 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch Me if You Can: Detecting Unauthorized Data Use in Deep Learning Models
Sep 10, 2024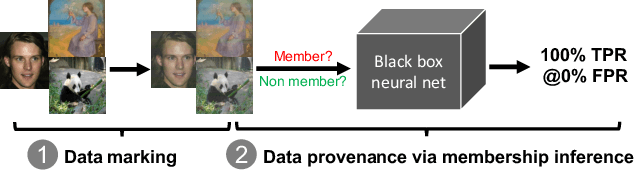
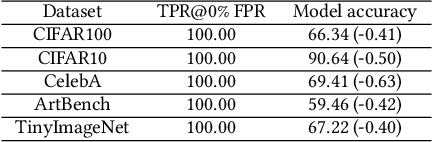
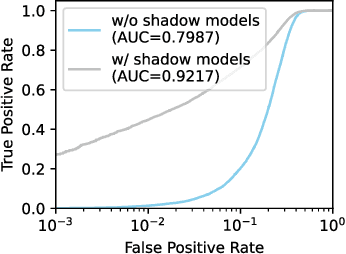
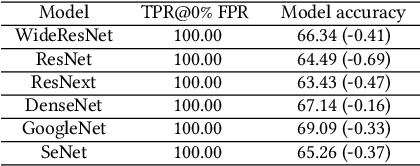
The rise of deep learning (DL) has led to a surging demand for training data, which incentivizes the creators of DL models to trawl through the Internet for training materials. Meanwhile, users often have limited control over whether their data (e.g., facial images) are used to train DL models without their consent, which has engendered pressing concerns. This work proposes MembershipTracker, a practical data provenance tool that can empower ordinary users to take agency in detecting the unauthorized use of their data in training DL models. We view tracing data provenance through the lens of membership inference (MI). MembershipTracker consists of a lightweight data marking component to mark the target data with small and targeted changes, which can be strongly memorized by the model trained on them; and a specialized MI-based verification process to audit whether the model exhibits strong memorization on the target samples. Overall, MembershipTracker only requires the users to mark a small fraction of data (0.005% to 0.1% in proportion to the training set), and it enables the users to reliably detect the unauthorized use of their data (average 0% FPR@100% TPR). We show that MembershipTracker is highly effective across various settings, including industry-scale training on the full-size ImageNet-1k dataset. We finally evaluate MembershipTracker under multiple classes of countermeasures.
A Method to Facilitate Membership Inference Attacks in Deep Learning Models
Jul 02, 2024Modern machine learning (ML) ecosystems offer a surging number of ML frameworks and code repositories that can greatly facilitate the development of ML models. Today, even ordinary data holders who are not ML experts can apply off-the-shelf codebase to build high-performance ML models on their data, many of which are sensitive in nature (e.g., clinical records). In this work, we consider a malicious ML provider who supplies model-training code to the data holders, does not have access to the training process, and has only black-box query access to the resulting model. In this setting, we demonstrate a new form of membership inference attack that is strictly more powerful than prior art. Our attack empowers the adversary to reliably de-identify all the training samples (average >99% attack TPR@0.1% FPR), and the compromised models still maintain competitive performance as their uncorrupted counterparts (average <1% accuracy drop). Moreover, we show that the poisoned models can effectively disguise the amplified membership leakage under common membership privacy auditing, which can only be revealed by a set of secret samples known by the adversary. Overall, our study not only points to the worst-case membership privacy leakage, but also unveils a common pitfall underlying existing privacy auditing methods, which calls for future efforts to rethink the current practice of auditing membership privacy in machine learning models.
Overconfidence is a Dangerous Thing: Mitigating Membership Inference Attacks by Enforcing Less Confident Prediction
Jul 04, 2023



Machine learning (ML) models are vulnerable to membership inference attacks (MIAs), which determine whether a given input is used for training the target model. While there have been many efforts to mitigate MIAs, they often suffer from limited privacy protection, large accuracy drop, and/or requiring additional data that may be difficult to acquire. This work proposes a defense technique, HAMP that can achieve both strong membership privacy and high accuracy, without requiring extra data. To mitigate MIAs in different forms, we observe that they can be unified as they all exploit the ML model's overconfidence in predicting training samples through different proxies. This motivates our design to enforce less confident prediction by the model, hence forcing the model to behave similarly on the training and testing samples. HAMP consists of a novel training framework with high-entropy soft labels and an entropy-based regularizer to constrain the model's prediction while still achieving high accuracy. To further reduce privacy risk, HAMP uniformly modifies all the prediction outputs to become low-confidence outputs while preserving the accuracy, which effectively obscures the differences between the prediction on members and non-members. We conduct extensive evaluation on five benchmark datasets, and show that HAMP provides consistently high accuracy and strong membership privacy. Our comparison with seven state-of-the-art defenses shows that HAMP achieves a superior privacy-utility trade off than those techniques.
Turning Your Strength against You: Detecting and Mitigating Robust and Universal Adversarial Patch Attack
Aug 11, 2021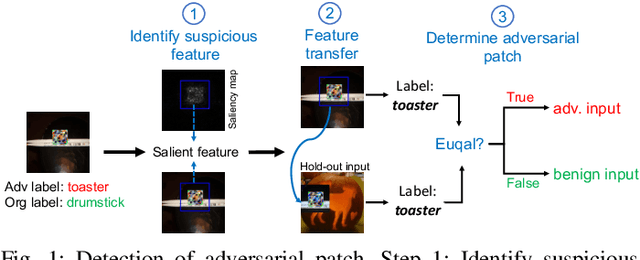
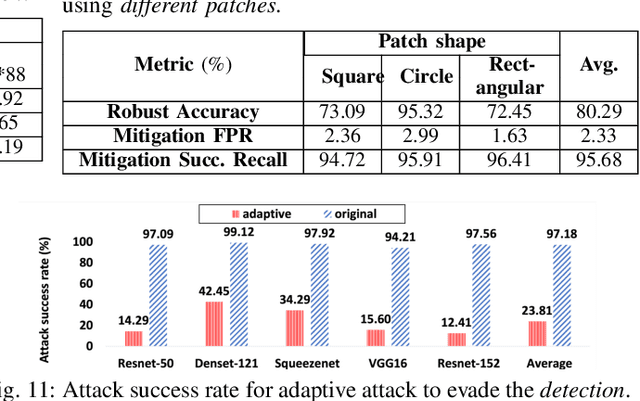
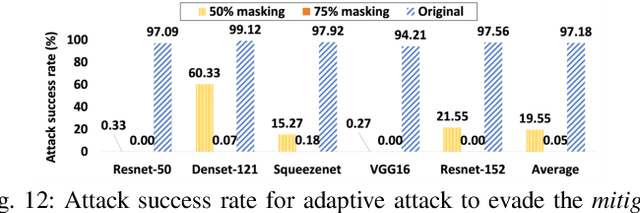

Adversarial patch attack against image classification deep neural networks (DNNs), in which the attacker can inject arbitrary distortions within a bounded region of an image, is able to generate adversarial perturbations that are robust (i.e., remain adversarial in physical world) and universal (i.e., remain adversarial on any input). It is thus important to detect and mitigate such attack to ensure the security of DNNs. This work proposes Jujutsu, a technique to detect and mitigate robust and universal adversarial patch attack. Jujutsu leverages the universal property of the patch attack for detection. It uses explainable AI technique to identify suspicious features that are potentially malicious, and verify their maliciousness by transplanting the suspicious features to new images. An adversarial patch continues to exhibit the malicious behavior on the new images and thus can be detected based on prediction consistency. Jujutsu leverages the localized nature of the patch attack for mitigation, by randomly masking the suspicious features to "remove" adversarial perturbations. However, the network might fail to classify the images as some of the contents are removed (masked). Therefore, Jujutsu uses image inpainting for synthesizing alternative contents from the pixels that are masked, which can reconstruct the "clean" image for correct prediction. We evaluate Jujutsu on five DNNs on two datasets, and show that Jujutsu achieves superior performance and significantly outperforms existing techniques. Jujutsu can further defend against various variants of the basic attack, including 1) physical-world attack; 2) attacks that target diverse classes; 3) attacks that use patches in different shapes and 4) adaptive attacks.
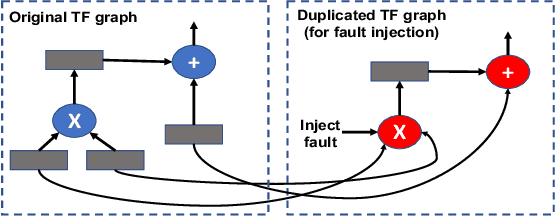
TensorFI: A Flexible Fault Injection Framework for TensorFlow Applications
Apr 03, 2020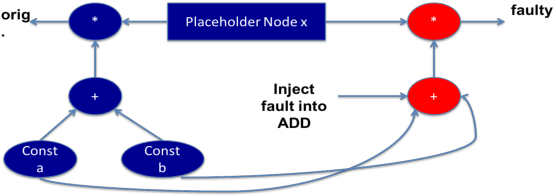

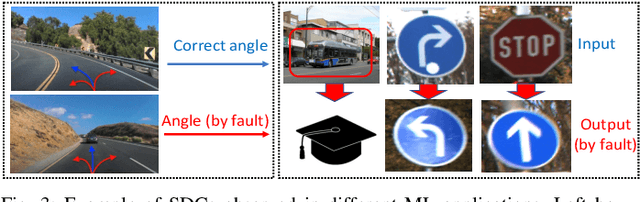
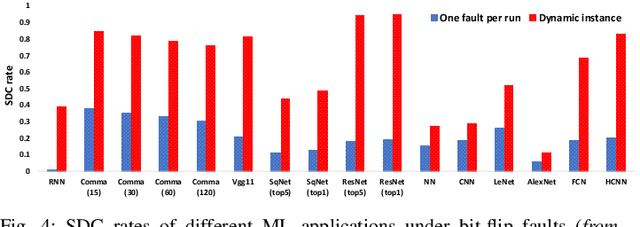
As machine learning (ML) has seen increasing adoption in safety-critical domains (e.g., autonomous vehicles), the reliability of ML systems has also grown in importance. While prior studies have proposed techniques to enable efficient error-resilience techniques (e.g., selective instruction duplication), a fundamental requirement for realizing these techniques is a detailed understanding of the application's resilience. In this work, we present TensorFI, a high-level fault injection (FI) framework for TensorFlow-based applications. TensorFI is able to inject both hardware and software faults in general TensorFlow programs. TensorFI is a configurable FI tool that is flexible, easy to use, and portable. It can be integrated into existing TensorFlow programs to assess their resilience for different fault types (e.g., faults in particular operators). We use TensorFI to evaluate the resilience of 12 ML programs, including DNNs used in the autonomous vehicle domain. Our tool is publicly available at https://github.com/DependableSystemsLab/TensorFI.
Ranger: Boosting Error Resilience of Deep Neural Networks through Range Restriction
Mar 30, 2020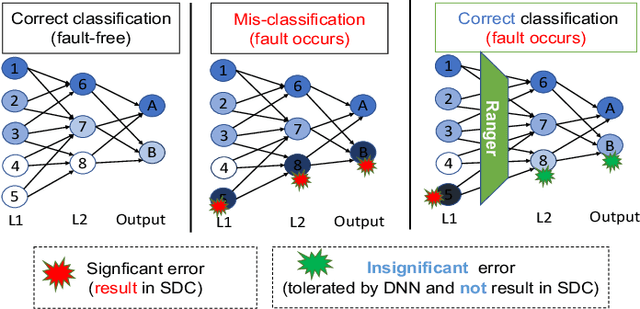
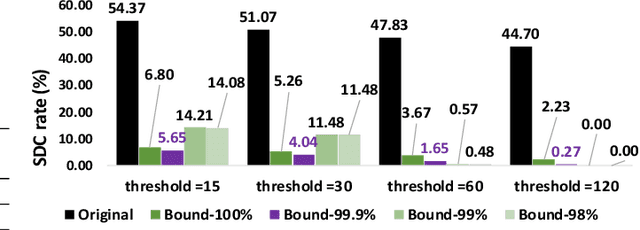

With the emerging adoption of deep neural networks (DNNs) in the HPC domain, the reliability of DNNs is also growing in importance. As prior studies demonstrate the vulnerability of DNNs to hardware transient faults (i.e., soft errors), there is a compelling need for an efficient technique to protect DNNs from soft errors. While the inherent resilience of DNNs can tolerate some transient faults (which would not affect the system's output), prior work has found there are critical faults that cause safety violations (e.g., misclassification). In this work, we exploit the inherent resilience of DNNs to protect the DNNs from critical faults. In particular, we propose Ranger, an automated technique to selectively restrict the ranges of values in particular DNN layers, which can dampen the large deviations typically caused by critical faults to smaller ones. Such reduced deviations can usually be tolerated by the inherent resilience of DNNs. Ranger can be integrated into existing DNNs without retraining, and with minimal effort. Our evaluation on 8 DNNs (including two used in self-driving car applications) demonstrates that Ranger can achieve significant resilience boosting without degrading the accuracy of the model, and incurring negligible overheads.