 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXQCfD: Accelerating Fast Actor-Critic Algorithms with Prior Data and Prior Policies
May 11, 2026For reinforcement learning in the real world online exploration is expensive A common practice in robotic reinforcement learning is to incorporate additional data to improve sample efficiency Expert demonstration data is often crucial for solving hard exploration tasks with sparse rewards While prior data is used to augment experience and pretrain models we show that the design of existing algorithms fails to achieve the sample efficiency that is possible in this setting due to a failure to use pretrained policies effectively We propose XQCfD which extends the sample-efficient XQC actor-critic to learn from demonstrations using augmented replay buffers pretrained policies and stationary policy architectures designed to avoid rapidly unlearning the strong initial policy like prior works We show our stationary network architecture enables policy improvement out-of-distribution better than standard network architectures due to its higher entropy predictions XQCfD achieves state of the art performance across a range of complex manipulation tasks with sparse rewards from the popular Adroit Robomimic and MimicGen benchmarks -- notably with a low update-to-data ratio and no ensemble networks
FlashSAC: Fast and Stable Off-Policy Reinforcement Learning for High-Dimensional Robot Control
Apr 06, 2026Reinforcement learning (RL) is a core approach for robot control when expert demonstrations are unavailable. On-policy methods such as Proximal Policy Optimization (PPO) are widely used for their stability, but their reliance on narrowly distributed on-policy data limits accurate policy evaluation in high-dimensional state and action spaces. Off-policy methods can overcome this limitation by learning from a broader state-action distribution, yet suffer from slow convergence and instability, as fitting a value function over diverse data requires many gradient updates, causing critic errors to accumulate through bootstrapping. We present FlashSAC, a fast and stable off-policy RL algorithm built on Soft Actor-Critic. Motivated by scaling laws observed in supervised learning, FlashSAC sharply reduces gradient updates while compensating with larger models and higher data throughput. To maintain stability at increased scale, FlashSAC explicitly bounds weight, feature, and gradient norms, curbing critic error accumulation. Across over 60 tasks in 10 simulators, FlashSAC consistently outperforms PPO and strong off-policy baselines in both final performance and training efficiency, with the largest gains on high-dimensional tasks such as dexterous manipulation. In sim-to-real humanoid locomotion, FlashSAC reduces training time from hours to minutes, demonstrating the promise of off-policy RL for sim-to-real transfer.
Scaling CrossQ with Weight Normalization
Jun 04, 2025


Reinforcement learning has achieved significant milestones, but sample efficiency remains a bottleneck for real-world applications. Recently, CrossQ has demonstrated state-of-the-art sample efficiency with a low update-to-data (UTD) ratio of 1. In this work, we explore CrossQ's scaling behavior with higher UTD ratios. We identify challenges in the training dynamics which are emphasized by higher UTDs, particularly Q-bias explosion and the growing magnitude of critic network weights. To address this, we integrate weight normalization into the CrossQ framework, a solution that stabilizes training, prevents potential loss of plasticity and keeps the effective learning rate constant. Our proposed approach reliably scales with increasing UTD ratios, achieving competitive or superior performance across a range of challenging tasks on the DeepMind control benchmark, notably the complex dog and humanoid environments. This work eliminates the need for drastic interventions, such as network resets, and offers a robust pathway for improving sample efficiency and scalability in model-free reinforcement learning.
Scaling Off-Policy Reinforcement Learning with Batch and Weight Normalization
Feb 11, 2025



Reinforcement learning has achieved significant milestones, but sample efficiency remains a bottleneck for real-world applications. Recently, CrossQ has demonstrated state-of-the-art sample efficiency with a low update-to-data (UTD) ratio of 1. In this work, we explore CrossQ's scaling behavior with higher UTD ratios. We identify challenges in the training dynamics, which are emphasized by higher UTD ratios. To address these, we integrate weight normalization into the CrossQ framework, a solution that stabilizes training, has been shown to prevent potential loss of plasticity and keeps the effective learning rate constant. Our proposed approach reliably scales with increasing UTD ratios, achieving competitive performance across 25 challenging continuous control tasks on the DeepMind Control Suite and Myosuite benchmarks, notably the complex dog and humanoid environments. This work eliminates the need for drastic interventions, such as network resets, and offers a simple yet robust pathway for improving sample efficiency and scalability in model-free reinforcement learning.
SYMPOL: Symbolic Tree-Based On-Policy Reinforcement Learning
Aug 16, 2024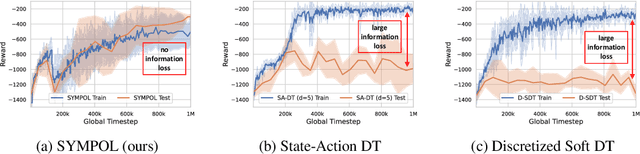



Reinforcement learning (RL) has seen significant success across various domains, but its adoption is often limited by the black-box nature of neural network policies, making them difficult to interpret. In contrast, symbolic policies allow representing decision-making strategies in a compact and interpretable way. However, learning symbolic policies directly within on-policy methods remains challenging. In this paper, we introduce SYMPOL, a novel method for SYMbolic tree-based on-POLicy RL. SYMPOL employs a tree-based model integrated with a policy gradient method, enabling the agent to learn and adapt its actions while maintaining a high level of interpretability. We evaluate SYMPOL on a set of benchmark RL tasks, demonstrating its superiority over alternative tree-based RL approaches in terms of performance and interpretability. To the best of our knowledge, this is the first method, that allows a gradient-based end-to-end learning of interpretable, axis-aligned decision trees on-policy. Therefore, SYMPOL can become the foundation for a new class of interpretable RL based on decision trees. Our implementation is available under: https://github.com/s-marton/SYMPOL