 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductively Informed Inductive Program Synthesis
May 20, 2025Abstraction and reasoning in program synthesis has seen significant progress through both inductive and transductive paradigms. Inductive approaches generate a program or latent function from input-output examples, which can then be applied to new inputs. Transductive approaches directly predict output values for given inputs, effectively serving as the function themselves. Current approaches combine inductive and transductive models via isolated ensembling, but they do not explicitly model the interaction between both paradigms. In this work, we introduce \acs{tiips}, a novel framework that unifies transductive and inductive strategies by explicitly modeling their interactions through a cooperative mechanism: an inductive model generates programs, while a transductive model constrains, guides, and refines the search to improve synthesis accuracy and generalization. We evaluate \acs{tiips} on two widely studied program synthesis domains: string and list manipulation. Our results show that \acs{tiips} solves more tasks and yields functions that more closely match optimal solutions in syntax and semantics, particularly in out-of-distribution settings, yielding state-of-the-art performance. We believe that explicitly modeling the synergy between inductive and transductive reasoning opens promising avenues for general-purpose program synthesis and broader applications.
Which LIME should I trust? Concepts, Challenges, and Solutions
Mar 31, 2025As neural networks become dominant in essential systems, Explainable Artificial Intelligence (XAI) plays a crucial role in fostering trust and detecting potential misbehavior of opaque models. LIME (Local Interpretable Model-agnostic Explanations) is among the most prominent model-agnostic approaches, generating explanations by approximating the behavior of black-box models around specific instances. Despite its popularity, LIME faces challenges related to fidelity, stability, and applicability to domain-specific problems. Numerous adaptations and enhancements have been proposed to address these issues, but the growing number of developments can be overwhelming, complicating efforts to navigate LIME-related research. To the best of our knowledge, this is the first survey to comprehensively explore and collect LIME's foundational concepts and known limitations. We categorize and compare its various enhancements, offering a structured taxonomy based on intermediate steps and key issues. Our analysis provides a holistic overview of advancements in LIME, guiding future research and helping practitioners identify suitable approaches. Additionally, we provide a continuously updated interactive website (https://patrick-knab.github.io/which-lime-to-trust/), offering a concise and accessible overview of the survey.
Unreflected Use of Tabular Data Repositories Can Undermine Research Quality
Mar 12, 2025


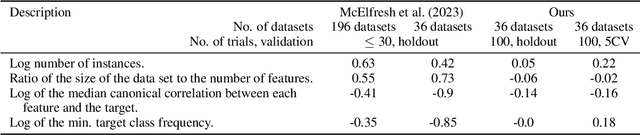
Data repositories have accumulated a large number of tabular datasets from various domains. Machine Learning researchers are actively using these datasets to evaluate novel approaches. Consequently, data repositories have an important standing in tabular data research. They not only host datasets but also provide information on how to use them in supervised learning tasks. In this paper, we argue that, despite great achievements in usability, the unreflected usage of datasets from data repositories may have led to reduced research quality and scientific rigor. We present examples from prominent recent studies that illustrate the problematic use of datasets from OpenML, a large data repository for tabular data. Our illustrations help users of data repositories avoid falling into the traps of (1) using suboptimal model selection strategies, (2) overlooking strong baselines, and (3) inappropriate preprocessing. In response, we discuss possible solutions for how data repositories can prevent the inappropriate use of datasets and become the cornerstones for improved overall quality of empirical research studies.
Shedding Light in Task Decomposition in Program Synthesis: The Driving Force of the Synthesizer Model
Mar 11, 2025Task decomposition is a fundamental mechanism in program synthesis, enabling complex problems to be broken down into manageable subtasks. ExeDec, a state-of-the-art program synthesis framework, employs this approach by combining a Subgoal Model for decomposition and a Synthesizer Model for program generation to facilitate compositional generalization. In this work, we develop REGISM, an adaptation of ExeDec that removes decomposition guidance and relies solely on iterative execution-driven synthesis. By comparing these two exemplary approaches-ExeDec, which leverages task decomposition, and REGISM, which does not-we investigate the interplay between task decomposition and program generation. Our findings indicate that ExeDec exhibits significant advantages in length generalization and concept composition tasks, likely due to its explicit decomposition strategies. At the same time, REGISM frequently matches or surpasses ExeDec's performance across various scenarios, with its solutions often aligning more closely with ground truth decompositions. These observations highlight the importance of repeated execution-guided synthesis in driving task-solving performance, even within frameworks that incorporate explicit decomposition strategies. Our analysis suggests that task decomposition approaches like ExeDec hold significant potential for advancing program synthesis, though further work is needed to clarify when and why these strategies are most effective.
Disentangling Exploration of Large Language Models by Optimal Exploitation
Jan 15, 2025Exploration is a crucial skill for self-improvement and open-ended problem-solving. However, it remains uncertain whether large language models can effectively explore the state-space. Existing evaluations predominantly focus on the trade-off between exploration and exploitation, often assessed in multi-armed bandit problems. In contrast, this work isolates exploration as the sole objective, tasking the agent with delivering information that enhances future returns. For the evaluation, we propose to decompose missing rewards into exploration and exploitation components by measuring the optimal achievable return for the states already explored. Our experiments with various LLMs reveal that most models struggle to sufficiently explore the state-space and that weak exploration is insufficient. We observe a positive correlation between model size and exploration performance, with larger models demonstrating superior capabilities. Furthermore, we show that our decomposition provides insights into differences in behaviors driven by agent instructions during prompt engineering, offering a valuable tool for refining LLM performance in exploratory tasks.
Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages
Jan 10, 2025



Human bilinguals often use similar brain regions to process multiple languages, depending on when they learned their second language and their proficiency. In large language models (LLMs), how are multiple languages learned and encoded? In this work, we explore the extent to which LLMs share representations of morphosyntactic concepts such as grammatical number, gender, and tense across languages. We train sparse autoencoders on Llama-3-8B and Aya-23-8B, and demonstrate that abstract grammatical concepts are often encoded in feature directions shared across many languages. We use causal interventions to verify the multilingual nature of these representations; specifically, we show that ablating only multilingual features decreases classifier performance to near-chance across languages. We then use these features to precisely modify model behavior in a machine translation task; this demonstrates both the generality and selectivity of these feature's roles in the network. Our findings suggest that even models trained predominantly on English data can develop robust, cross-lingual abstractions of morphosyntactic concepts.
Aligning Visual and Semantic Interpretability through Visually Grounded Concept Bottleneck Models
Dec 16, 2024The performance of neural networks increases steadily, but our understanding of their decision-making lags behind. Concept Bottleneck Models (CBMs) address this issue by incorporating human-understandable concepts into the prediction process, thereby enhancing transparency and interpretability. Since existing approaches often rely on large language models (LLMs) to infer concepts, their results may contain inaccurate or incomplete mappings, especially in complex visual domains. We introduce visually Grounded Concept Bottleneck Models (GCBM), which derive concepts on the image level using segmentation and detection foundation models. Our method generates inherently interpretable concepts, which can be grounded in the input image using attribution methods, allowing interpretations to be traced back to the image plane. We show that GCBM concepts are meaningful interpretability vehicles, which aid our understanding of model embedding spaces. GCBMs allow users to control the granularity, number, and naming of concepts, providing flexibility and are easily adaptable to new datasets without pre-training or additional data needed. Prediction accuracy is within 0.3-6% of the linear probe and GCBMs perform especially well for fine-grained classification interpretability on CUB, due to their dataset specificity. Our code is available on https://github.com/KathPra/GCBM.
A*Net and NBFNet Learn Negative Patterns on Knowledge Graphs
Dec 06, 2024In this technical report, we investigate the predictive performance differences of a rule-based approach and the GNN architectures NBFNet and A*Net with respect to knowledge graph completion. For the two most common benchmarks, we find that a substantial fraction of the performance difference can be explained by one unique negative pattern on each dataset that is hidden from the rule-based approach. Our findings add a unique perspective on the performance difference of different model classes for knowledge graph completion: Models can achieve a predictive performance advantage by penalizing scores of incorrect facts opposed to providing high scores for correct facts.
Interpreting Outliers in Time Series Data through Decoding Autoencoder
Sep 03, 2024



Outlier detection is a crucial analytical tool in various fields. In critical systems like manufacturing, malfunctioning outlier detection can be costly and safety-critical. Therefore, there is a significant need for explainable artificial intelligence (XAI) when deploying opaque models in such environments. This study focuses on manufacturing time series data from a German automotive supply industry. We utilize autoencoders to compress the entire time series and then apply anomaly detection techniques to its latent features. For outlier interpretation, we (i) adopt widely used XAI techniques to the autoencoder's encoder. Additionally, (ii) we propose AEE, Aggregated Explanatory Ensemble, a novel approach that fuses explanations of multiple XAI techniques into a single, more expressive interpretation. For evaluation of explanations, (iii) we propose a technique to measure the quality of encoder explanations quantitatively. Furthermore, we qualitatively assess the effectiveness of outlier explanations with domain expertise.
Fact Probability Vector Based Goal Recognition
Aug 26, 2024



We present a new approach to goal recognition that involves comparing observed facts with their expected probabilities. These probabilities depend on a specified goal g and initial state s0. Our method maps these probabilities and observed facts into a real vector space to compute heuristic values for potential goals. These values estimate the likelihood of a given goal being the true objective of the observed agent. As obtaining exact expected probabilities for observed facts in an observation sequence is often practically infeasible, we propose and empirically validate a method for approximating these probabilities. Our empirical results show that the proposed approach offers improved goal recognition precision compared to state-of-the-art techniques while reducing computational complexity.