 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSA: Compressed Sensing-Based Adaptation of Large Language Models
Feb 05, 2026Parameter-Efficient Fine-Tuning (PEFT) has emerged as a practical paradigm for adapting large language models (LLMs) without updating all parameters. Most existing approaches, such as LoRA and PiSSA, rely on low-rank decompositions of weight updates. However, the low-rank assumption may restrict expressivity, particularly in task-specific adaptation scenarios where singular values are distributed relatively uniformly. To address this limitation, we propose CoSA (Compressed Sensing-Based Adaptation), a new PEFT method extended from compressed sensing theory. Instead of constraining weight updates to a low-rank subspace, CoSA expresses them through fixed random projection matrices and a compact learnable core. We provide a formal theoretical analysis of CoSA as a synthesis process, proving that weight updates can be compactly encoded into a low-dimensional space and mapped back through random projections. Extensive experimental results show that CoSA provides a principled perspective for efficient and expressive multi-scale model adaptation. Specifically, we evaluate CoSA on 10 diverse tasks, including natural language understanding and generation, employing 5 models of different scales from RoBERTa, Llama, and Qwen families. Across these settings, CoSA consistently matches or outperforms state-of-the-art PEFT methods.
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Jan 06, 2026Memory-Augmented Generation (MAG) extends Large Language Models with external memory to support long-context reasoning, but existing approaches largely rely on semantic similarity over monolithic memory stores, entangling temporal, causal, and entity information. This design limits interpretability and alignment between query intent and retrieved evidence, leading to suboptimal reasoning accuracy. In this paper, we propose MAGMA, a multi-graph agentic memory architecture that represents each memory item across orthogonal semantic, temporal, causal, and entity graphs. MAGMA formulates retrieval as policy-guided traversal over these relational views, enabling query-adaptive selection and structured context construction. By decoupling memory representation from retrieval logic, MAGMA provides transparent reasoning paths and fine-grained control over retrieval. Experiments on LoCoMo and LongMemEval demonstrate that MAGMA consistently outperforms state-of-the-art agentic memory systems in long-horizon reasoning tasks.
YOSO: You-Only-Sample-Once via Compressed Sensing for Graph Neural Network Training
Nov 08, 2024

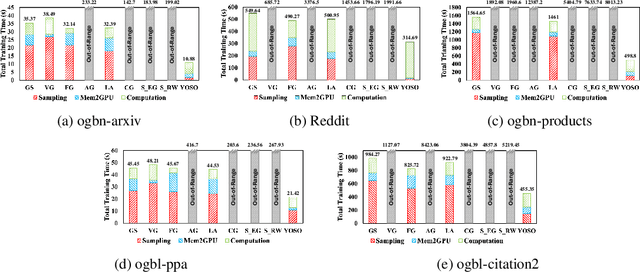

Graph neural networks (GNNs) have become essential tools for analyzing non-Euclidean data across various domains. During training stage, sampling plays an important role in reducing latency by limiting the number of nodes processed, particularly in large-scale applications. However, as the demand for better prediction performance grows, existing sampling algorithms become increasingly complex, leading to significant overhead. To mitigate this, we propose YOSO (You-Only-Sample-Once), an algorithm designed to achieve efficient training while preserving prediction accuracy. YOSO introduces a compressed sensing (CS)-based sampling and reconstruction framework, where nodes are sampled once at input layer, followed by a lossless reconstruction at the output layer per epoch. By integrating the reconstruction process with the loss function of specific learning tasks, YOSO not only avoids costly computations in traditional compressed sensing (CS) methods, such as orthonormal basis calculations, but also ensures high-probability accuracy retention which equivalent to full node participation. Experimental results on node classification and link prediction demonstrate the effectiveness and efficiency of YOSO, reducing GNN training by an average of 75\% compared to state-of-the-art methods, while maintaining accuracy on par with top-performing baselines.
Replay-based Recovery for Autonomous Robotic Vehicles from Sensor Deception Attacks
Sep 17, 2022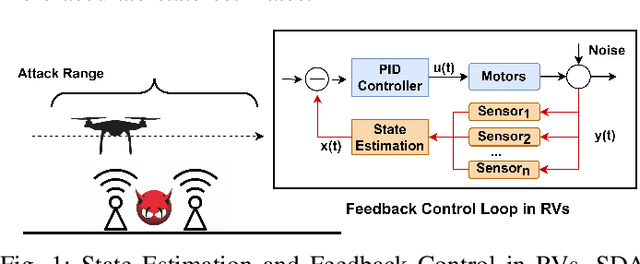
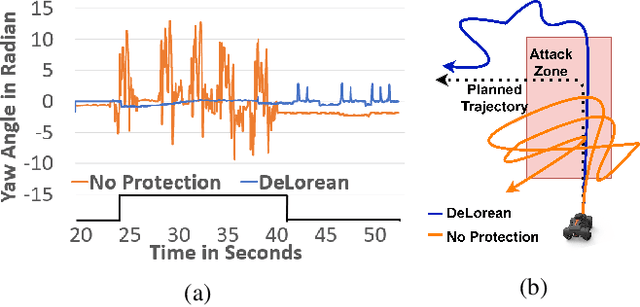
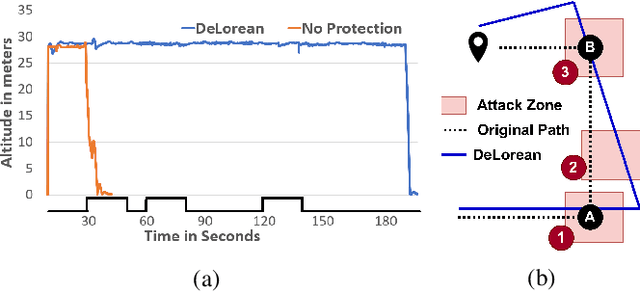
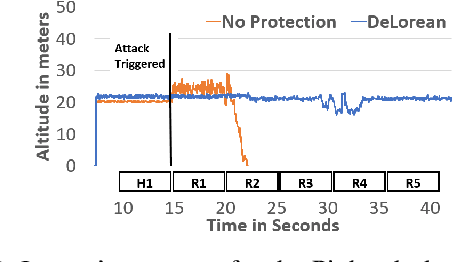
Sensors are crucial for autonomous operation in robotic vehicles (RV). Physical attacks on sensors such as sensor tampering or spoofing can feed erroneous values to RVs through physical channels, which results in mission failures. In this paper, we present DeLorean, a comprehensive diagnosis and recovery framework for securing autonomous RVs from physical attacks. We consider a strong form of physical attack called sensor deception attacks (SDAs), in which the adversary targets multiple sensors of different types simultaneously (even including all sensors). Under SDAs, DeLorean inspects the attack induced errors, identifies the targeted sensors, and prevents the erroneous sensor inputs from being used in RV's feedback control loop. DeLorean replays historic state information in the feedback control loop and recovers the RV from attacks. Our evaluation on four real and two simulated RVs shows that DeLorean can recover RVs from different attacks, and ensure mission success in 94% of the cases (on average), without any crashes. DeLorean incurs low performance, memory and battery overheads.
COMET: A Novel Memory-Efficient Deep Learning Training Framework by Using Error-Bounded Lossy Compression
Nov 18, 2021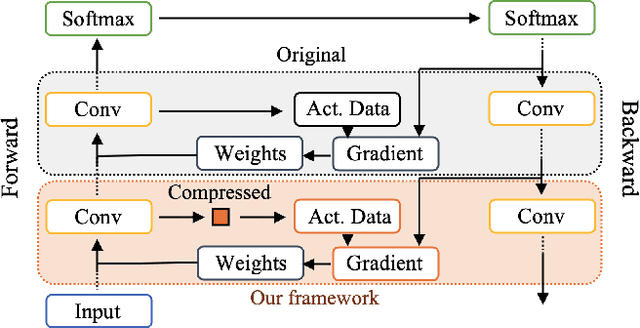
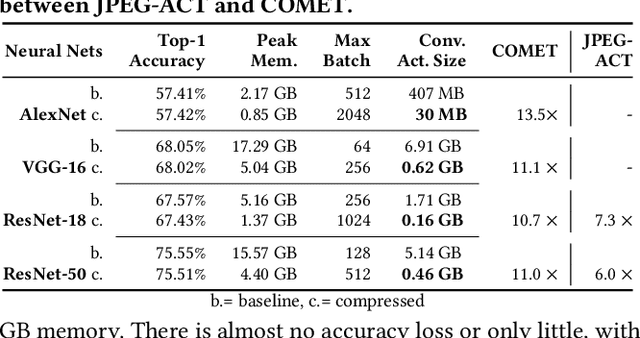
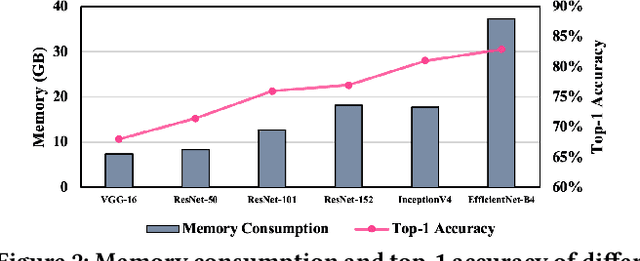
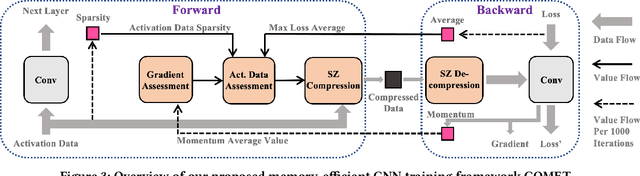
Training wide and deep neural networks (DNNs) require large amounts of storage resources such as memory because the intermediate activation data must be saved in the memory during forward propagation and then restored for backward propagation. However, state-of-the-art accelerators such as GPUs are only equipped with very limited memory capacities due to hardware design constraints, which significantly limits the maximum batch size and hence performance speedup when training large-scale DNNs. Traditional memory saving techniques either suffer from performance overhead or are constrained by limited interconnect bandwidth or specific interconnect technology. In this paper, we propose a novel memory-efficient CNN training framework (called COMET) that leverages error-bounded lossy compression to significantly reduce the memory requirement for training, to allow training larger models or to accelerate training. Different from the state-of-the-art solutions that adopt image-based lossy compressors (such as JPEG) to compress the activation data, our framework purposely adopts error-bounded lossy compression with a strict error-controlling mechanism. Specifically, we perform a theoretical analysis on the compression error propagation from the altered activation data to the gradients, and empirically investigate the impact of altered gradients over the training process. Based on these analyses, we optimize the error-bounded lossy compression and propose an adaptive error-bound control scheme for activation data compression. We evaluate our design against state-of-the-art solutions with five widely-adopted CNNs and ImageNet dataset. Experiments demonstrate that our proposed framework can significantly reduce the training memory consumption by up to 13.5X over the baseline training and 1.8X over another state-of-the-art compression-based framework, respectively, with little or no accuracy loss.
A Novel Memory-Efficient Deep Learning Training Framework via Error-Bounded Lossy Compression
Nov 18, 2020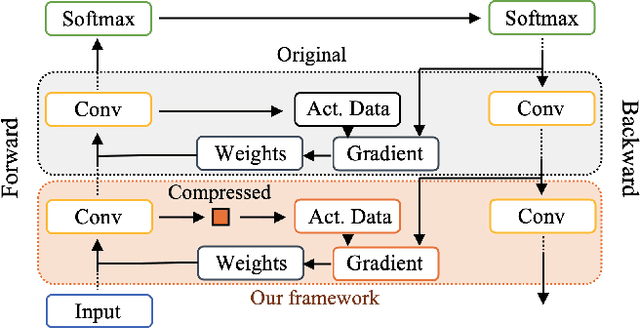
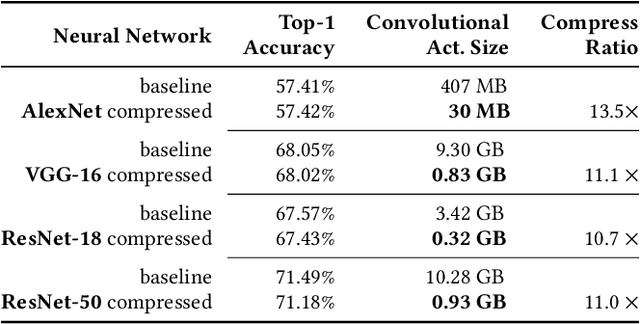
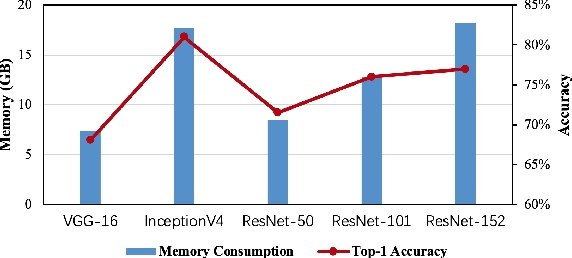
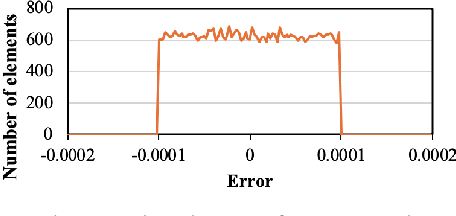
Deep neural networks (DNNs) are becoming increasingly deeper, wider, and non-linear due to the growing demands on prediction accuracy and analysis quality. When training a DNN model, the intermediate activation data must be saved in the memory during forward propagation and then restored for backward propagation. However, state-of-the-art accelerators such as GPUs are only equipped with very limited memory capacities due to hardware design constraints, which significantly limits the maximum batch size and hence performance speedup when training large-scale DNNs. In this paper, we propose a novel memory-driven high performance DNN training framework that leverages error-bounded lossy compression to significantly reduce the memory requirement for training in order to allow training larger networks. Different from the state-of-the-art solutions that adopt image-based lossy compressors such as JPEG to compress the activation data, our framework purposely designs error-bounded lossy compression with a strict error-controlling mechanism. Specifically, we provide theoretical analysis on the compression error propagation from the altered activation data to the gradients, and then empirically investigate the impact of altered gradients over the entire training process. Based on these analyses, we then propose an improved lossy compressor and an adaptive scheme to dynamically configure the lossy compression error-bound and adjust the training batch size to further utilize the saved memory space for additional speedup. We evaluate our design against state-of-the-art solutions with four popular DNNs and the ImageNet dataset. Results demonstrate that our proposed framework can significantly reduce the training memory consumption by up to 13.5x and 1.8x over the baseline training and state-of-the-art framework with compression, respectively, with little or no accuracy loss.
TensorFI: A Flexible Fault Injection Framework for TensorFlow Applications
Apr 03, 2020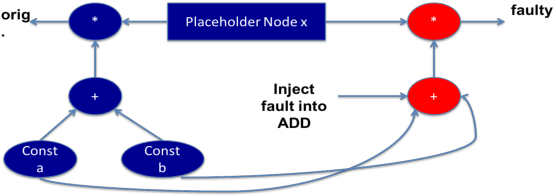

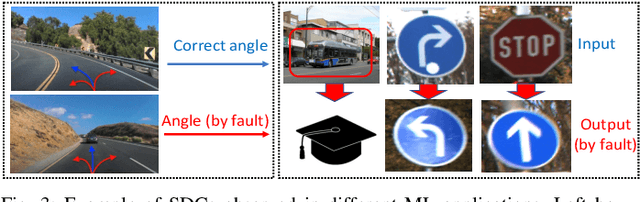
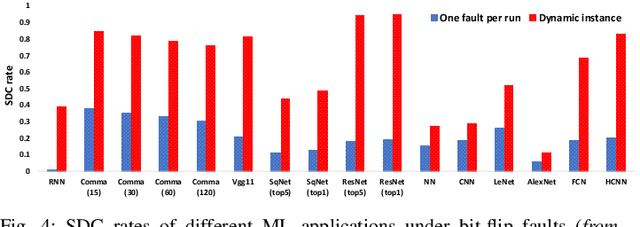
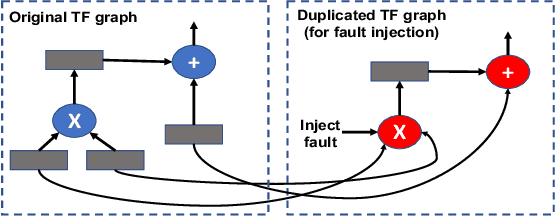
As machine learning (ML) has seen increasing adoption in safety-critical domains (e.g., autonomous vehicles), the reliability of ML systems has also grown in importance. While prior studies have proposed techniques to enable efficient error-resilience techniques (e.g., selective instruction duplication), a fundamental requirement for realizing these techniques is a detailed understanding of the application's resilience. In this work, we present TensorFI, a high-level fault injection (FI) framework for TensorFlow-based applications. TensorFI is able to inject both hardware and software faults in general TensorFlow programs. TensorFI is a configurable FI tool that is flexible, easy to use, and portable. It can be integrated into existing TensorFlow programs to assess their resilience for different fault types (e.g., faults in particular operators). We use TensorFI to evaluate the resilience of 12 ML programs, including DNNs used in the autonomous vehicle domain. Our tool is publicly available at https://github.com/DependableSystemsLab/TensorFI.
Ranger: Boosting Error Resilience of Deep Neural Networks through Range Restriction
Mar 30, 2020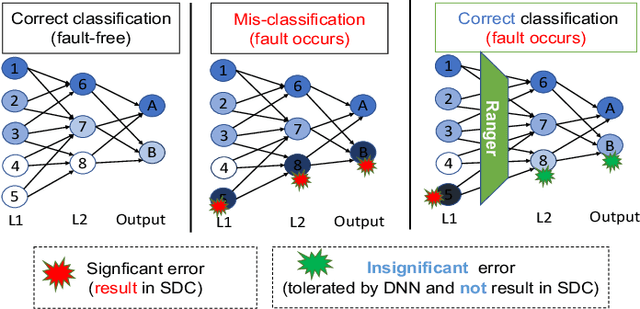
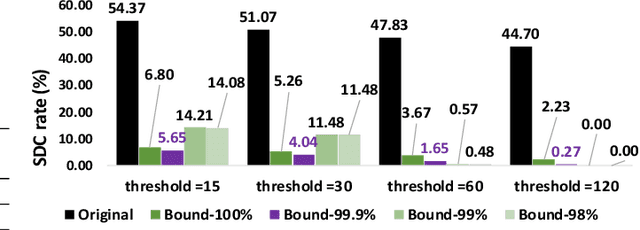

With the emerging adoption of deep neural networks (DNNs) in the HPC domain, the reliability of DNNs is also growing in importance. As prior studies demonstrate the vulnerability of DNNs to hardware transient faults (i.e., soft errors), there is a compelling need for an efficient technique to protect DNNs from soft errors. While the inherent resilience of DNNs can tolerate some transient faults (which would not affect the system's output), prior work has found there are critical faults that cause safety violations (e.g., misclassification). In this work, we exploit the inherent resilience of DNNs to protect the DNNs from critical faults. In particular, we propose Ranger, an automated technique to selectively restrict the ranges of values in particular DNN layers, which can dampen the large deviations typically caused by critical faults to smaller ones. Such reduced deviations can usually be tolerated by the inherent resilience of DNNs. Ranger can be integrated into existing DNNs without retraining, and with minimal effort. Our evaluation on 8 DNNs (including two used in self-driving car applications) demonstrates that Ranger can achieve significant resilience boosting without degrading the accuracy of the model, and incurring negligible overheads.