 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREM: A Scalable Reinforced Multi-Expert Framework for Multiplex Influence Maximization
Jan 01, 2025



In social online platforms, identifying influential seed users to maximize influence spread is a crucial as it can greatly diminish the cost and efforts required for information dissemination. While effective, traditional methods for Multiplex Influence Maximization (MIM) have reached their performance limits, prompting the emergence of learning-based approaches. These novel methods aim for better generalization and scalability for more sizable graphs but face significant challenges, such as (1) inability to handle unknown diffusion patterns and (2) reliance on high-quality training samples. To address these issues, we propose the Reinforced Expert Maximization framework (REM). REM leverages a Propagation Mixture of Experts technique to encode dynamic propagation of large multiplex networks effectively in order to generate enhanced influence propagation. Noticeably, REM treats a generative model as a policy to autonomously generate different seed sets and learn how to improve them from a Reinforcement Learning perspective. Extensive experiments on several real-world datasets demonstrate that REM surpasses state-of-the-art methods in terms of influence spread, scalability, and inference time in influence maximization tasks.
Deepfake Audio Detection Using Spectrogram-based Feature and Ensemble of Deep Learning Models
Jul 01, 2024



In this paper, we propose a deep learning based system for the task of deepfake audio detection. In particular, the draw input audio is first transformed into various spectrograms using three transformation methods of Short-time Fourier Transform (STFT), Constant-Q Transform (CQT), Wavelet Transform (WT) combined with different auditory-based filters of Mel, Gammatone, linear filters (LF), and discrete cosine transform (DCT). Given the spectrograms, we evaluate a wide range of classification models based on three deep learning approaches. The first approach is to train directly the spectrograms using our proposed baseline models of CNN-based model (CNN-baseline), RNN-based model (RNN-baseline), C-RNN model (C-RNN baseline). Meanwhile, the second approach is transfer learning from computer vision models such as ResNet-18, MobileNet-V3, EfficientNet-B0, DenseNet-121, SuffleNet-V2, Swint, Convnext-Tiny, GoogLeNet, MNASsnet, RegNet. In the third approach, we leverage the state-of-the-art audio pre-trained models of Whisper, Seamless, Speechbrain, and Pyannote to extract audio embeddings from the input spectrograms. Then, the audio embeddings are explored by a Multilayer perceptron (MLP) model to detect the fake or real audio samples. Finally, high-performance deep learning models from these approaches are fused to achieve the best performance. We evaluated our proposed models on ASVspoof 2019 benchmark dataset. Our best ensemble model achieved an Equal Error Rate (EER) of 0.03, which is highly competitive to top-performing systems in the ASVspoofing 2019 challenge. Experimental results also highlight the potential of selective spectrograms and deep learning approaches to enhance the task of audio deepfake detection.
A Comparative Study of Quality Evaluation Methods for Text Summarization
Jun 30, 2024
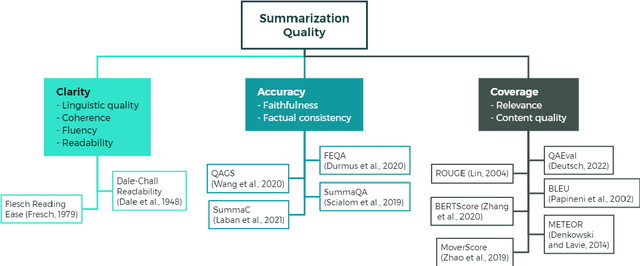


Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
ReINTEL: A Multimodal Data Challenge for Responsible Information Identification on Social Network Sites
Dec 16, 2020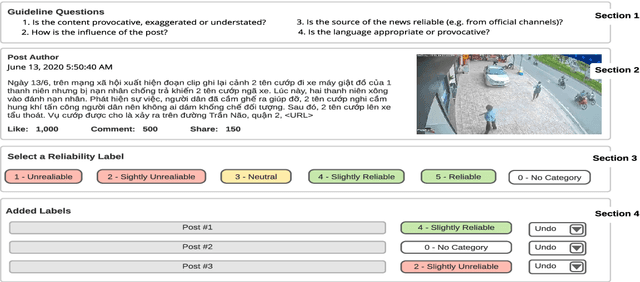
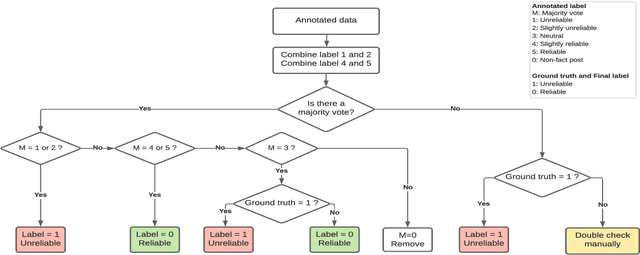

This paper reports on the ReINTEL Shared Task for Responsible Information Identification on social network sites, which is hosted at the seventh annual workshop on Vietnamese Language and Speech Processing (VLSP 2020). Given a piece of news with respective textual, visual content and metadata, participants are required to classify whether the news is `reliable' or `unreliable'. In order to generate a fair benchmark, we introduce a novel human-annotated dataset of over 10,000 news collected from a social network in Vietnam. All models will be evaluated in terms of AUC-ROC score, a typical evaluation metric for classification. The competition was run on the Codalab platform. Within two months, the challenge has attracted over 60 participants and recorded nearly 1,000 submission entries.
Fine-tuning Pre-trained Contextual Embeddings for Citation Content Analysis in Scholarly Publication
Sep 12, 2020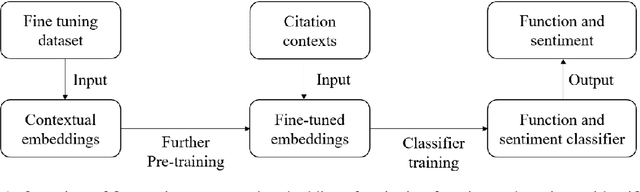
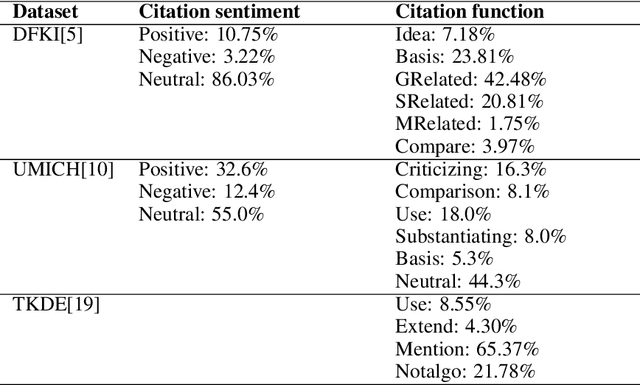
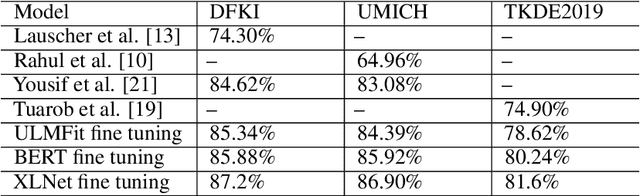
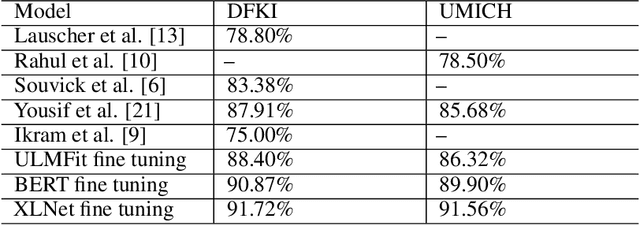
Citation function and citation sentiment are two essential aspects of citation content analysis (CCA), which are useful for influence analysis, the recommendation of scientific publications. However, existing studies are mostly traditional machine learning methods, although deep learning techniques have also been explored, the improvement of the performance seems not significant due to insufficient training data, which brings difficulties to applications. In this paper, we propose to fine-tune pre-trained contextual embeddings ULMFiT, BERT, and XLNet for the task. Experiments on three public datasets show that our strategy outperforms all the baselines in terms of the F1 score. For citation function identification, the XLNet model achieves 87.2%, 86.90%, and 81.6% on DFKI, UMICH, and TKDE2019 datasets respectively, while it achieves 91.72% and 91.56% on DFKI and UMICH in term of citation sentiment identification. Our method can be used to enhance the influence analysis of scholars and scholarly publications.
SimpleBooks: Long-term dependency book dataset with simplified English vocabulary for word-level language modeling
Nov 27, 2019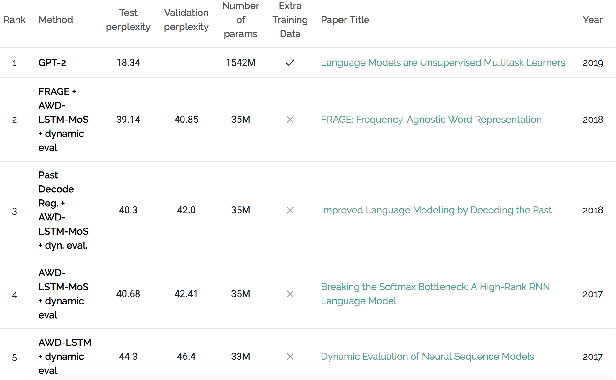
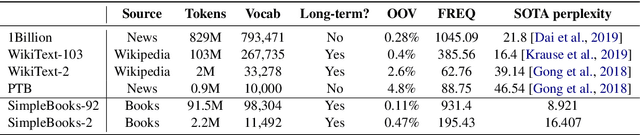
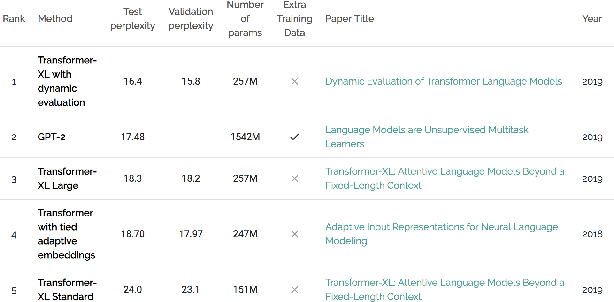
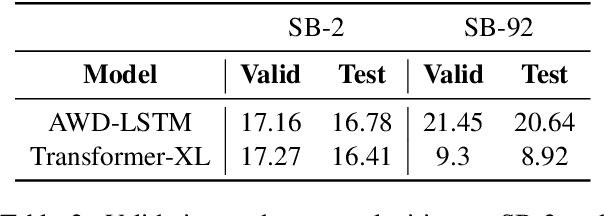
With language modeling becoming the popular base task for unsupervised representation learning in Natural Language Processing, it is important to come up with new architectures and techniques for faster and better training of language models. However, due to a peculiarity of languages -- the larger the dataset, the higher the average number of times a word appears in that dataset -- datasets of different sizes have very different properties. Architectures performing well on small datasets might not perform well on larger ones. For example, LSTM models perform well on WikiText-2 but poorly on WikiText-103, while Transformer models perform well on WikiText-103 but not on WikiText-2. For setups like architectural search, this is a challenge since it is prohibitively costly to run a search on the full dataset but it is not indicative to experiment on smaller ones. In this paper, we introduce SimpleBooks, a small dataset with the average word frequency as high as that of much larger ones. Created from 1,573 Gutenberg books with the highest ratio of word-level book length to vocabulary size, SimpleBooks contains 92M word-level tokens, on par with WikiText-103 (103M tokens), but has the vocabulary of 98K, a third of WikiText-103's. SimpleBooks can be downloaded from https://dldata-public.s3.us-east-2.amazonaws.com/simplebooks.zip.
NeMo: a toolkit for building AI applications using Neural Modules
Sep 14, 2019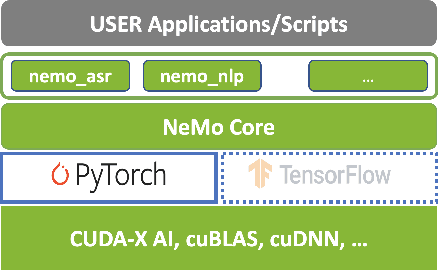

NeMo (Neural Modules) is a Python framework-agnostic toolkit for creating AI applications through re-usability, abstraction, and composition. NeMo is built around neural modules, conceptual blocks of neural networks that take typed inputs and produce typed outputs. Such modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. NeMo makes it easy to combine and re-use these building blocks while providing a level of semantic correctness checking via its neural type system. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition and natural language processing. Furthermore, NeMo provides built-in support for distributed training and mixed precision on latest NVIDIA GPUs. NeMo is open-source https://github.com/NVIDIA/NeMo
Stochastic Gradient Methods with Layer-wise Adaptive Moments for Training of Deep Networks
May 27, 2019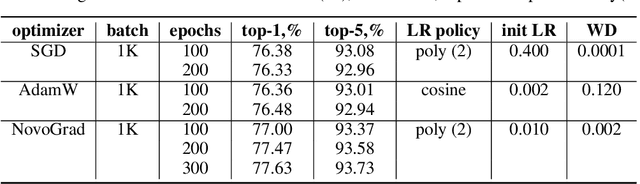
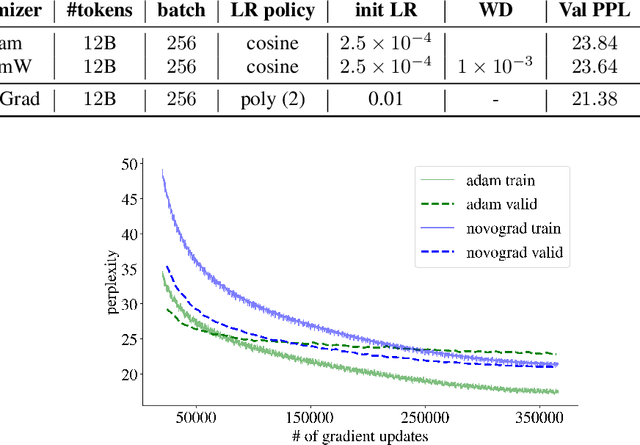
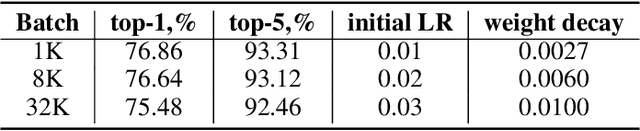
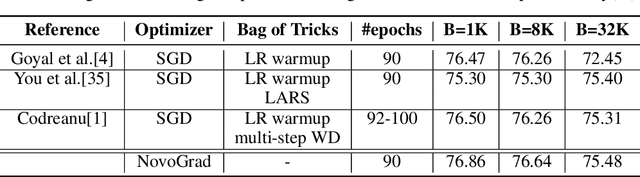
We propose NovoGrad, a first-order stochastic gradient method with layer-wise gradient normalization via second moment estimators and with decoupled weight decay for a better regularization. The method requires half as much memory as Adam/AdamW. We evaluated NovoGrad on the diverse set of problems, including image classification, speech recognition, neural machine translation and language modeling. On these problems, NovoGrad performed equal to or better than SGD and Adam/AdamW. Empirically we show that NovoGrad (1) is very robust during the initial training phase and does not require learning rate warm-up, (2) works well with the same learning rate policy for different problems, and (3) generally performs better than other optimizers for very large batch sizes
Jasper: An End-to-End Convolutional Neural Acoustic Model
Apr 05, 2019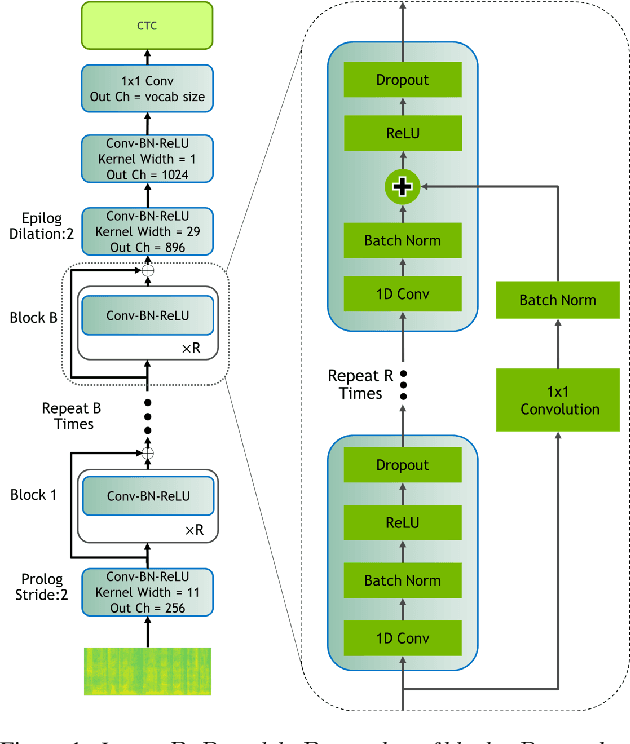
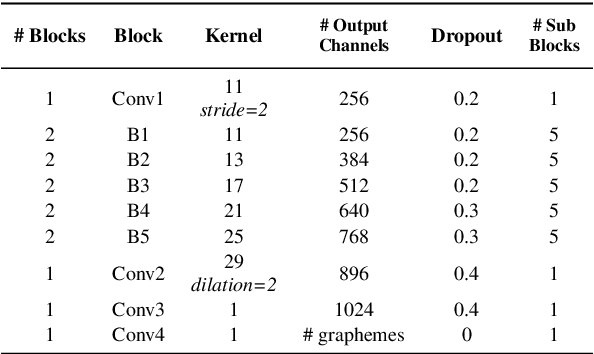
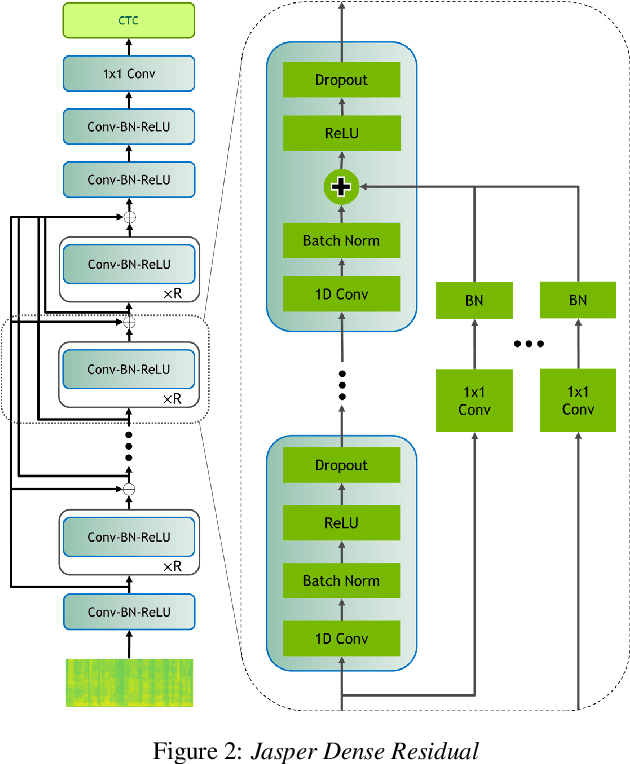
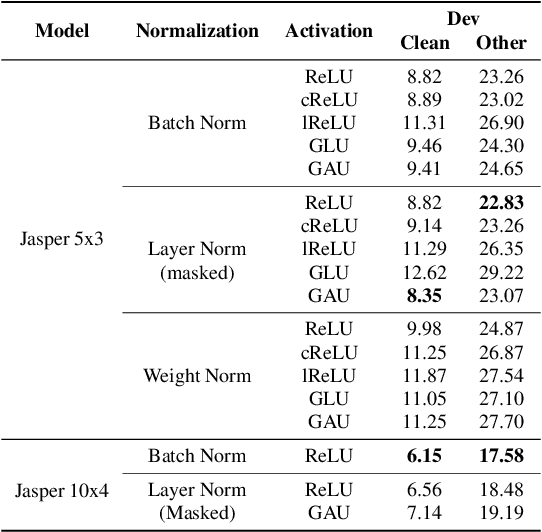
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.