 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Climate Action: Computer Vision Analysis of Visual Narratives on X
Mar 12, 2025Climate change is one of the most pressing challenges of the 21st century, sparking widespread discourse across social media platforms. Activists, policymakers, and researchers seek to understand public sentiment and narratives while access to social media data has become increasingly restricted in the post-API era. In this study, we analyze a dataset of climate change-related tweets from X (formerly Twitter) shared in 2019, containing 730k tweets along with the shared images. Our approach integrates statistical analysis, image classification, object detection, and sentiment analysis to explore visual narratives in climate discourse. Additionally, we introduce a graphical user interface (GUI) to facilitate interactive data exploration. Our findings reveal key themes in climate communication, highlight sentiment divergence between images and text, and underscore the strengths and limitations of foundation models in analyzing social media imagery. By releasing our code and tools, we aim to support future research on the intersection of climate change, social media, and computer vision.
Aligning Visual and Semantic Interpretability through Visually Grounded Concept Bottleneck Models
Dec 16, 2024The performance of neural networks increases steadily, but our understanding of their decision-making lags behind. Concept Bottleneck Models (CBMs) address this issue by incorporating human-understandable concepts into the prediction process, thereby enhancing transparency and interpretability. Since existing approaches often rely on large language models (LLMs) to infer concepts, their results may contain inaccurate or incomplete mappings, especially in complex visual domains. We introduce visually Grounded Concept Bottleneck Models (GCBM), which derive concepts on the image level using segmentation and detection foundation models. Our method generates inherently interpretable concepts, which can be grounded in the input image using attribution methods, allowing interpretations to be traced back to the image plane. We show that GCBM concepts are meaningful interpretability vehicles, which aid our understanding of model embedding spaces. GCBMs allow users to control the granularity, number, and naming of concepts, providing flexibility and are easily adaptable to new datasets without pre-training or additional data needed. Prediction accuracy is within 0.3-6% of the linear probe and GCBMs perform especially well for fine-grained classification interpretability on CUB, due to their dataset specificity. Our code is available on https://github.com/KathPra/GCBM.
I Spy With My Little Eye: A Minimum Cost Multicut Investigation of Dataset Frames
Dec 02, 2024Visual framing analysis is a key method in social sciences for determining common themes and concepts in a given discourse. To reduce manual effort, image clustering can significantly speed up the annotation process. In this work, we phrase the clustering task as a Minimum Cost Multicut Problem [MP]. Solutions to the MP have been shown to provide clusterings that maximize the posterior probability, solely from provided local, pairwise probabilities of two images belonging to the same cluster. We discuss the efficacy of numerous embedding spaces to detect visual frames and show its superiority over other clustering methods. To this end, we employ the climate change dataset \textit{ClimateTV} which contains images commonly used for visual frame analysis. For broad visual frames, DINOv2 is a suitable embedding space, while ConvNeXt V2 returns a larger number of clusters which contain fine-grain differences, i.e. speech and protest. Our insights into embedding space differences in combination with the optimal clustering - by definition - advances automated visual frame detection. Our code can be found at https://github.com/KathPra/MP4VisualFrameDetection.
Local Spherical Harmonics Improve Skeleton-Based Hand Action Recognition
Aug 21, 2023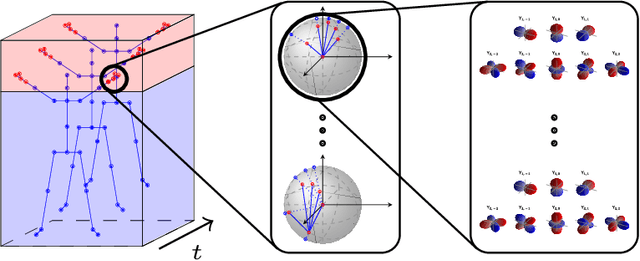
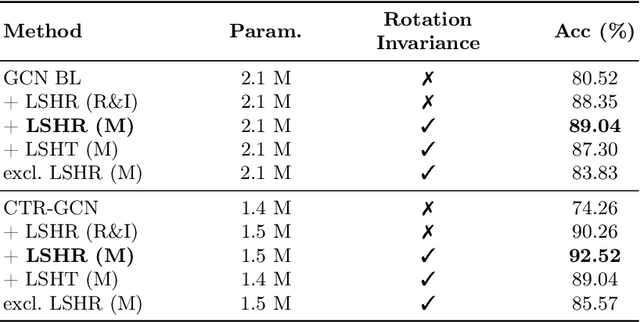

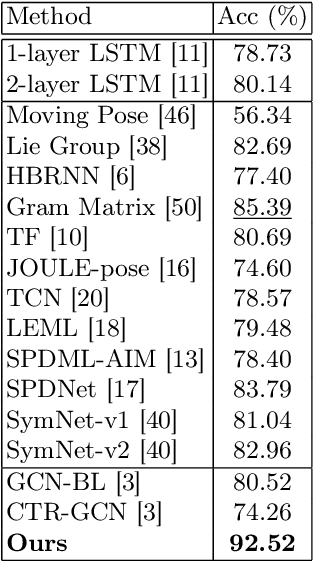
Hand action recognition is essential. Communication, human-robot interactions, and gesture control are dependent on it. Skeleton-based action recognition traditionally includes hands, which belong to the classes which remain challenging to correctly recognize to date. We propose a method specifically designed for hand action recognition which uses relative angular embeddings and local Spherical Harmonics to create novel hand representations. The use of Spherical Harmonics creates rotation-invariant representations which make hand action recognition even more robust against inter-subject differences and viewpoint changes. We conduct extensive experiments on the hand joints in the First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations, and on the NTU RGB+D 120 dataset, demonstrating the benefit of using Local Spherical Harmonics Representations. Our code is available at https://github.com/KathPra/LSHR_LSHT.