 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMUS: A Large-Scale Corpus for Legal Argument Mining from U.S. Caselaw using LLMs
Mar 09, 2026Legal argument mining aims to identify and classify the functional components of judicial reasoning, such as facts, issues, rules, analysis, and conclusions. Progress in this area is limited by the lack of large-scale, high-quality annotated datasets for U.S. caselaw, particularly at the state level. This paper introduces LAMUS, a sentence-level legal argument mining corpus constructed from U.S. Supreme Court decisions and Texas criminal appellate opinions. The dataset is created using a data-centric pipeline that combines large-scale case collection, LLM-based automatic annotation, and targeted human-in-the-loop quality refinement. We formulate legal argument mining as a six-class sentence classification task and evaluate multiple general-purpose and legal-domain language models under zero-shot, few-shot, and chain-of-thought prompting strategies, with LegalBERT as a supervised baseline. Results show that chain-of-thought prompting substantially improves LLM performance, while domain-specific models exhibit more stable zero-shot behavior. LLM-assisted verification corrects nearly 20% of annotation errors, improving label consistency. Human verification achieves Cohen's Kappa of 0.85, confirming annotation quality. LAMUS provides a scalable resource and empirical insights for future legal NLP research. All code and datasets can be accessed for reproducibility on GitHub at: https://github.com/LavanyaPobbathi/LAMUS/tree/main
Beyond Human Annotation: Recent Advances in Data Generation Methods for Document Intelligence
Jan 18, 2026The advancement of Document Intelligence (DI) demands large-scale, high-quality training data, yet manual annotation remains a critical bottleneck. While data generation methods are evolving rapidly, existing surveys are constrained by fragmented focuses on single modalities or specific tasks, lacking a unified perspective aligned with real-world workflows. To fill this gap, this survey establishes the first comprehensive technical map for data generation in DI. Data generation is redefined as supervisory signal production, and a novel taxonomy is introduced based on the "availability of data and labels." This framework organizes methodologies into four resource-centric paradigms: Data Augmentation, Data Generation from Scratch, Automated Data Annotation, and Self-Supervised Signal Construction. Furthermore, a multi-level evaluation framework is established to integrate intrinsic quality and extrinsic utility, compiling performance gains across diverse DI benchmarks. Guided by this unified structure, the methodological landscape is dissected to reveal critical challenges such as fidelity gaps and frontiers including co-evolutionary ecosystems. Ultimately, by systematizing this fragmented field, data generation is positioned as the central engine for next-generation DI.
The Evolving Role of Large Language Models in Scientific Innovation: Evaluator, Collaborator, and Scientist
Jul 16, 2025


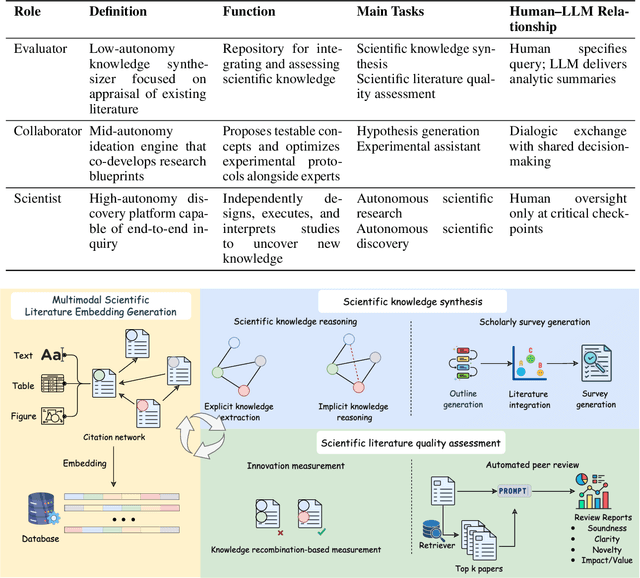
Scientific innovation is undergoing a paradigm shift driven by the rapid advancement of Large Language Models (LLMs). As science faces mounting challenges including information overload, disciplinary silos, and diminishing returns on conventional research methods, LLMs are emerging as powerful agents capable not only of enhancing scientific workflows but also of participating in and potentially leading the innovation process. Existing surveys mainly focus on different perspectives, phrases, and tasks in scientific research and discovery, while they have limitations in understanding the transformative potential and role differentiation of LLM. This survey proposes a comprehensive framework to categorize the evolving roles of LLMs in scientific innovation across three hierarchical levels: Evaluator, Collaborator, and Scientist. We distinguish between LLMs' contributions to structured scientific research processes and open-ended scientific discovery, thereby offering a unified taxonomy that clarifies capability boundaries, evaluation criteria, and human-AI interaction patterns at each level. Through an extensive analysis of current methodologies, benchmarks, systems, and evaluation metrics, this survey delivers an in-depth and systematic synthesis on LLM-driven scientific innovation. We present LLMs not only as tools for automating existing processes, but also as catalysts capable of reshaping the epistemological foundations of science itself. This survey offers conceptual clarity, practical guidance, and theoretical foundations for future research, while also highlighting open challenges and ethical considerations in the pursuit of increasingly autonomous AI-driven science. Resources related to this survey can be accessed on GitHub at: https://github.com/haoxuan-unt2024/llm4innovation.
Unlocking Cross-Lingual Sentiment Analysis through Emoji Interpretation: A Multimodal Generative AI Approach
Dec 23, 2024



Emojis have become ubiquitous in online communication, serving as a universal medium to convey emotions and decorative elements. Their widespread use transcends language and cultural barriers, enhancing understanding and fostering more inclusive interactions. While existing work gained valuable insight into emojis understanding, exploring emojis' capability to serve as a universal sentiment indicator leveraging large language models (LLMs) has not been thoroughly examined. Our study aims to investigate the capacity of emojis to serve as reliable sentiment markers through LLMs across languages and cultures. We leveraged the multimodal capabilities of ChatGPT to explore the sentiments of various representations of emojis and evaluated how well emoji-conveyed sentiment aligned with text sentiment on a multi-lingual dataset collected from 32 countries. Our analysis reveals that the accuracy of LLM-based emoji-conveyed sentiment is 81.43%, underscoring emojis' significant potential to serve as a universal sentiment marker. We also found a consistent trend that the accuracy of sentiment conveyed by emojis increased as the number of emojis grew in text. The results reinforce the potential of emojis to serve as global sentiment indicators, offering insight into fields such as cross-lingual and cross-cultural sentiment analysis on social media platforms. Code: https://github.com/ResponsibleAILab/emoji-universal-sentiment.
A Comparative Study of Quality Evaluation Methods for Text Summarization
Jun 30, 2024
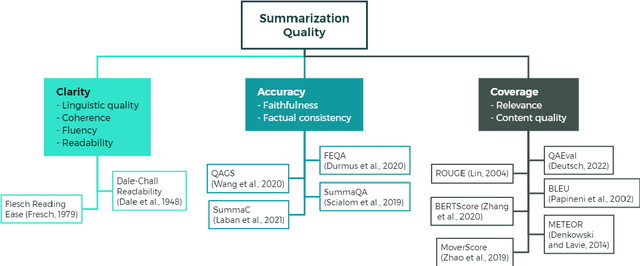


Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
A Survey on Data Quality Dimensions and Tools for Machine Learning
Jun 28, 2024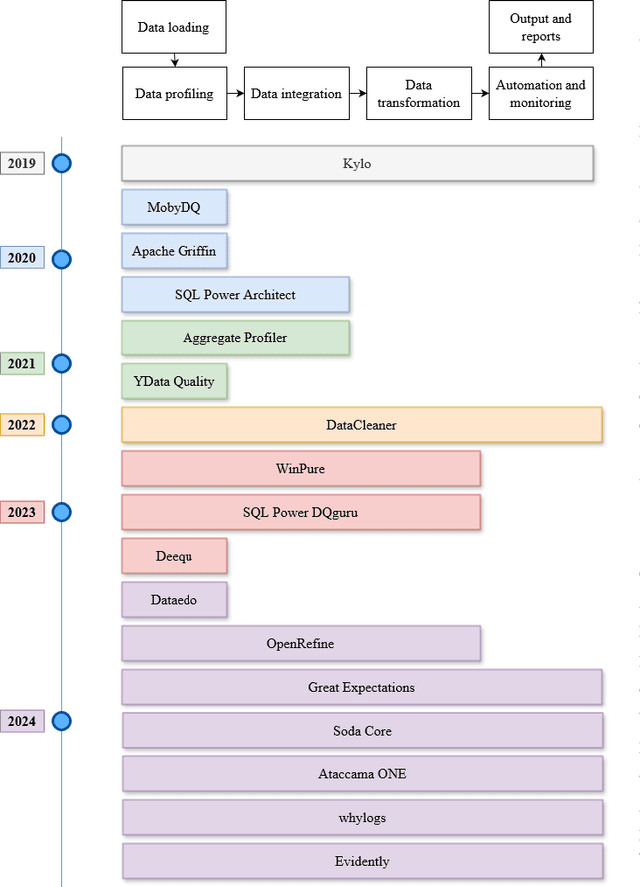

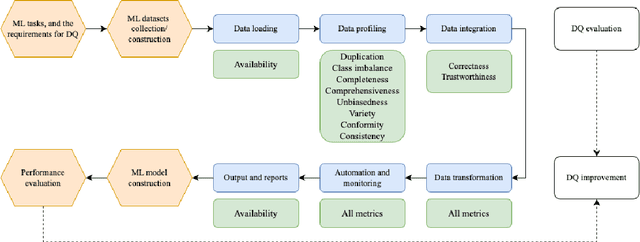
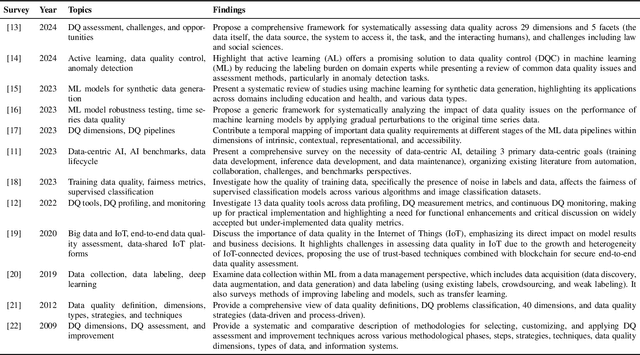
Machine learning (ML) technologies have become substantial in practically all aspects of our society, and data quality (DQ) is critical for the performance, fairness, robustness, safety, and scalability of ML models. With the large and complex data in data-centric AI, traditional methods like exploratory data analysis (EDA) and cross-validation (CV) face challenges, highlighting the importance of mastering DQ tools. In this survey, we review 17 DQ evaluation and improvement tools in the last 5 years. By introducing the DQ dimensions, metrics, and main functions embedded in these tools, we compare their strengths and limitations and propose a roadmap for developing open-source DQ tools for ML. Based on the discussions on the challenges and emerging trends, we further highlight the potential applications of large language models (LLMs) and generative AI in DQ evaluation and improvement for ML. We believe this comprehensive survey can enhance understanding of DQ in ML and could drive progress in data-centric AI. A complete list of the literature investigated in this survey is available on GitHub at: https://github.com/haihua0913/awesome-dq4ml.
Data Curation and Quality Assurance for Machine Learning-based Cyber Intrusion Detection
May 20, 2021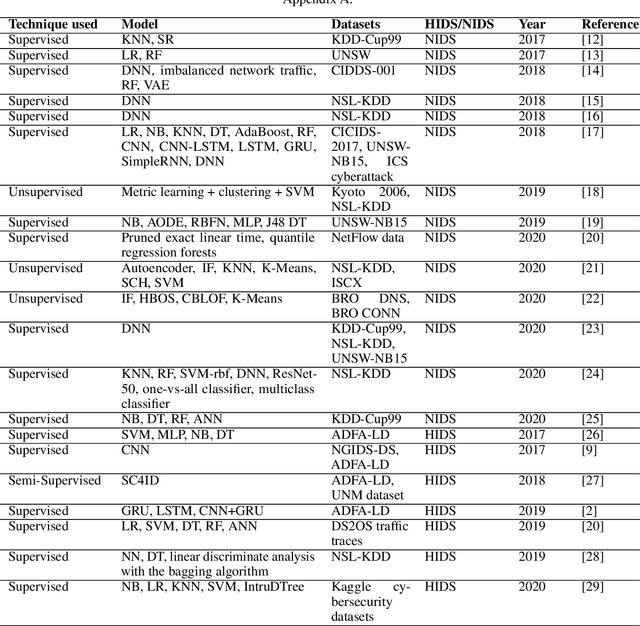
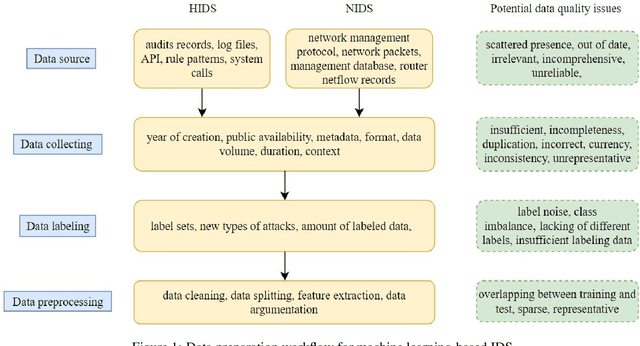
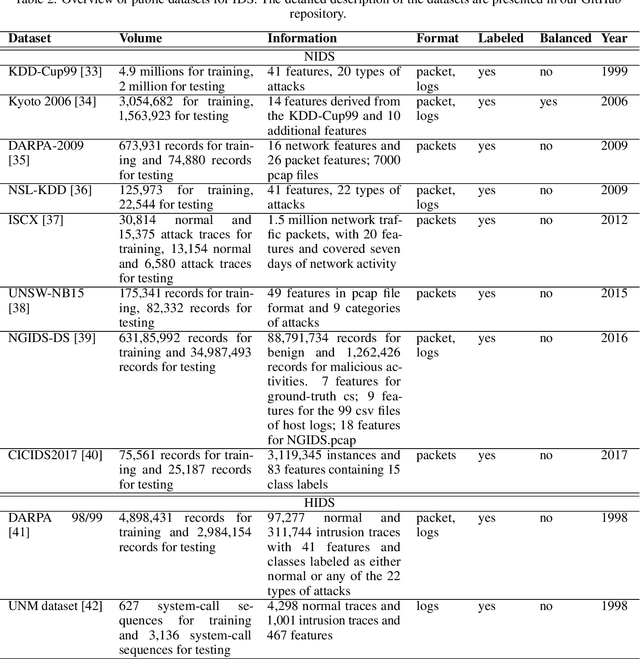
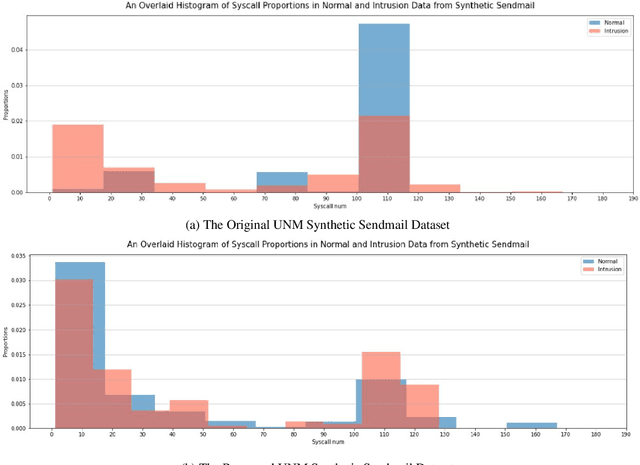
Intrusion detection is an essential task in the cyber threat environment. Machine learning and deep learning techniques have been applied for intrusion detection. However, most of the existing research focuses on the model work but ignores the fact that poor data quality has a direct impact on the performance of a machine learning system. More attention should be paid to the data work when building a machine learning-based intrusion detection system. This article first summarizes existing machine learning-based intrusion detection systems and the datasets used for building these systems. Then the data preparation workflow and quality requirements for intrusion detection are discussed. To figure out how data and models affect machine learning performance, we conducted experiments on 11 HIDS datasets using seven machine learning models and three deep learning models. The experimental results show that BERT and GPT were the best algorithms for HIDS on all of the datasets. However, the performance on different datasets varies, indicating the differences between the data quality of these datasets. We then evaluate the data quality of the 11 datasets based on quality dimensions proposed in this paper to determine the best characteristics that a HIDS dataset should possess in order to yield the best possible result. This research initiates a data quality perspective for researchers and practitioners to improve the performance of machine learning-based intrusion detection.
Fine-tuning Pre-trained Contextual Embeddings for Citation Content Analysis in Scholarly Publication
Sep 12, 2020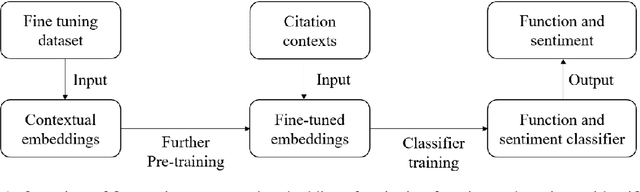
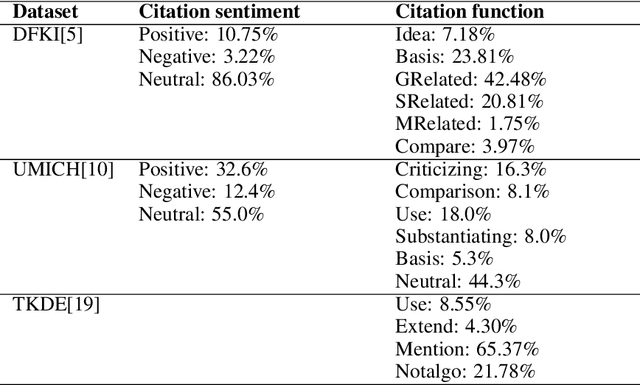
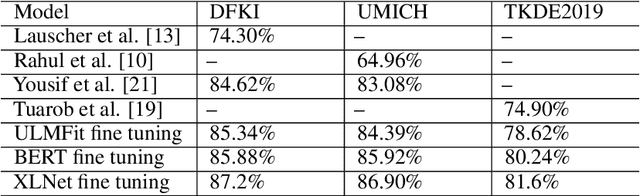
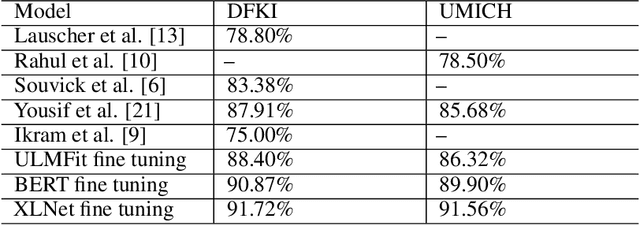
Citation function and citation sentiment are two essential aspects of citation content analysis (CCA), which are useful for influence analysis, the recommendation of scientific publications. However, existing studies are mostly traditional machine learning methods, although deep learning techniques have also been explored, the improvement of the performance seems not significant due to insufficient training data, which brings difficulties to applications. In this paper, we propose to fine-tune pre-trained contextual embeddings ULMFiT, BERT, and XLNet for the task. Experiments on three public datasets show that our strategy outperforms all the baselines in terms of the F1 score. For citation function identification, the XLNet model achieves 87.2%, 86.90%, and 81.6% on DFKI, UMICH, and TKDE2019 datasets respectively, while it achieves 91.72% and 91.56% on DFKI and UMICH in term of citation sentiment identification. Our method can be used to enhance the influence analysis of scholars and scholarly publications.