 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVDebloater: Mode-based Adaptive Firmware Debloating for Robotic Vehicles
Jan 30, 2026As the number of embedded devices grows and their functional requirements increase, embedded firmware is becoming increasingly larger, thereby expanding its attack surface. Despite the increase in firmware size, many embedded devices, such as robotic vehicles (RVs), operate in distinct modes, each requiring only a small subset of the firmware code at runtime. We refer to such devices as mode-based embedded devices. Debloating is an approach to reduce attack surfaces by removing or restricting unneeded code, but existing techniques suffer from significant limitations, such as coarse granularity and irreversible code removal, limiting their applicability. To address these limitations, we propose RVDebloater, a novel adaptive debloating technique for mode-based embedded devices that automatically identifies unneeded firmware code for each mode using either static or dynamic analysis, and dynamically debloats the firmware for each mode at the function level at runtime. RVDebloater introduces a new software-based enforcement approach that supports diverse mode-based embedded devices. We implemented RVDebloater using the LLVM compiler and evaluated its efficiency and effectiveness on six different RVs, including both simulated and real ones, with different real-world missions. We find that device requirements change throughout its lifetime for each mode, and that many critical firmware functions can be restricted in other modes, with an average of 85% of functions not being required. The results showed that none of the missions failed after debloating with RVDebloater, indicating that it neither incurred false positives nor false negatives. Further, RVDebloater prunes the firmware call graph by an average of 45% across different firmware. Finally, RVDebloater incurred an average performance overhead of 3.9% and memory overhead of 4% (approximately 0.25 MB) on real RVs.
Systems-Theoretic and Data-Driven Security Analysis in ML-enabled Medical Devices
Jun 18, 2025



The integration of AI/ML into medical devices is rapidly transforming healthcare by enhancing diagnostic and treatment facilities. However, this advancement also introduces serious cybersecurity risks due to the use of complex and often opaque models, extensive interconnectivity, interoperability with third-party peripheral devices, Internet connectivity, and vulnerabilities in the underlying technologies. These factors contribute to a broad attack surface and make threat prevention, detection, and mitigation challenging. Given the highly safety-critical nature of these devices, a cyberattack on these devices can cause the ML models to mispredict, thereby posing significant safety risks to patients. Therefore, ensuring the security of these devices from the time of design is essential. This paper underscores the urgency of addressing the cybersecurity challenges in ML-enabled medical devices at the pre-market phase. We begin by analyzing publicly available data on device recalls and adverse events, and known vulnerabilities, to understand the threat landscape of AI/ML-enabled medical devices and their repercussions on patient safety. Building on this analysis, we introduce a suite of tools and techniques designed by us to assist security analysts in conducting comprehensive premarket risk assessments. Our work aims to empower manufacturers to embed cybersecurity as a core design principle in AI/ML-enabled medical devices, thereby making them safe for patients.
Catch Me if You Can: Detecting Unauthorized Data Use in Deep Learning Models
Sep 10, 2024
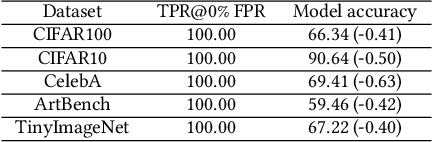
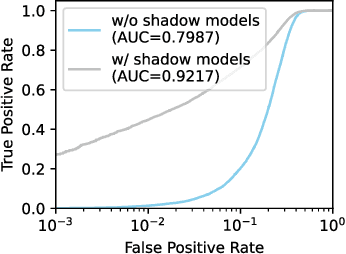
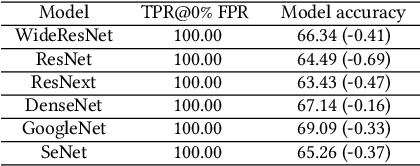
The rise of deep learning (DL) has led to a surging demand for training data, which incentivizes the creators of DL models to trawl through the Internet for training materials. Meanwhile, users often have limited control over whether their data (e.g., facial images) are used to train DL models without their consent, which has engendered pressing concerns. This work proposes MembershipTracker, a practical data provenance tool that can empower ordinary users to take agency in detecting the unauthorized use of their data in training DL models. We view tracing data provenance through the lens of membership inference (MI). MembershipTracker consists of a lightweight data marking component to mark the target data with small and targeted changes, which can be strongly memorized by the model trained on them; and a specialized MI-based verification process to audit whether the model exhibits strong memorization on the target samples. Overall, MembershipTracker only requires the users to mark a small fraction of data (0.005% to 0.1% in proportion to the training set), and it enables the users to reliably detect the unauthorized use of their data (average 0% FPR@100% TPR). We show that MembershipTracker is highly effective across various settings, including industry-scale training on the full-size ImageNet-1k dataset. We finally evaluate MembershipTracker under multiple classes of countermeasures.
SpecGuard: Specification Aware Recovery for Robotic Autonomous Vehicles from Physical Attacks
Aug 27, 2024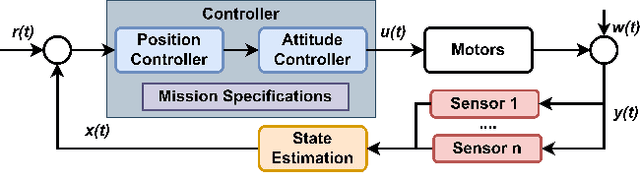
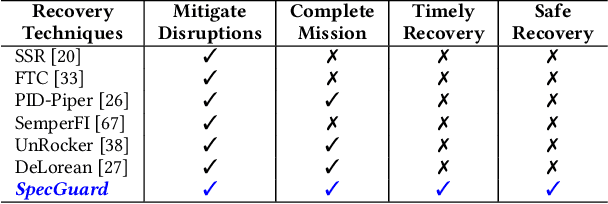
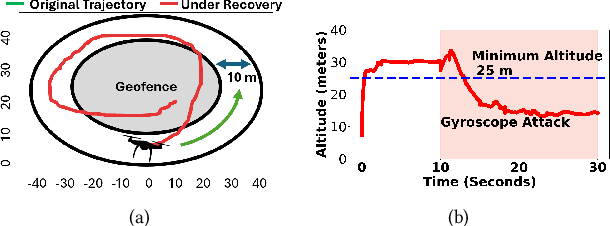

Robotic Autonomous Vehicles (RAVs) rely on their sensors for perception, and follow strict mission specifications (e.g., altitude, speed, and geofence constraints) for safe and timely operations. Physical attacks can corrupt the RAVs' sensors, resulting in mission failures. Recovering RAVs from such attacks demands robust control techniques that maintain compliance with mission specifications even under attacks to ensure the RAV's safety and timely operations. We propose SpecGuard, a technique that complies with mission specifications and performs safe recovery of RAVs. There are two innovations in SpecGuard. First, it introduces an approach to incorporate mission specifications and learn a recovery control policy using Deep Reinforcement Learning (Deep-RL). We design a compliance-based reward structure that reflects the RAV's complex dynamics and enables SpecGuard to satisfy multiple mission specifications simultaneously. Second, SpecGuard incorporates state reconstruction, a technique that minimizes attack induced sensor perturbations. This reconstruction enables effective adversarial training, and optimizing the recovery control policy for robustness under attacks. We evaluate SpecGuard in both virtual and real RAVs, and find that it achieves 92% recovery success rate under attacks on different sensors, without any crashes or stalls. SpecGuard achieves 2X higher recovery success than prior work, and incurs about 15% performance overhead on real RAVs.
A Method to Facilitate Membership Inference Attacks in Deep Learning Models
Jul 02, 2024Modern machine learning (ML) ecosystems offer a surging number of ML frameworks and code repositories that can greatly facilitate the development of ML models. Today, even ordinary data holders who are not ML experts can apply off-the-shelf codebase to build high-performance ML models on their data, many of which are sensitive in nature (e.g., clinical records). In this work, we consider a malicious ML provider who supplies model-training code to the data holders, does not have access to the training process, and has only black-box query access to the resulting model. In this setting, we demonstrate a new form of membership inference attack that is strictly more powerful than prior art. Our attack empowers the adversary to reliably de-identify all the training samples (average >99% attack TPR@0.1% FPR), and the compromised models still maintain competitive performance as their uncorrupted counterparts (average <1% accuracy drop). Moreover, we show that the poisoned models can effectively disguise the amplified membership leakage under common membership privacy auditing, which can only be revealed by a set of secret samples known by the adversary. Overall, our study not only points to the worst-case membership privacy leakage, but also unveils a common pitfall underlying existing privacy auditing methods, which calls for future efforts to rethink the current practice of auditing membership privacy in machine learning models.
Global Clipper: Enhancing Safety and Reliability of Transformer-based Object Detection Models
Jun 05, 2024As transformer-based object detection models progress, their impact in critical sectors like autonomous vehicles and aviation is expected to grow. Soft errors causing bit flips during inference have significantly impacted DNN performance, altering predictions. Traditional range restriction solutions for CNNs fall short for transformers. This study introduces the Global Clipper and Global Hybrid Clipper, effective mitigation strategies specifically designed for transformer-based models. It significantly enhances their resilience to soft errors and reduces faulty inferences to ~ 0\%. We also detail extensive testing across over 64 scenarios involving two transformer models (DINO-DETR and Lite-DETR) and two CNN models (YOLOv3 and SSD) using three datasets, totalling approximately 3.3 million inferences, to assess model robustness comprehensively. Moreover, the paper explores unique aspects of attention blocks in transformers and their operational differences from CNNs.
Systematically Assessing the Security Risks of AI/ML-enabled Connected Healthcare Systems
Jan 30, 2024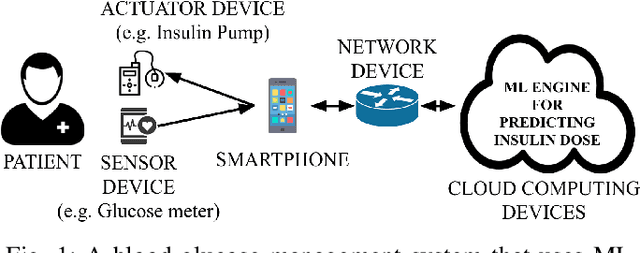
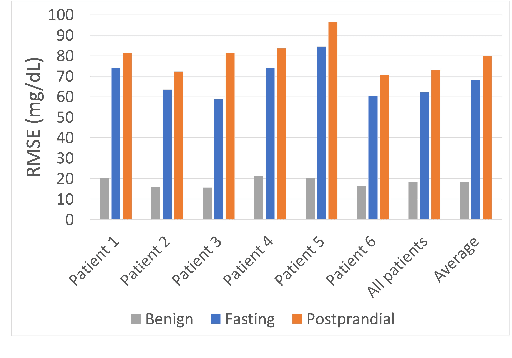
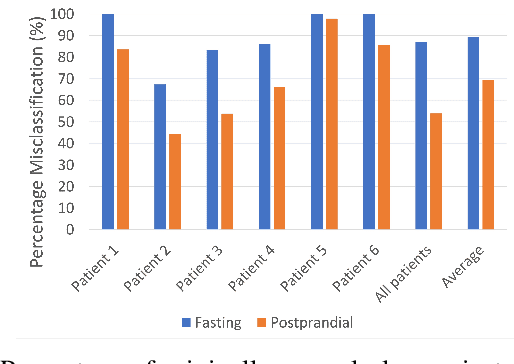
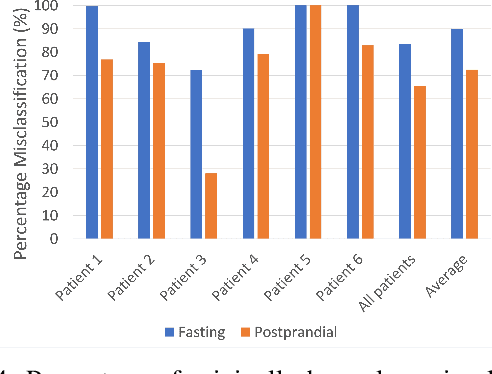
The adoption of machine-learning-enabled systems in the healthcare domain is on the rise. While the use of ML in healthcare has several benefits, it also expands the threat surface of medical systems. We show that the use of ML in medical systems, particularly connected systems that involve interfacing the ML engine with multiple peripheral devices, has security risks that might cause life-threatening damage to a patient's health in case of adversarial interventions. These new risks arise due to security vulnerabilities in the peripheral devices and communication channels. We present a case study where we demonstrate an attack on an ML-enabled blood glucose monitoring system by introducing adversarial data points during inference. We show that an adversary can achieve this by exploiting a known vulnerability in the Bluetooth communication channel connecting the glucose meter with the ML-enabled app. We further show that state-of-the-art risk assessment techniques are not adequate for identifying and assessing these new risks. Our study highlights the need for novel risk analysis methods for analyzing the security of AI-enabled connected health devices.
A Low-cost Strategic Monitoring Approach for Scalable and Interpretable Error Detection in Deep Neural Networks
Oct 31, 2023We present a highly compact run-time monitoring approach for deep computer vision networks that extracts selected knowledge from only a few (down to merely two) hidden layers, yet can efficiently detect silent data corruption originating from both hardware memory and input faults. Building on the insight that critical faults typically manifest as peak or bulk shifts in the activation distribution of the affected network layers, we use strategically placed quantile markers to make accurate estimates about the anomaly of the current inference as a whole. Importantly, the detector component itself is kept algorithmically transparent to render the categorization of regular and abnormal behavior interpretable to a human. Our technique achieves up to ~96% precision and ~98% recall of detection. Compared to state-of-the-art anomaly detection techniques, this approach requires minimal compute overhead (as little as 0.3% with respect to non-supervised inference time) and contributes to the explainability of the model.
Overconfidence is a Dangerous Thing: Mitigating Membership Inference Attacks by Enforcing Less Confident Prediction
Jul 04, 2023



Machine learning (ML) models are vulnerable to membership inference attacks (MIAs), which determine whether a given input is used for training the target model. While there have been many efforts to mitigate MIAs, they often suffer from limited privacy protection, large accuracy drop, and/or requiring additional data that may be difficult to acquire. This work proposes a defense technique, HAMP that can achieve both strong membership privacy and high accuracy, without requiring extra data. To mitigate MIAs in different forms, we observe that they can be unified as they all exploit the ML model's overconfidence in predicting training samples through different proxies. This motivates our design to enforce less confident prediction by the model, hence forcing the model to behave similarly on the training and testing samples. HAMP consists of a novel training framework with high-entropy soft labels and an entropy-based regularizer to constrain the model's prediction while still achieving high accuracy. To further reduce privacy risk, HAMP uniformly modifies all the prediction outputs to become low-confidence outputs while preserving the accuracy, which effectively obscures the differences between the prediction on members and non-members. We conduct extensive evaluation on five benchmark datasets, and show that HAMP provides consistently high accuracy and strong membership privacy. Our comparison with seven state-of-the-art defenses shows that HAMP achieves a superior privacy-utility trade off than those techniques.
Replay-based Recovery for Autonomous Robotic Vehicles from Sensor Deception Attacks
Sep 17, 2022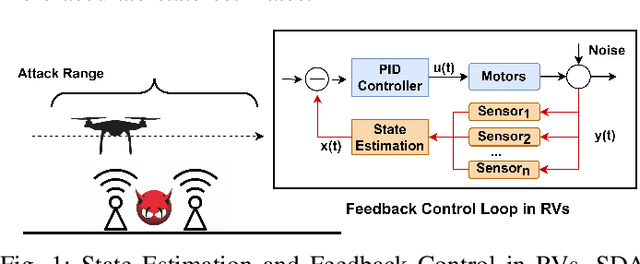
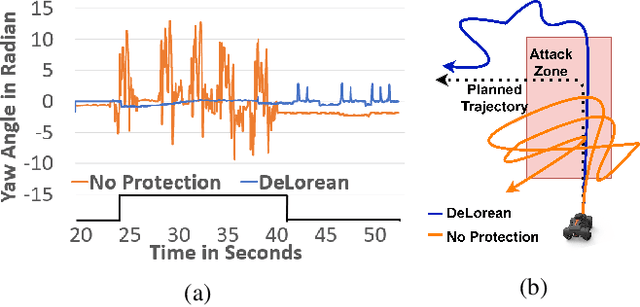
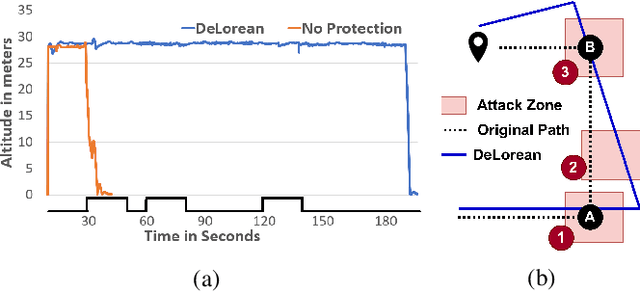
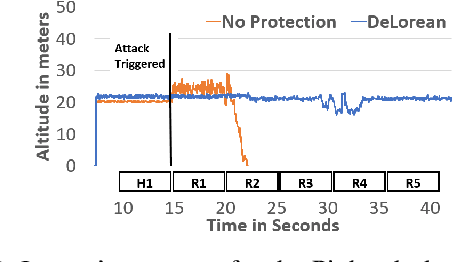
Sensors are crucial for autonomous operation in robotic vehicles (RV). Physical attacks on sensors such as sensor tampering or spoofing can feed erroneous values to RVs through physical channels, which results in mission failures. In this paper, we present DeLorean, a comprehensive diagnosis and recovery framework for securing autonomous RVs from physical attacks. We consider a strong form of physical attack called sensor deception attacks (SDAs), in which the adversary targets multiple sensors of different types simultaneously (even including all sensors). Under SDAs, DeLorean inspects the attack induced errors, identifies the targeted sensors, and prevents the erroneous sensor inputs from being used in RV's feedback control loop. DeLorean replays historic state information in the feedback control loop and recovers the RV from attacks. Our evaluation on four real and two simulated RVs shows that DeLorean can recover RVs from different attacks, and ensure mission success in 94% of the cases (on average), without any crashes. DeLorean incurs low performance, memory and battery overheads.