 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Mixed-Noise Learning with Flow-Matching
Aug 25, 2025

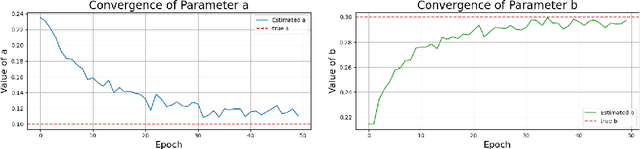
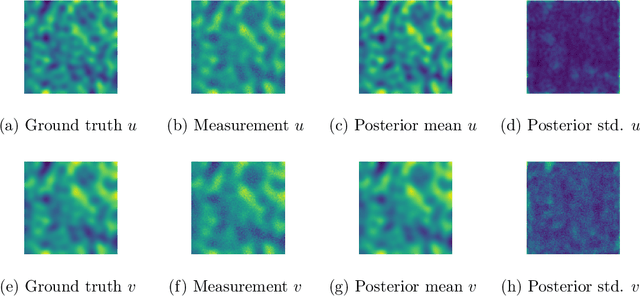
We study Bayesian inverse problems with mixed noise, modeled as a combination of additive and multiplicative Gaussian components. While traditional inference methods often assume fixed or known noise characteristics, real-world applications, particularly in physics and chemistry, frequently involve noise with unknown and heterogeneous structure. Motivated by recent advances in flow-based generative modeling, we propose a novel inference framework based on conditional flow matching embedded within an Expectation-Maximization (EM) algorithm to jointly estimate posterior samplers and noise parameters. To enable high-dimensional inference and improve scalability, we use simulation-free ODE-based flow matching as the generative model in the E-step of the EM algorithm. We prove that, under suitable assumptions, the EM updates converge to the true noise parameters in the population limit of infinite observations. Our numerical results illustrate the effectiveness of combining EM inference with flow matching for mixed-noise Bayesian inverse problems.
Gradient-Free Sequential Bayesian Experimental Design via Interacting Particle Systems
Apr 17, 2025We introduce a gradient-free framework for Bayesian Optimal Experimental Design (BOED) in sequential settings, aimed at complex systems where gradient information is unavailable. Our method combines Ensemble Kalman Inversion (EKI) for design optimization with the Affine-Invariant Langevin Dynamics (ALDI) sampler for efficient posterior sampling-both of which are derivative-free and ensemble-based. To address the computational challenges posed by nested expectations in BOED, we propose variational Gaussian and parametrized Laplace approximations that provide tractable upper and lower bounds on the Expected Information Gain (EIG). These approximations enable scalable utility estimation in high-dimensional spaces and PDE-constrained inverse problems. We demonstrate the performance of our framework through numerical experiments ranging from linear Gaussian models to PDE-based inference tasks, highlighting the method's robustness, accuracy, and efficiency in information-driven experimental design.
Generative Modelling with Tensor Train approximations of Hamilton--Jacobi--Bellman equations
Feb 23, 2024Sampling from probability densities is a common challenge in fields such as Uncertainty Quantification (UQ) and Generative Modelling (GM). In GM in particular, the use of reverse-time diffusion processes depending on the log-densities of Ornstein-Uhlenbeck forward processes are a popular sampling tool. In Berner et al. [2022] the authors point out that these log-densities can be obtained by solution of a \textit{Hamilton-Jacobi-Bellman} (HJB) equation known from stochastic optimal control. While this HJB equation is usually treated with indirect methods such as policy iteration and unsupervised training of black-box architectures like Neural Networks, we propose instead to solve the HJB equation by direct time integration, using compressed polynomials represented in the Tensor Train (TT) format for spatial discretization. Crucially, this method is sample-free, agnostic to normalization constants and can avoid the curse of dimensionality due to the TT compression. We provide a complete derivation of the HJB equation's action on Tensor Train polynomials and demonstrate the performance of the proposed time-step-, rank- and degree-adaptive integration method on a nonlinear sampling task in 20 dimensions.
Happy People -- Image Synthesis as Black-Box Optimization Problem in the Discrete Latent Space of Deep Generative Models
Jun 11, 2023In recent years, optimization in the learned latent space of deep generative models has been successfully applied to black-box optimization problems such as drug design, image generation or neural architecture search. Existing models thereby leverage the ability of neural models to learn the data distribution from a limited amount of samples such that new samples from the distribution can be drawn. In this work, we propose a novel image generative approach that optimizes the generated sample with respect to a continuously quantifiable property. While we anticipate absolutely no practically meaningful application for the proposed framework, it is theoretically principled and allows to quickly propose samples at the mere boundary of the training data distribution. Specifically, we propose to use tree-based ensemble models as mathematical programs over the discrete latent space of vector quantized VAEs, which can be globally solved. Subsequent weighted retraining on these queries allows to induce a distribution shift. In lack of a practically relevant problem, we consider a visually appealing application: the generation of happily smiling faces (where the training distribution only contains less happy people) - and show the principled behavior of our approach in terms of improved FID and higher smile degree over baseline approaches.
Ensemble-based gradient inference for particle methods in optimization and sampling
Sep 23, 2022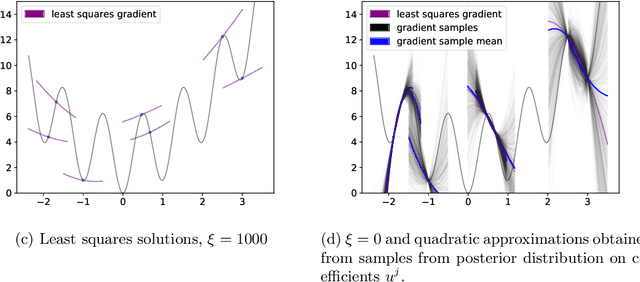
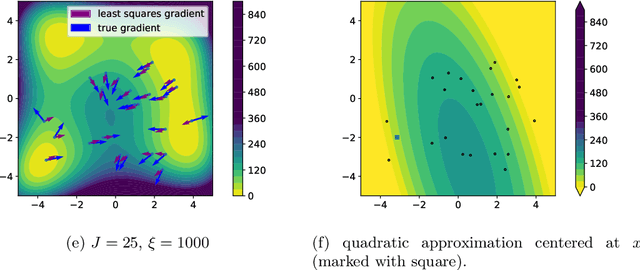

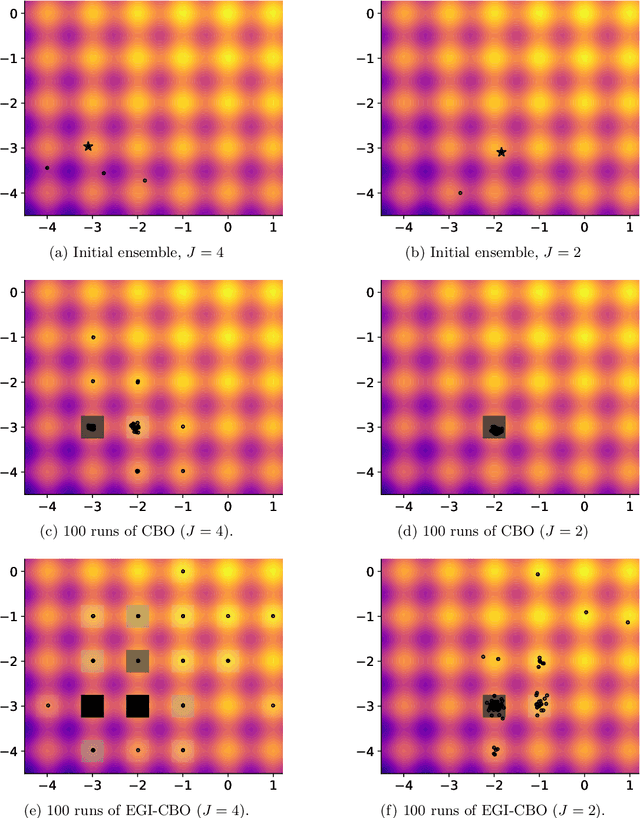
We propose an approach based on function evaluations and Bayesian inference to extract higher-order differential information of objective functions {from a given ensemble of particles}. Pointwise evaluation $\{V(x^i)\}_i$ of some potential $V$ in an ensemble $\{x^i\}_i$ contains implicit information about first or higher order derivatives, which can be made explicit with little computational effort (ensemble-based gradient inference -- EGI). We suggest to use this information for the improvement of established ensemble-based numerical methods for optimization and sampling such as Consensus-based optimization and Langevin-based samplers. Numerical studies indicate that the augmented algorithms are often superior to their gradient-free variants, in particular the augmented methods help the ensembles to escape their initial domain, to explore multimodal, non-Gaussian settings and to speed up the collapse at the end of optimization dynamics.} The code for the numerical examples in this manuscript can be found in the paper's Github repository (https://github.com/MercuryBench/ensemble-based-gradient.git).
Consistency analysis of bilevel data-driven learning in inverse problems
Jul 06, 2020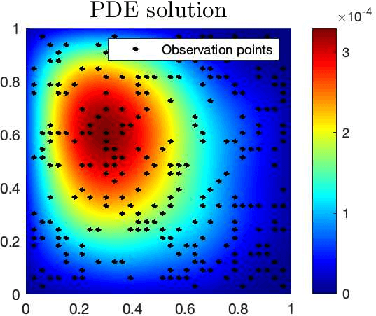

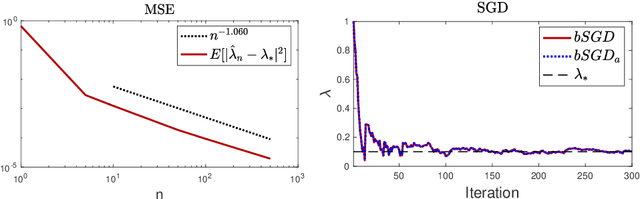
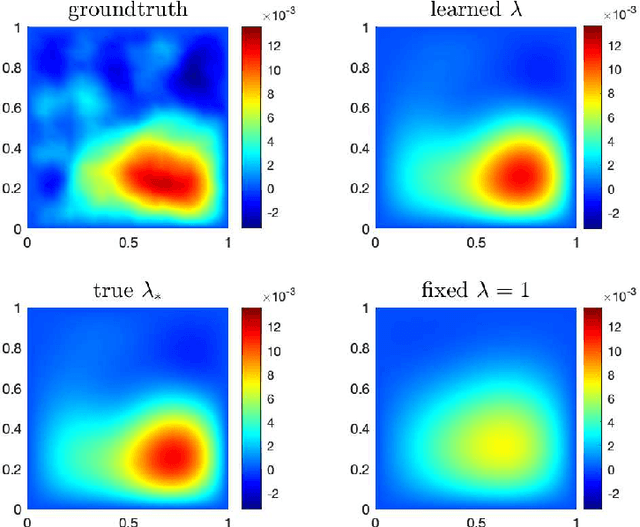
One fundamental problem when solving inverse problems is how to find regularization parameters. This article considers solving this problem using data-driven bilevel optimization, i.e. we consider the adaptive learning of the regularization parameter from data by means of optimization. This approach can be interpreted as solving an empirical risk minimization problem, and we analyze its performance in the large data sample size limit for general nonlinear problems. To reduce the associated computational cost, online numerical schemes are derived using the stochastic gradient method. We prove convergence of these numerical schemes under suitable assumptions on the forward problem. Numerical experiments are presented illustrating the theoretical results and demonstrating the applicability and efficiency of the proposed approaches for various linear and nonlinear inverse problems, including Darcy flow, the eikonal equation, and an image denoising example.