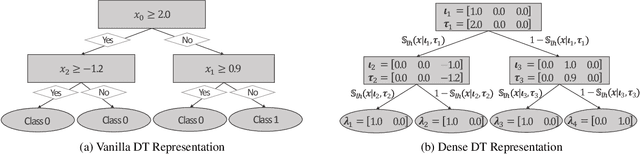
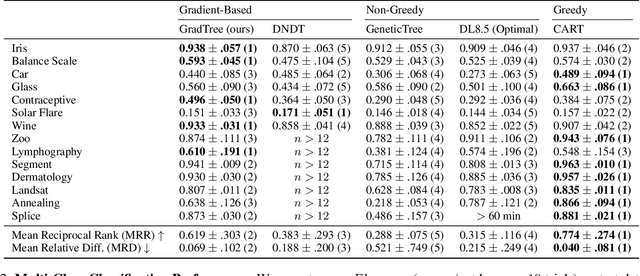
Decision Trees (DTs) are commonly used for many machine learning tasks due to their high degree of interpretability. However, learning a DT from data is a difficult optimization problem, as it is non-convex and non-differentiable. Therefore, common approaches learn DTs using a greedy growth algorithm that minimizes the impurity locally at each internal node. Unfortunately, this greedy procedure can lead to suboptimal trees. In this paper, we present a novel approach for learning hard, axis-aligned DTs with gradient descent. The proposed method uses backpropagation with a straight-through operator on a dense DT representation to jointly optimize all tree parameters. Our approach outperforms existing methods on binary classification benchmarks and achieves competitive results for multi-class tasks.
Leveraging Planning Landmarks for Hybrid Online Goal Recognition
Jan 25, 2023



Goal recognition is an important problem in many application domains (e.g., pervasive computing, intrusion detection, computer games, etc.). In many application scenarios it is important that goal recognition algorithms can recognize goals of an observed agent as fast as possible and with minimal domain knowledge. Hence, in this paper, we propose a hybrid method for online goal recognition that combines a symbolic planning landmark based approach and a data-driven goal recognition approach and evaluate it in a real-world cooking scenario. The empirical results show that the proposed method is not only significantly more efficient in terms of computation time than the state-of-the-art but also improves goal recognition performance. Furthermore, we show that the utilized planning landmark based approach, which was so far only evaluated on artificial benchmark domains, achieves also good recognition performance when applied to a real-world cooking scenario.