 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Query Segmentation in the Wild
Mar 09, 2026In this paper, we introduce visual query segmentation (VQS), a new paradigm of visual query localization (VQL) that aims to segment all pixel-level occurrences of an object of interest in an untrimmed video, given an external visual query. Compared to existing VQL locating only the last appearance of a target using bounding boxes, VQS enables more comprehensive (i.e., all object occurrences) and precise (i.e., pixel-level masks) localization, making it more practical for real-world scenarios. To foster research on this task, we present VQS-4K, a large-scale benchmark dedicated to VQS. Specifically, VQS-4K contains 4,111 videos with more than 1.3 million frames and covers a diverse set of 222 object categories. Each video is paired with a visual query defined by a frame outside the search video and its target mask, and annotated with spatial-temporal masklets corresponding to the queried target. To ensure high quality, all videos in VQS-4K are manually labeled with meticulous inspection and iterative refinement. To the best of our knowledge, VQS-4K is the first benchmark specifically designed for VQS. Furthermore, to stimulate future research, we present a simple yet effective method, named VQ-SAM, which extends SAM 2 by leveraging target-specific and background distractor cues from the video to progressively evolve the memory through a novel multi-stage framework with an adaptive memory generation (AMG) module for VQS, significantly improving the performance. In our extensive experiments on VQS-4K, VQ-SAM achieves promising results and surpasses all existing approaches, demonstrating its effectiveness. With the proposed VQS-4K and VQ-SAM, we expect to go beyond the current VQL paradigm and inspire more future research and practical applications on VQS. Our benchmark, code, and results will be made publicly available.
Initial Risk Probing and Feasibility Testing of Glow: a Generative AI-Powered Dialectical Behavior Therapy Skills Coach for Substance Use Recovery and HIV Prevention
Feb 08, 2026Background: HIV and substance use represent interacting epidemics with shared psychological drivers - impulsivity and maladaptive coping. Dialectical behavior therapy (DBT) targets these mechanisms but faces scalability challenges. Generative artificial intelligence (GenAI) offers potential for delivering personalized DBT coaching at scale, yet rapid development has outpaced safety infrastructure. Methods: We developed Glow, a GenAI-powered DBT skills coach delivering chain and solution analysis for individuals at risk for HIV and substance use. In partnership with a Los Angeles community health organization, we conducted usability testing with clinical staff (n=6) and individuals with lived experience (n=28). Using the Helpful, Honest, and Harmless (HHH) framework, we employed user-driven adversarial testing wherein participants identified target behaviors and generated contextually realistic risk probes. We evaluated safety performance across 37 risk probe interactions. Results: Glow appropriately handled 73% of risk probes, but performance varied by agent. The solution analysis agent demonstrated 90% appropriate handling versus 44% for the chain analysis agent. Safety failures clustered around encouraging substance use and normalizing harmful behaviors. The chain analysis agent fell into an "empathy trap," providing validation that reinforced maladaptive beliefs. Additionally, 27 instances of DBT skill misinformation were identified. Conclusions: This study provides the first systematic safety evaluation of GenAI-delivered DBT coaching for HIV and substance use risk reduction. Findings reveal vulnerabilities requiring mitigation before clinical trials. The HHH framework and user-driven adversarial testing offer replicable methods for evaluating GenAI mental health interventions.
OLC-WA: Drift Aware Tuning-Free Online Classification with Weighted Average
Dec 14, 2025


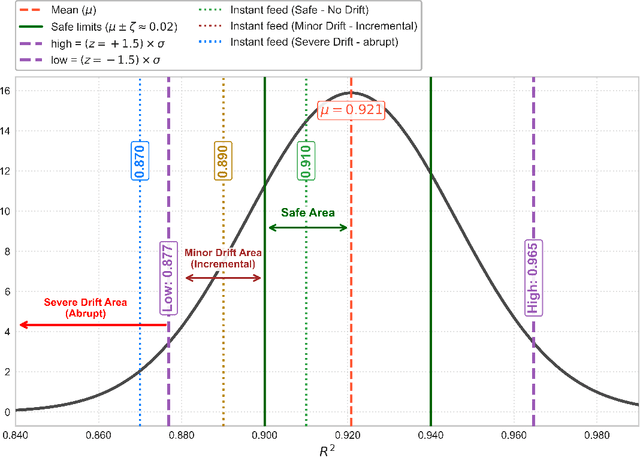
Real-world data sets often exhibit temporal dynamics characterized by evolving data distributions. Disregarding this phenomenon, commonly referred to as concept drift, can significantly diminish a model's predictive accuracy. Furthermore, the presence of hyperparameters in online models exacerbates this issue. These parameters are typically fixed and cannot be dynamically adjusted by the user in response to the evolving data distribution. This paper introduces Online Classification with Weighted Average (OLC-WA), an adaptive, hyperparameter-free online classification model equipped with an automated optimization mechanism. OLC-WA operates by blending incoming data streams with an existing base model. This blending is facilitated by an exponentially weighted moving average. Furthermore, an integrated optimization mechanism dynamically detects concept drift, quantifies its magnitude, and adjusts the model based on the observed data stream characteristics. This approach empowers the model to effectively adapt to evolving data distributions within streaming environments. Rigorous empirical evaluation across diverse benchmark datasets shows that OLC-WA achieves performance comparable to batch models in stationary environments, maintaining accuracy within 1-3%, and surpasses leading online baselines by 10-25% under drift, demonstrating its effectiveness in adapting to dynamic data streams.
Poly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
DP-GTR: Differentially Private Prompt Protection via Group Text Rewriting
Mar 06, 2025



Prompt privacy is crucial, especially when using online large language models (LLMs), due to the sensitive information often contained within prompts. While LLMs can enhance prompt privacy through text rewriting, existing methods primarily focus on document-level rewriting, neglecting the rich, multi-granular representations of text. This limitation restricts LLM utilization to specific tasks, overlooking their generalization and in-context learning capabilities, thus hindering practical application. To address this gap, we introduce DP-GTR, a novel three-stage framework that leverages local differential privacy (DP) and the composition theorem via group text rewriting. DP-GTR is the first framework to integrate both document-level and word-level information while exploiting in-context learning to simultaneously improve privacy and utility, effectively bridging local and global DP mechanisms at the individual data point level. Experiments on CommonSense QA and DocVQA demonstrate that DP-GTR outperforms existing approaches, achieving a superior privacy-utility trade-off. Furthermore, our framework is compatible with existing rewriting techniques, serving as a plug-in to enhance privacy protection. Our code is publicly available at https://github.com/FatShion-FTD/DP-GTR for reproducibility.
PRVQL: Progressive Knowledge-guided Refinement for Robust Egocentric Visual Query Localization
Feb 11, 2025Egocentric visual query localization (EgoVQL) focuses on localizing the target of interest in space and time from first-person videos, given a visual query. Despite recent progressive, existing methods often struggle to handle severe object appearance changes and cluttering background in the video due to lacking sufficient target cues, leading to degradation. Addressing this, we introduce PRVQL, a novel Progressive knowledge-guided Refinement framework for EgoVQL. The core is to continuously exploit target-relevant knowledge directly from videos and utilize it as guidance to refine both query and video features for improving target localization. Our PRVQL contains multiple processing stages. The target knowledge from one stage, comprising appearance and spatial knowledge extracted via two specially designed knowledge learning modules, are utilized as guidance to refine the query and videos features for the next stage, which are used to generate more accurate knowledge for further feature refinement. With such a progressive process, target knowledge in PRVQL can be gradually improved, which, in turn, leads to better refined query and video features for localization in the final stage. Compared to previous methods, our PRVQL, besides the given object cues, enjoys additional crucial target information from a video as guidance to refine features, and hence enhances EgoVQL in complicated scenes. In our experiments on challenging Ego4D, PRVQL achieves state-of-the-art result and largely surpasses other methods, showing its efficacy. Our code, model and results will be released at https://github.com/fb-reps/PRVQL.
Unlocking Cross-Lingual Sentiment Analysis through Emoji Interpretation: A Multimodal Generative AI Approach
Dec 23, 2024



Emojis have become ubiquitous in online communication, serving as a universal medium to convey emotions and decorative elements. Their widespread use transcends language and cultural barriers, enhancing understanding and fostering more inclusive interactions. While existing work gained valuable insight into emojis understanding, exploring emojis' capability to serve as a universal sentiment indicator leveraging large language models (LLMs) has not been thoroughly examined. Our study aims to investigate the capacity of emojis to serve as reliable sentiment markers through LLMs across languages and cultures. We leveraged the multimodal capabilities of ChatGPT to explore the sentiments of various representations of emojis and evaluated how well emoji-conveyed sentiment aligned with text sentiment on a multi-lingual dataset collected from 32 countries. Our analysis reveals that the accuracy of LLM-based emoji-conveyed sentiment is 81.43%, underscoring emojis' significant potential to serve as a universal sentiment marker. We also found a consistent trend that the accuracy of sentiment conveyed by emojis increased as the number of emojis grew in text. The results reinforce the potential of emojis to serve as global sentiment indicators, offering insight into fields such as cross-lingual and cross-cultural sentiment analysis on social media platforms. Code: https://github.com/ResponsibleAILab/emoji-universal-sentiment.
MNIST-Fraction: Enhancing Math Education with AI-Driven Fraction Detection and Analysis
Dec 11, 2024Mathematics education, a crucial and basic field, significantly influences students' learning in related subjects and their future careers. Utilizing artificial intelligence to interpret and comprehend math problems in education is not yet fully explored. This is due to the scarcity of quality datasets and the intricacies of processing handwritten information. In this paper, we present a novel contribution to the field of mathematics education through the development of MNIST-Fraction, a dataset inspired by the renowned MNIST, specifically tailored for the recognition and understanding of handwritten math fractions. Our approach is the utilization of deep learning, specifically Convolutional Neural Networks (CNNs), for the recognition and understanding of handwritten math fractions to effectively detect and analyze fractions, along with their numerators and denominators. This capability is pivotal in calculating the value of fractions, a fundamental aspect of math learning. The MNIST-Fraction dataset is designed to closely mimic real-world scenarios, providing a reliable and relevant resource for AI-driven educational tools. Furthermore, we conduct a comprehensive comparison of our dataset with the original MNIST dataset using various classifiers, demonstrating the effectiveness and versatility of MNIST-Fraction in both detection and classification tasks. This comparative analysis not only validates the practical utility of our dataset but also offers insights into its potential applications in math education. To foster collaboration and further research within the computational and educational communities. Our work aims to bridge the gap in high-quality educational resources for math learning, offering a valuable tool for both educators and researchers in the field.
HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sep 16, 2024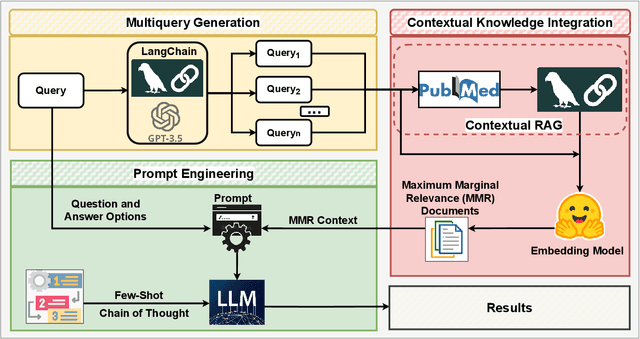
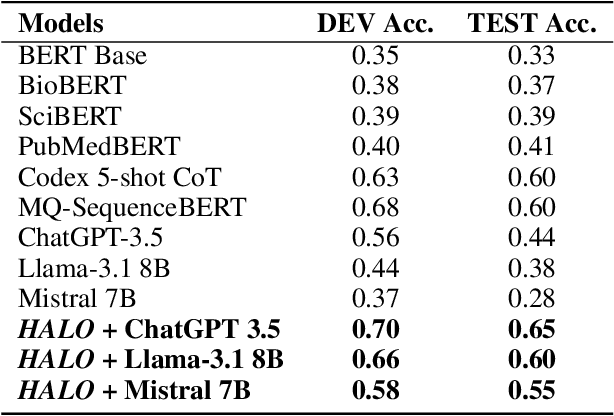


Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.
RedAgent: Red Teaming Large Language Models with Context-aware Autonomous Language Agent
Jul 23, 2024



Recently, advanced Large Language Models (LLMs) such as GPT-4 have been integrated into many real-world applications like Code Copilot. These applications have significantly expanded the attack surface of LLMs, exposing them to a variety of threats. Among them, jailbreak attacks that induce toxic responses through jailbreak prompts have raised critical safety concerns. To identify these threats, a growing number of red teaming approaches simulate potential adversarial scenarios by crafting jailbreak prompts to test the target LLM. However, existing red teaming methods do not consider the unique vulnerabilities of LLM in different scenarios, making it difficult to adjust the jailbreak prompts to find context-specific vulnerabilities. Meanwhile, these methods are limited to refining jailbreak templates using a few mutation operations, lacking the automation and scalability to adapt to different scenarios. To enable context-aware and efficient red teaming, we abstract and model existing attacks into a coherent concept called "jailbreak strategy" and propose a multi-agent LLM system named RedAgent that leverages these strategies to generate context-aware jailbreak prompts. By self-reflecting on contextual feedback in an additional memory buffer, RedAgent continuously learns how to leverage these strategies to achieve effective jailbreaks in specific contexts. Extensive experiments demonstrate that our system can jailbreak most black-box LLMs in just five queries, improving the efficiency of existing red teaming methods by two times. Additionally, RedAgent can jailbreak customized LLM applications more efficiently. By generating context-aware jailbreak prompts towards applications on GPTs, we discover 60 severe vulnerabilities of these real-world applications with only two queries per vulnerability. We have reported all found issues and communicated with OpenAI and Meta for bug fixes.