 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIX- Trading Adversarial Fairness via Mixed Adversarial Training
Jul 10, 2025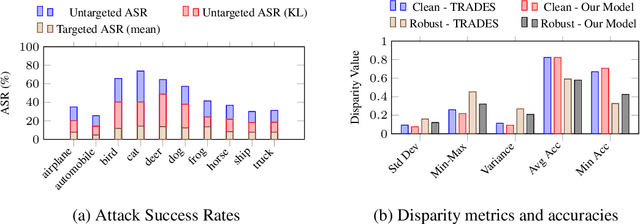
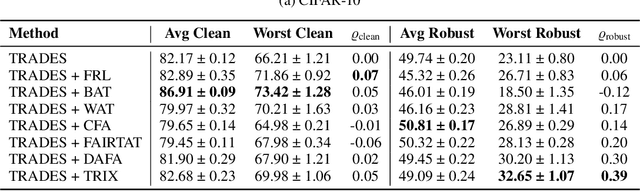
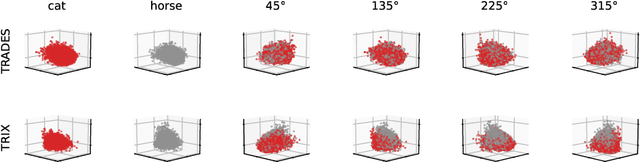
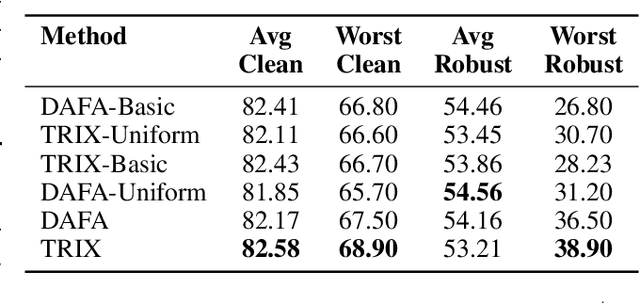
Adversarial Training (AT) is a widely adopted defense against adversarial examples. However, existing approaches typically apply a uniform training objective across all classes, overlooking disparities in class-wise vulnerability. This results in adversarial unfairness: classes with well distinguishable features (strong classes) tend to become more robust, while classes with overlapping or shared features(weak classes) remain disproportionately susceptible to adversarial attacks. We observe that strong classes do not require strong adversaries during training, as their non-robust features are quickly suppressed. In contrast, weak classes benefit from stronger adversaries to effectively reduce their vulnerabilities. Motivated by this, we introduce TRIX, a feature-aware adversarial training framework that adaptively assigns weaker targeted adversaries to strong classes, promoting feature diversity via uniformly sampled targets, and stronger untargeted adversaries to weak classes, enhancing their focused robustness. TRIX further incorporates per-class loss weighting and perturbation strength adjustments, building on prior work, to emphasize weak classes during the optimization. Comprehensive experiments on standard image classification benchmarks, including evaluations under strong attacks such as PGD and AutoAttack, demonstrate that TRIX significantly improves worst-case class accuracy on both clean and adversarial data, reducing inter-class robustness disparities, and preserves overall accuracy. Our results highlight TRIX as a practical step toward fair and effective adversarial defense.
Corner Cases: How Size and Position of Objects Challenge ImageNet-Trained Models
May 06, 2025Backgrounds in images play a major role in contributing to spurious correlations among different data points. Owing to aesthetic preferences of humans capturing the images, datasets can exhibit positional (location of the object within a given frame) and size (region-of-interest to image ratio) biases for different classes. In this paper, we show that these biases can impact how much a model relies on spurious features in the background to make its predictions. To better illustrate our findings, we propose a synthetic dataset derived from ImageNet1k, Hard-Spurious-ImageNet, which contains images with various backgrounds, object positions, and object sizes. By evaluating the dataset on different pretrained models, we find that most models rely heavily on spurious features in the background when the region-of-interest (ROI) to image ratio is small and the object is far from the center of the image. Moreover, we also show that current methods that aim to mitigate harmful spurious features, do not take into account these factors, hence fail to achieve considerable performance gains for worst-group accuracies when the size and location of core features in an image change.
Deep Learning for Climate Action: Computer Vision Analysis of Visual Narratives on X
Mar 12, 2025Climate change is one of the most pressing challenges of the 21st century, sparking widespread discourse across social media platforms. Activists, policymakers, and researchers seek to understand public sentiment and narratives while access to social media data has become increasingly restricted in the post-API era. In this study, we analyze a dataset of climate change-related tweets from X (formerly Twitter) shared in 2019, containing 730k tweets along with the shared images. Our approach integrates statistical analysis, image classification, object detection, and sentiment analysis to explore visual narratives in climate discourse. Additionally, we introduce a graphical user interface (GUI) to facilitate interactive data exploration. Our findings reveal key themes in climate communication, highlight sentiment divergence between images and text, and underscore the strengths and limitations of foundation models in analyzing social media imagery. By releasing our code and tools, we aim to support future research on the intersection of climate change, social media, and computer vision.
FAIR-TAT: Improving Model Fairness Using Targeted Adversarial Training
Oct 30, 2024



Deep neural networks are susceptible to adversarial attacks and common corruptions, which undermine their robustness. In order to enhance model resilience against such challenges, Adversarial Training (AT) has emerged as a prominent solution. Nevertheless, adversarial robustness is often attained at the expense of model fairness during AT, i.e., disparity in class-wise robustness of the model. While distinctive classes become more robust towards such adversaries, hard to detect classes suffer. Recently, research has focused on improving model fairness specifically for perturbed images, overlooking the accuracy of the most likely non-perturbed data. Additionally, despite their robustness against the adversaries encountered during model training, state-of-the-art adversarial trained models have difficulty maintaining robustness and fairness when confronted with diverse adversarial threats or common corruptions. In this work, we address the above concerns by introducing a novel approach called Fair Targeted Adversarial Training (FAIR-TAT). We show that using targeted adversarial attacks for adversarial training (instead of untargeted attacks) can allow for more favorable trade-offs with respect to adversarial fairness. Empirical results validate the efficacy of our approach.
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024



Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
Local Spherical Harmonics Improve Skeleton-Based Hand Action Recognition
Aug 21, 2023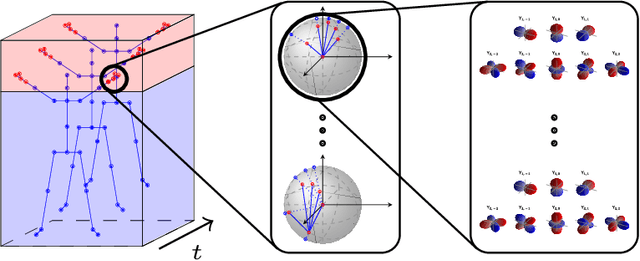
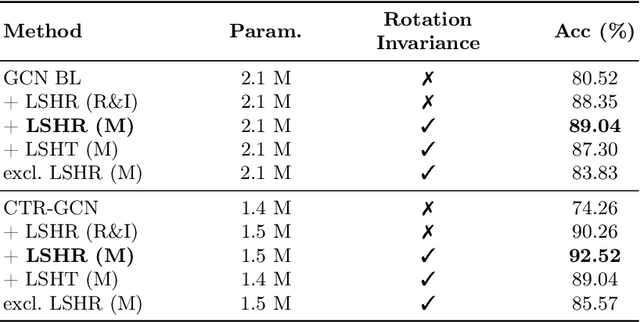

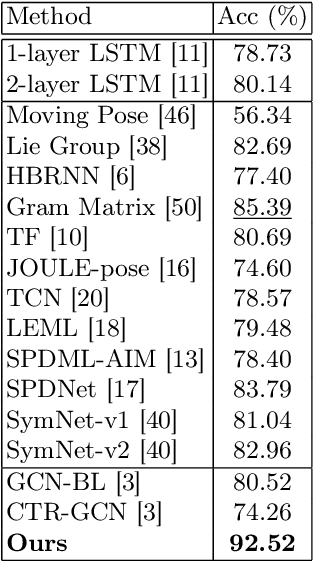
Hand action recognition is essential. Communication, human-robot interactions, and gesture control are dependent on it. Skeleton-based action recognition traditionally includes hands, which belong to the classes which remain challenging to correctly recognize to date. We propose a method specifically designed for hand action recognition which uses relative angular embeddings and local Spherical Harmonics to create novel hand representations. The use of Spherical Harmonics creates rotation-invariant representations which make hand action recognition even more robust against inter-subject differences and viewpoint changes. We conduct extensive experiments on the hand joints in the First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations, and on the NTU RGB+D 120 dataset, demonstrating the benefit of using Local Spherical Harmonics Representations. Our code is available at https://github.com/KathPra/LSHR_LSHT.
Neural Architecture Design and Robustness: A Dataset
Jun 11, 2023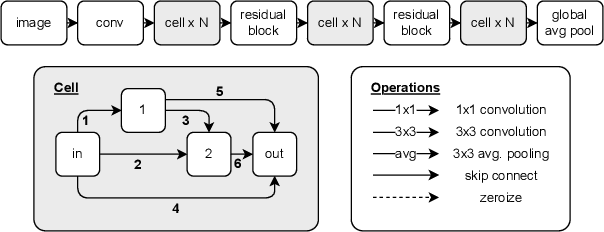
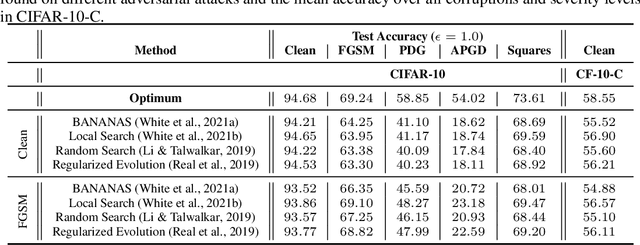
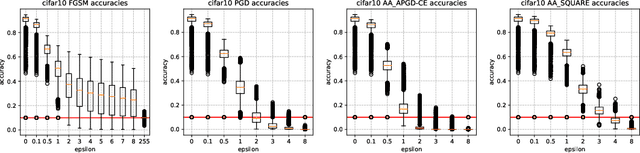

Deep learning models have proven to be successful in a wide range of machine learning tasks. Yet, they are often highly sensitive to perturbations on the input data which can lead to incorrect decisions with high confidence, hampering their deployment for practical use-cases. Thus, finding architectures that are (more) robust against perturbations has received much attention in recent years. Just like the search for well-performing architectures in terms of clean accuracy, this usually involves a tedious trial-and-error process with one additional challenge: the evaluation of a network's robustness is significantly more expensive than its evaluation for clean accuracy. Thus, the aim of this paper is to facilitate better streamlined research on architectural design choices with respect to their impact on robustness as well as, for example, the evaluation of surrogate measures for robustness. We therefore borrow one of the most commonly considered search spaces for neural architecture search for image classification, NAS-Bench-201, which contains a manageable size of 6466 non-isomorphic network designs. We evaluate all these networks on a range of common adversarial attacks and corruption types and introduce a database on neural architecture design and robustness evaluations. We further present three exemplary use cases of this dataset, in which we (i) benchmark robustness measurements based on Jacobian and Hessian matrices for their robustness predictability, (ii) perform neural architecture search on robust accuracies, and (iii) provide an initial analysis of how architectural design choices affect robustness. We find that carefully crafting the topology of a network can have substantial impact on its robustness, where networks with the same parameter count range in mean adversarial robust accuracy from 20%-41%. Code and data is available at http://robustness.vision/.
Happy People -- Image Synthesis as Black-Box Optimization Problem in the Discrete Latent Space of Deep Generative Models
Jun 11, 2023In recent years, optimization in the learned latent space of deep generative models has been successfully applied to black-box optimization problems such as drug design, image generation or neural architecture search. Existing models thereby leverage the ability of neural models to learn the data distribution from a limited amount of samples such that new samples from the distribution can be drawn. In this work, we propose a novel image generative approach that optimizes the generated sample with respect to a continuously quantifiable property. While we anticipate absolutely no practically meaningful application for the proposed framework, it is theoretically principled and allows to quickly propose samples at the mere boundary of the training data distribution. Specifically, we propose to use tree-based ensemble models as mathematical programs over the discrete latent space of vector quantized VAEs, which can be globally solved. Subsequent weighted retraining on these queries allows to induce a distribution shift. In lack of a practically relevant problem, we consider a visually appealing application: the generation of happily smiling faces (where the training distribution only contains less happy people) - and show the principled behavior of our approach in terms of improved FID and higher smile degree over baseline approaches.
Learning to solve Minimum Cost Multicuts efficiently using Edge-Weighted Graph Convolutional Neural Networks
Apr 04, 2022



The minimum cost multicut problem is the NP-hard/APX-hard combinatorial optimization problem of partitioning a real-valued edge-weighted graph such as to minimize the total cost of the partition. While graph convolutional neural networks (GNN) have proven to be promising in the context of combinatorial optimization, most of them are only tailored to or tested on positive-valued edge weights, i.e. they do not comply to the nature of the multicut problem. We therefore adapt various GNN architectures including Graph Convolutional Networks, Signed Graph Convolutional Networks and Graph Isomorphic Networks to facilitate the efficient encoding of real-valued edge costs. Moreover, we employ a reformulation of the multicut ILP constraints to a polynomial program as loss function that allows to learn feasible multicut solutions in a scalable way. Thus, we provide the first approach towards end-to-end trainable multicuts. Our findings support that GNN approaches can produce good solutions in practice while providing lower computation times and largely improved scalability compared to LP solvers and optimized heuristics, especially when considering large instances.
FrequencyLowCut Pooling -- Plug & Play against Catastrophic Overfitting
Apr 01, 2022

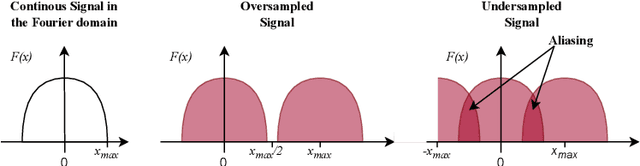
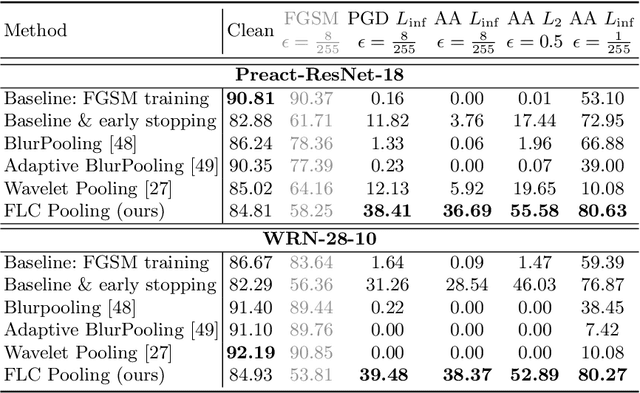
Over the last years, Convolutional Neural Networks (CNNs) have been the dominating neural architecture in a wide range of computer vision tasks. From an image and signal processing point of view, this success might be a bit surprising as the inherent spatial pyramid design of most CNNs is apparently violating basic signal processing laws, i.e. Sampling Theorem in their down-sampling operations. However, since poor sampling appeared not to affect model accuracy, this issue has been broadly neglected until model robustness started to receive more attention. Recent work [17] in the context of adversarial attacks and distribution shifts, showed after all, that there is a strong correlation between the vulnerability of CNNs and aliasing artifacts induced by poor down-sampling operations. This paper builds on these findings and introduces an aliasing free down-sampling operation which can easily be plugged into any CNN architecture: FrequencyLowCut pooling. Our experiments show, that in combination with simple and fast FGSM adversarial training, our hyper-parameter free operator significantly improves model robustness and avoids catastrophic overfitting.