 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixer-TTS: non-autoregressive, fast and compact text-to-speech model conditioned on language model embeddings
Oct 22, 2021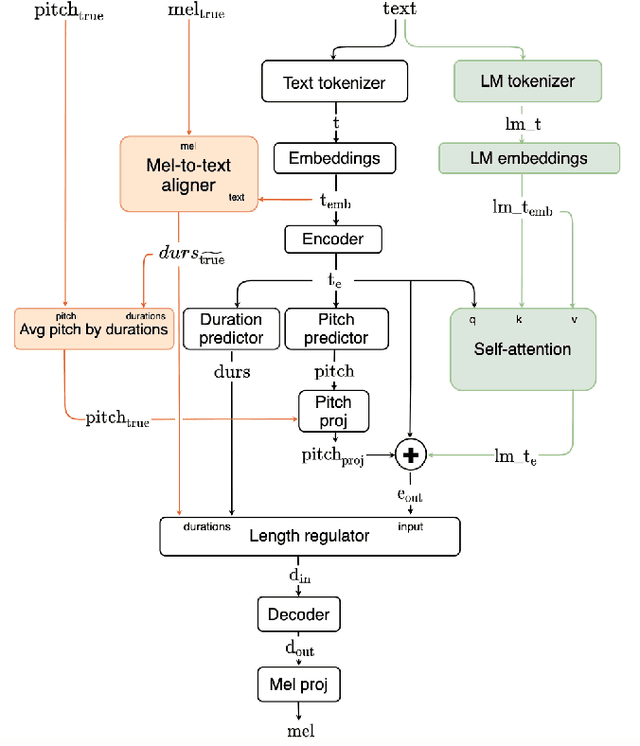


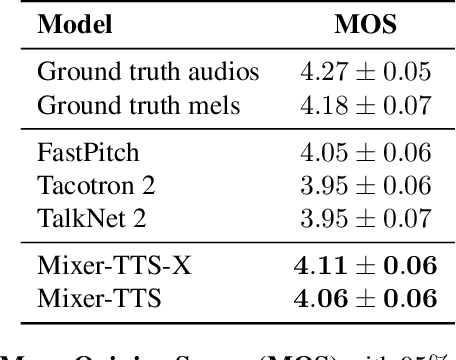
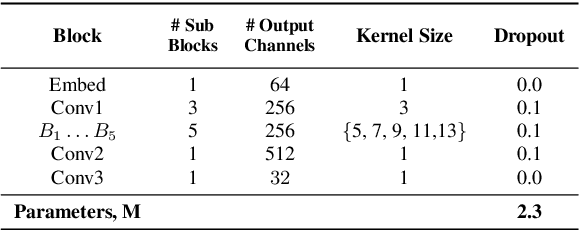
This paper describes Mixer-TTS, a non-autoregressive model for mel-spectrogram generation. The model is based on the MLP-Mixer architecture adapted for speech synthesis. The basic Mixer-TTS contains pitch and duration predictors, with the latter being trained with an unsupervised TTS alignment framework. Alongside the basic model, we propose the extended version which additionally uses token embeddings from a pre-trained language model. Basic Mixer-TTS and its extended version achieve a mean opinion score (MOS) of 4.05 and 4.11, respectively, compared to a MOS of 4.27 of original LJSpeech samples. Both versions have a small number of parameters and enable much faster speech synthesis compared to the models with similar quality.
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
Apr 19, 2021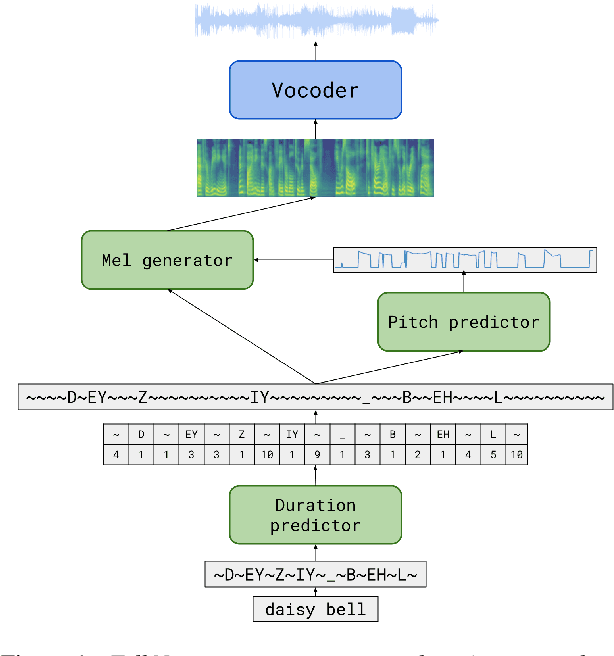

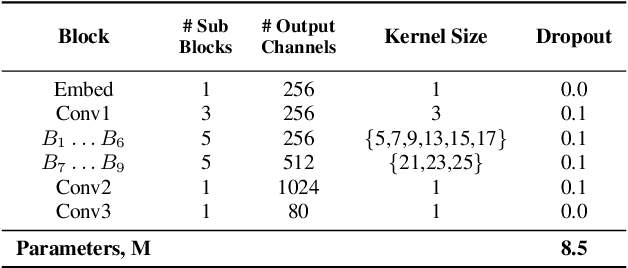
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.
NeMo: a toolkit for building AI applications using Neural Modules
Sep 14, 2019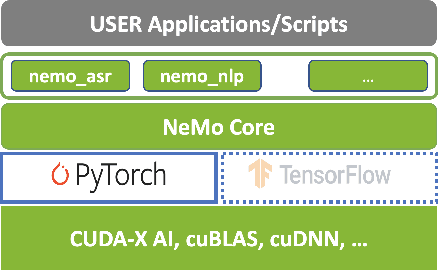

NeMo (Neural Modules) is a Python framework-agnostic toolkit for creating AI applications through re-usability, abstraction, and composition. NeMo is built around neural modules, conceptual blocks of neural networks that take typed inputs and produce typed outputs. Such modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. NeMo makes it easy to combine and re-use these building blocks while providing a level of semantic correctness checking via its neural type system. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition and natural language processing. Furthermore, NeMo provides built-in support for distributed training and mixed precision on latest NVIDIA GPUs. NeMo is open-source https://github.com/NVIDIA/NeMo