 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Based Error Detection System for Advanced Vehicle Instrument Cluster Rendering
Sep 04, 2024The automotive industry is currently expanding digital display options with every new model that comes onto the market. This entails not just an expansion in dimensions, resolution, and customization choices, but also the capability to employ novel display effects like overlays while assembling the content of the display cluster. Unfortunately, this raises the need for appropriate monitoring systems that can detect rendering errors and apply appropriate countermeasures when required. Classical solutions such as Cyclic Redundancy Checks (CRC) will soon be no longer viable as any sort of alpha blending, warping of scaling of content can cause unwanted CRC violations. Therefore, we propose a novel monitoring approach to verify correctness of displayed content using telltales (e.g. warning signs) as example. It uses a learning-based approach to separate "good" telltales, i.e. those that a human driver will understand correctly, and "corrupted" telltales, i.e. those that will not be visible or perceived correctly. As a result, it possesses inherent resilience against individual pixel errors and implicitly supports changing backgrounds, overlay or scaling effects. This is underlined by our experimental study where all "corrupted" test patterns were correctly classified, while no false alarms were triggered.
Situation Monitor: Diversity-Driven Zero-Shot Out-of-Distribution Detection using Budding Ensemble Architecture for Object Detection
Jun 05, 2024We introduce Situation Monitor, a novel zero-shot Out-of-Distribution (OOD) detection approach for transformer-based object detection models to enhance reliability in safety-critical machine learning applications such as autonomous driving. The Situation Monitor utilizes the Diversity-based Budding Ensemble Architecture (DBEA) and increases the OOD performance by integrating a diversity loss into the training process on top of the budding ensemble architecture, detecting Far-OOD samples and minimizing false positives on Near-OOD samples. Moreover, utilizing the resulting DBEA increases the model's OOD performance and improves the calibration of confidence scores, particularly concerning the intersection over union of the detected objects. The DBEA model achieves these advancements with a 14% reduction in trainable parameters compared to the vanilla model. This signifies a substantial improvement in efficiency without compromising the model's ability to detect OOD instances and calibrate the confidence scores accurately.
Global Clipper: Enhancing Safety and Reliability of Transformer-based Object Detection Models
Jun 05, 2024As transformer-based object detection models progress, their impact in critical sectors like autonomous vehicles and aviation is expected to grow. Soft errors causing bit flips during inference have significantly impacted DNN performance, altering predictions. Traditional range restriction solutions for CNNs fall short for transformers. This study introduces the Global Clipper and Global Hybrid Clipper, effective mitigation strategies specifically designed for transformer-based models. It significantly enhances their resilience to soft errors and reduces faulty inferences to ~ 0\%. We also detail extensive testing across over 64 scenarios involving two transformer models (DINO-DETR and Lite-DETR) and two CNN models (YOLOv3 and SSD) using three datasets, totalling approximately 3.3 million inferences, to assess model robustness comprehensively. Moreover, the paper explores unique aspects of attention blocks in transformers and their operational differences from CNNs.
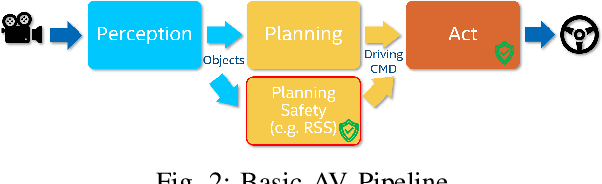
Safe Perception -- A Hierarchical Monitor Approach
Aug 01, 2022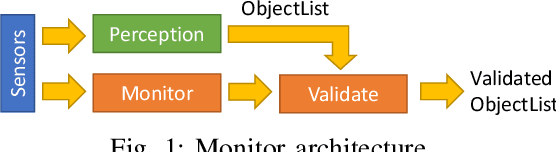
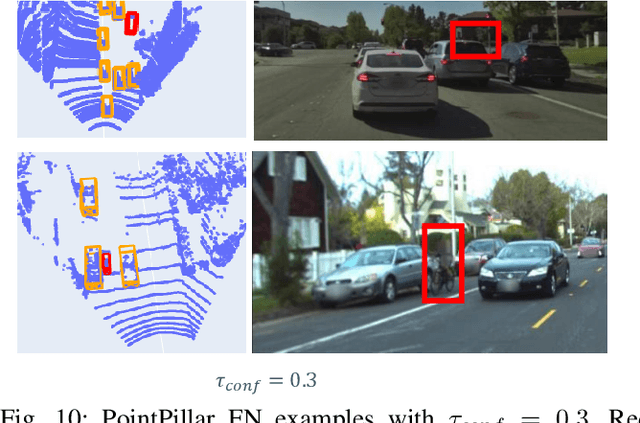

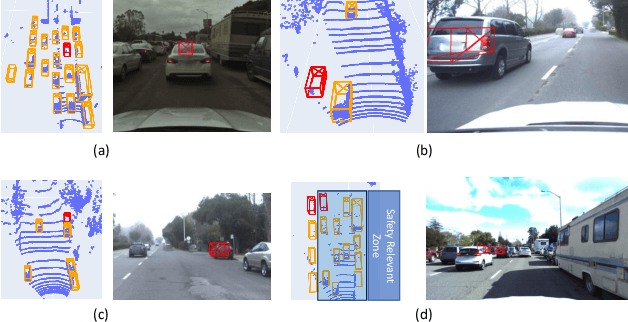
Our transportation world is rapidly transforming induced by an ever increasing level of autonomy. However, to obtain license of fully automated vehicles for widespread public use, it is necessary to assure safety of the entire system, which is still a challenge. This holds in particular for AI-based perception systems that have to handle a diversity of environmental conditions and road users, and at the same time should robustly detect all safety relevant objects (i.e no detection misses should occur). Yet, limited training and validation data make a proof of fault-free operation hardly achievable, as the perception system might be exposed to new, yet unknown objects or conditions on public roads. Hence, new safety approaches for AI-based perception systems are required. For this reason we propose in this paper a novel hierarchical monitoring approach that is able to validate the object list from a primary perception system, can reliably detect detection misses, and at the same time has a very low false alarm rate.
MTBF Model for AVs -- From Perception Errors to Vehicle-Level Failures
May 05, 2022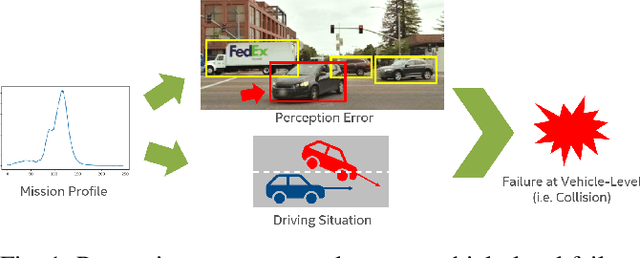
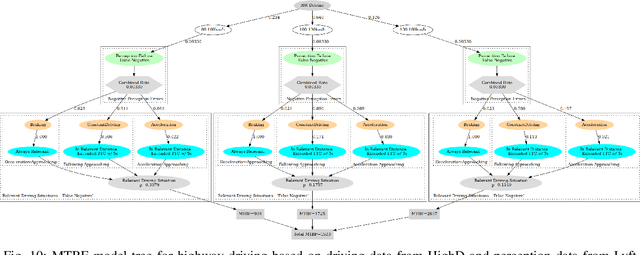
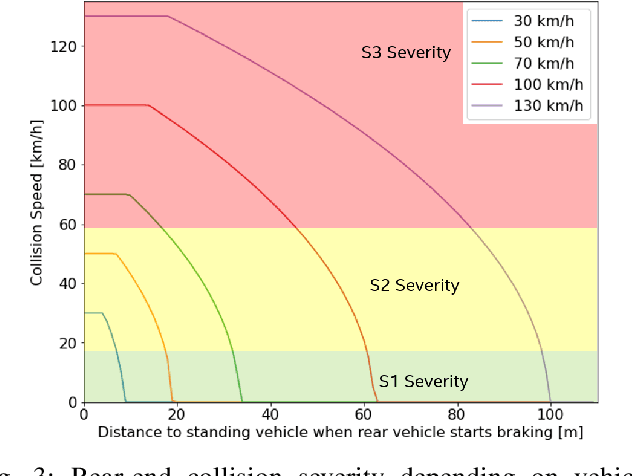
The development of Automated Vehicles (AVs) is progressing quickly and the first robotaxi services are being deployed worldwide. However, to receive authority certification for mass deployment, manufactures need to justify that their AVs operate safer than human drivers. This in turn creates the need to estimate and model the collision rate (failure rate) of an AV taking all possible errors and driving situations into account. In other words, there is the strong demand for comprehensive Mean Time Between Failure (MTBF) models for AVs. In this paper, we will introduce such a generic and scalable model that creates a link between errors in the perception system to vehicle-level failures (collisions). Using this model, we are able to derive requirements for the perception quality based on the desired vehicle-level MTBF or vice versa to obtain an MTBF value given a certain mission profile and perception quality.
Robustness of Object Detectors in Degrading Weather Conditions
Jun 16, 2021

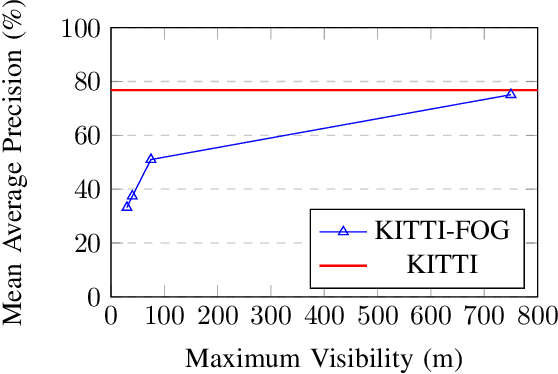
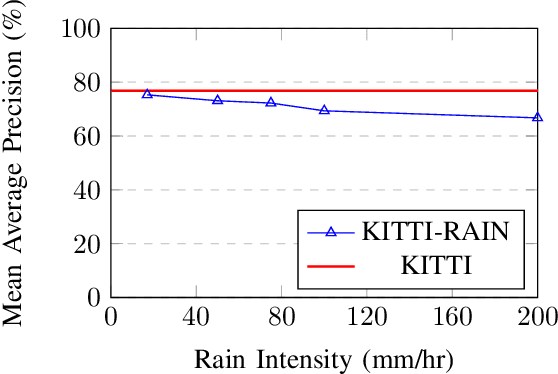
State-of-the-art object detection systems for autonomous driving achieve promising results in clear weather conditions. However, such autonomous safety critical systems also need to work in degrading weather conditions, such as rain, fog and snow. Unfortunately, most approaches evaluate only on the KITTI dataset, which consists only of clear weather scenes. In this paper we address this issue and perform one of the most detailed evaluation on single and dual modality architectures on data captured in real weather conditions. We analyse the performance degradation of these architectures in degrading weather conditions. We demonstrate that an object detection architecture performing good in clear weather might not be able to handle degrading weather conditions. We also perform ablation studies on the dual modality architectures and show their limitations.
Precise localization relative to 3D Automated Driving map using the Decentralized Kalman filter with Feedback
Jul 25, 2019



This paper represents the novel high precision localization approach for Automated Driving (AD) relative to 3D map. The AD maps are not necessarily flat. Hence, the problem of localization is solved here in 3D. The vehicle motion is modeled as piecewise planner but with vertical curvature which is approximated with clothoids. The localization problem is solved with Decentralized Kalman filter with feedback (DKFF) by fusing all available information. The odometry, visual odometry, GPS, the different sensor and mono camera inputs are fused together to obtain the precise localization relative to map. Polylines and landmarks from the map are dealt in the same way because of the line - point geometrical duality. A set of weak filters are accumulated in the strong tracking approach leading to the precise localization results.