 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Instructify: Demystifying Metadata to Visual Instruction Tuning Data Conversion
May 23, 2025Visual Instruction Tuning (VisIT) data, commonly available as human-assistant conversations with images interleaved in the human turns, are currently the most widespread vehicle for aligning strong LLMs to understand visual inputs, converting them to strong LMMs. While many VisIT datasets are available, most are constructed using ad-hoc techniques developed independently by different groups. They are often poorly documented, lack reproducible code, and rely on paid, closed-source model APIs such as GPT-4, Gemini, or Claude to convert image metadata (labels) into VisIT instructions. This leads to high costs and makes it challenging to scale, enhance quality, or generate VisIT data for new datasets. In this work, we address these challenges and propose an open and unified recipe and approach,~\textbf{\method}, for converting available metadata to VisIT instructions using open LLMs. Our multi-stage \method features an efficient framework for metadata grouping, quality control, data and prompt organization, and conversation sampling. We show that our approach can reproduce or enhance the data quality of available VisIT datasets when applied to the same image data and metadata sources, improving GPT-4 generated VisIT instructions by ~3\% on average and up to 12\% on individual benchmarks using open models, such as Gemma 2 27B and LLaMa 3.1 70B. Additionally, our approach enables effective performance scaling - both in quantity and quality - by enhancing the resulting LMM performance across a wide range of benchmarks. We also analyze the impact of various factors, including conversation format, base model selection, and resampling strategies. Our code, which supports the reproduction of equal or higher-quality VisIT datasets and facilities future metadata-to-VisIT data conversion for niche domains, is released at https://github.com/jacob-hansen/Instructify.
Can Diffusion Models Disentangle? A Theoretical Perspective
Mar 31, 2025This paper presents a novel theoretical framework for understanding how diffusion models can learn disentangled representations. Within this framework, we establish identifiability conditions for general disentangled latent variable models, analyze training dynamics, and derive sample complexity bounds for disentangled latent subspace models. To validate our theory, we conduct disentanglement experiments across diverse tasks and modalities, including subspace recovery in latent subspace Gaussian mixture models, image colorization, image denoising, and voice conversion for speech classification. Additionally, our experiments show that training strategies inspired by our theory, such as style guidance regularization, consistently enhance disentanglement performance.
Mining Your Own Secrets: Diffusion Classifier Scores for Continual Personalization of Text-to-Image Diffusion Models
Oct 02, 2024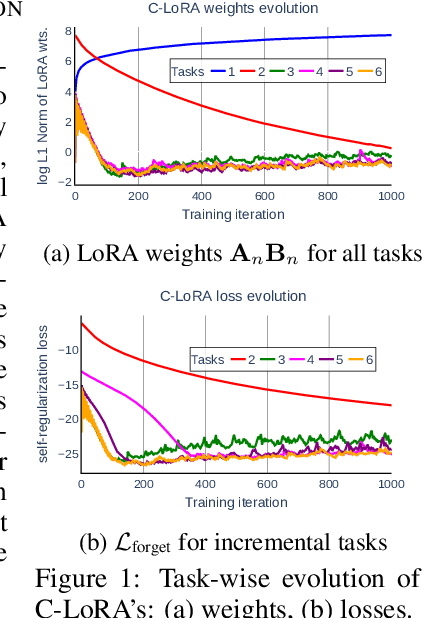
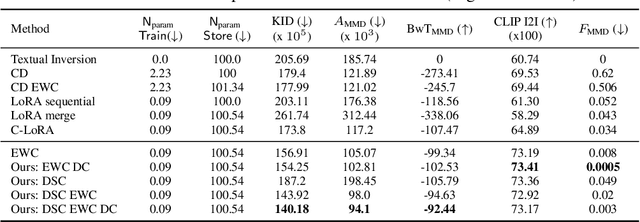
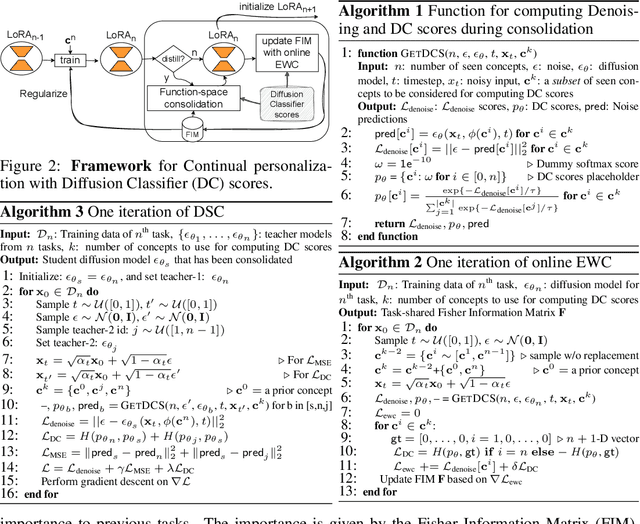
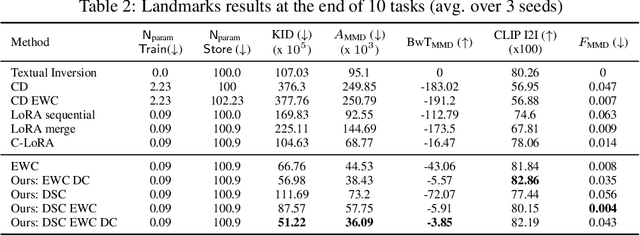
Personalized text-to-image diffusion models have grown popular for their ability to efficiently acquire a new concept from user-defined text descriptions and a few images. However, in the real world, a user may wish to personalize a model on multiple concepts but one at a time, with no access to the data from previous concepts due to storage/privacy concerns. When faced with this continual learning (CL) setup, most personalization methods fail to find a balance between acquiring new concepts and retaining previous ones -- a challenge that continual personalization (CP) aims to solve. Inspired by the successful CL methods that rely on class-specific information for regularization, we resort to the inherent class-conditioned density estimates, also known as diffusion classifier (DC) scores, for continual personalization of text-to-image diffusion models. Namely, we propose using DC scores for regularizing the parameter-space and function-space of text-to-image diffusion models, to achieve continual personalization. Using several diverse evaluation setups, datasets, and metrics, we show that our proposed regularization-based CP methods outperform the state-of-the-art C-LoRA, and other baselines. Finally, by operating in the replay-free CL setup and on low-rank adapters, our method incurs zero storage and parameter overhead, respectively, over the state-of-the-art.
Comparison Visual Instruction Tuning
Jun 13, 2024



Comparing two images in terms of Commonalities and Differences (CaD) is a fundamental human capability that forms the basis of advanced visual reasoning and interpretation. It is essential for the generation of detailed and contextually relevant descriptions, performing comparative analysis, novelty detection, and making informed decisions based on visual data. However, surprisingly, little attention has been given to these fundamental concepts in the best current mimic of human visual intelligence - Large Multimodal Models (LMMs). We develop and contribute a new two-phase approach CaD-VI for collecting synthetic visual instructions, together with an instruction-following dataset CaD-Inst containing 349K image pairs with CaD instructions collected using CaD-VI. Our approach significantly improves the CaD spotting capabilities in LMMs, advancing the SOTA on a diverse set of related tasks by up to 17.5%. It is also complementary to existing difference-only instruction datasets, allowing automatic targeted refinement of those resources increasing their effectiveness for CaD tuning by up to 10%. Additionally, we propose an evaluation benchmark with 7.5K open-ended QAs to assess the CaD understanding abilities of LMMs.
TTT-KD: Test-Time Training for 3D Semantic Segmentation through Knowledge Distillation from Foundation Models
Mar 18, 2024Test-Time Training (TTT) proposes to adapt a pre-trained network to changing data distributions on-the-fly. In this work, we propose the first TTT method for 3D semantic segmentation, TTT-KD, which models Knowledge Distillation (KD) from foundation models (e.g. DINOv2) as a self-supervised objective for adaptation to distribution shifts at test-time. Given access to paired image-pointcloud (2D-3D) data, we first optimize a 3D segmentation backbone for the main task of semantic segmentation using the pointclouds and the task of 2D $\to$ 3D KD by using an off-the-shelf 2D pre-trained foundation model. At test-time, our TTT-KD updates the 3D segmentation backbone for each test sample, by using the self-supervised task of knowledge distillation, before performing the final prediction. Extensive evaluations on multiple indoor and outdoor 3D segmentation benchmarks show the utility of TTT-KD, as it improves performance for both in-distribution (ID) and out-of-distribution (ODO) test datasets. We achieve a gain of up to 13% mIoU (7% on average) when the train and test distributions are similar and up to 45% (20% on average) when adapting to OOD test samples.
Are Vision Language Models Texture or Shape Biased and Can We Steer Them?
Mar 14, 2024



Vision language models (VLMs) have drastically changed the computer vision model landscape in only a few years, opening an exciting array of new applications from zero-shot image classification, over to image captioning, and visual question answering. Unlike pure vision models, they offer an intuitive way to access visual content through language prompting. The wide applicability of such models encourages us to ask whether they also align with human vision - specifically, how far they adopt human-induced visual biases through multimodal fusion, or whether they simply inherit biases from pure vision models. One important visual bias is the texture vs. shape bias, or the dominance of local over global information. In this paper, we study this bias in a wide range of popular VLMs. Interestingly, we find that VLMs are often more shape-biased than their vision encoders, indicating that visual biases are modulated to some extent through text in multimodal models. If text does indeed influence visual biases, this suggests that we may be able to steer visual biases not just through visual input but also through language: a hypothesis that we confirm through extensive experiments. For instance, we are able to steer shape bias from as low as 49% to as high as 72% through prompting alone. For now, the strong human bias towards shape (96%) remains out of reach for all tested VLMs.
Video Test-Time Adaptation for Action Recognition
Dec 02, 2022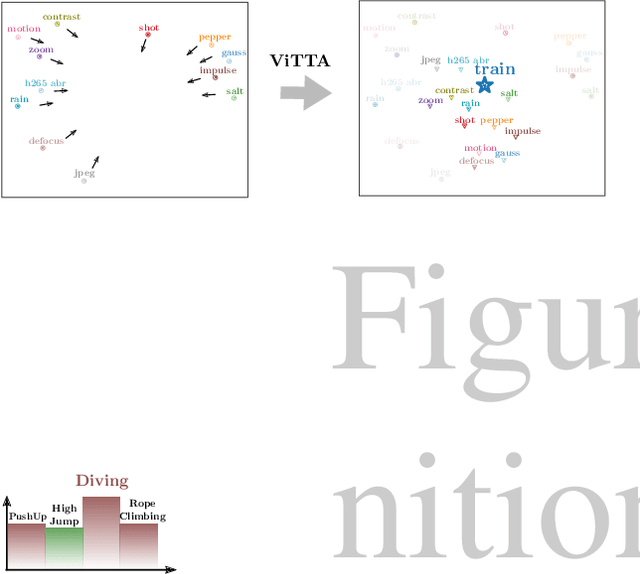
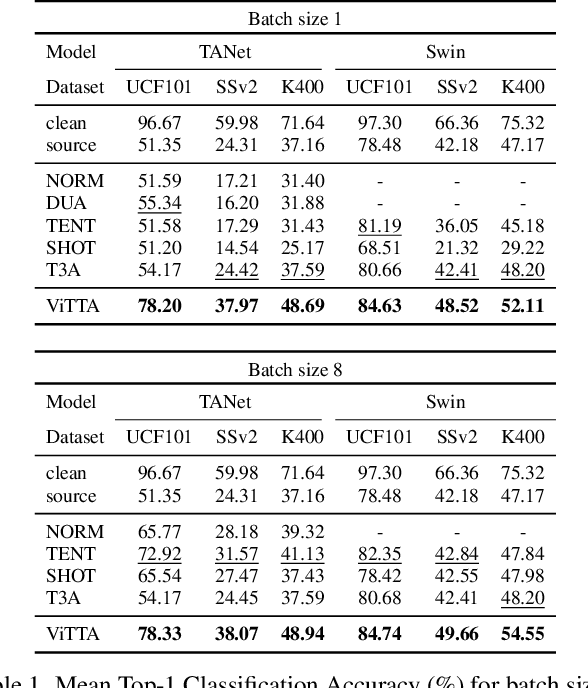
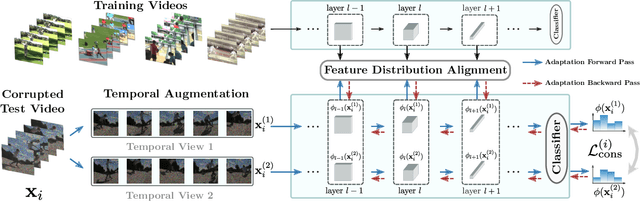
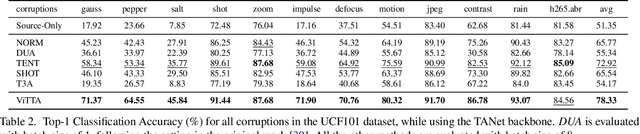
Although action recognition systems can achieve top performance when evaluated on in-distribution test points, they are vulnerable to unanticipated distribution shifts in test data. However, test-time adaptation of video action recognition models against common distribution shifts has so far not been demonstrated. We propose to address this problem with an approach tailored to spatio-temporal models that is capable of adaptation on a single video sample at a step. It consists in a feature distribution alignment technique that aligns online estimates of test set statistics towards the training statistics. We further enforce prediction consistency over temporally augmented views of the same test video sample. Evaluations on three benchmark action recognition datasets show that our proposed technique is architecture-agnostic and able to significantly boost the performance on both, the state of the art convolutional architecture TANet and the Video Swin Transformer. Our proposed method demonstrates a substantial performance gain over existing test-time adaptation approaches in both evaluations of a single distribution shift and the challenging case of random distribution shifts. Code will be available at \url{https://github.com/wlin-at/ViTTA}.
ActMAD: Activation Matching to Align Distributions for Test-Time-Training
Nov 23, 2022



Test-Time-Training (TTT) is an approach to cope with out-of-distribution (OOD) data by adapting a trained model to distribution shifts occurring at test-time. We propose to perform this adaptation via Activation Matching (ActMAD): We analyze activations of the model and align activation statistics of the OOD test data to those of the training data. In contrast to existing methods, which model the distribution of entire channels in the ultimate layer of the feature extractor, we model the distribution of each feature in multiple layers across the network. This results in a more fine-grained supervision and makes ActMAD attain state of the art performance on CIFAR-100C and Imagenet-C. ActMAD is also architecture- and task-agnostic, which lets us go beyond image classification, and score 15.4% improvement over previous approaches when evaluating a KITTI-trained object detector on KITTI-Fog. Our experiments highlight that ActMAD can be applied to online adaptation in realistic scenarios, requiring little data to attain its full performance.
Test-time adversarial detection and robustness for localizing humans using ultra wide band channel impulse responses
Nov 10, 2022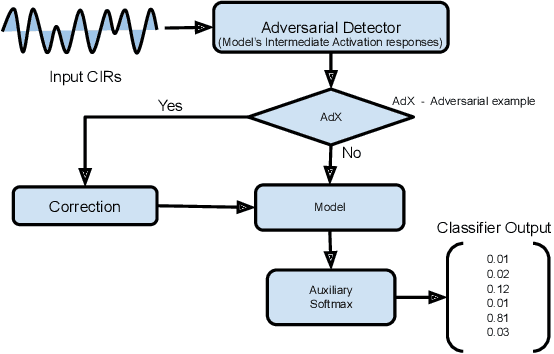
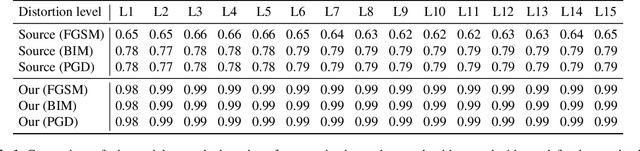
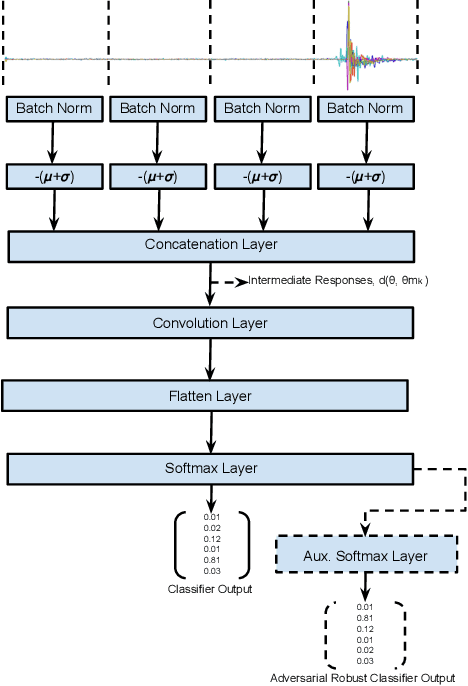
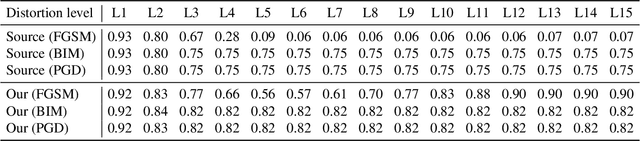
Keyless entry systems in cars are adopting neural networks for localizing its operators. Using test-time adversarial defences equip such systems with the ability to defend against adversarial attacks without prior training on adversarial samples. We propose a test-time adversarial example detector which detects the input adversarial example through quantifying the localized intermediate responses of a pre-trained neural network and confidence scores of an auxiliary softmax layer. Furthermore, in order to make the network robust, we extenuate the non-relevant features by non-iterative input sample clipping. Using our approach, mean performance over 15 levels of adversarial perturbations is increased by 55.33% for the fast gradient sign method (FGSM) and 6.3% for both the basic iterative method (BIM) and the projected gradient method (PGD).