 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization
Aug 18, 2023The task of lip synchronization (lip-sync) seeks to match the lips of human faces with different audio. It has various applications in the film industry as well as for creating virtual avatars and for video conferencing. This is a challenging problem as one needs to simultaneously introduce detailed, realistic lip movements while preserving the identity, pose, emotions, and image quality. Many of the previous methods trying to solve this problem suffer from image quality degradation due to a lack of complete contextual information. In this paper, we present Diff2Lip, an audio-conditioned diffusion-based model which is able to do lip synchronization in-the-wild while preserving these qualities. We train our model on Voxceleb2, a video dataset containing in-the-wild talking face videos. Extensive studies show that our method outperforms popular methods like Wav2Lip and PC-AVS in Fr\'echet inception distance (FID) metric and Mean Opinion Scores (MOS) of the users. We show results on both reconstruction (same audio-video inputs) as well as cross (different audio-video inputs) settings on Voxceleb2 and LRW datasets. Video results and code can be accessed from our project page ( https://soumik-kanad.github.io/diff2lip ).
Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems
Dec 16, 2021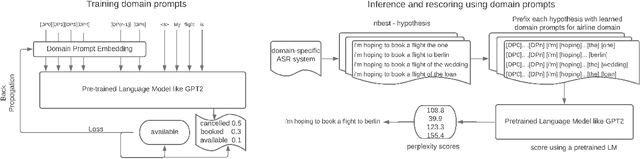

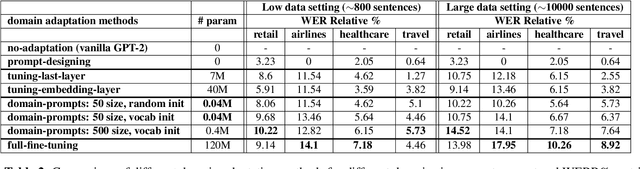
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we introduce domain-prompts, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve 7-14% WER improvement over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. With ablations on prompt-sizes, dataset sizes, initializations and domains, we provide evidence for the benefits of using domain-prompts in ASR systems.
Prompt-tuning in ASR systems for efficient domain-adaptation
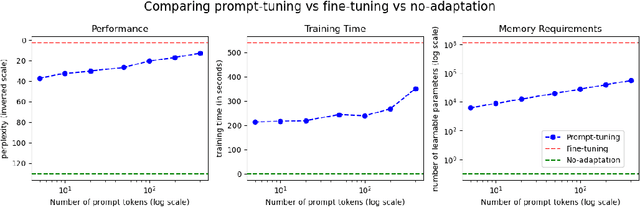
Oct 22, 2021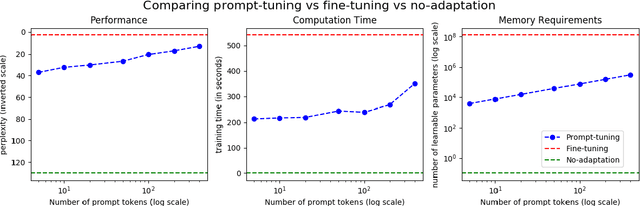
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we overcome the problem using prompt-tuning, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve much better perplexity scores over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. We replicate our findings in perplexity numbers to Word Error Rate in a domain-specific ASR system for one such domain.
Towards Continual Entity Learning in Language Models for Conversational Agents
Jul 30, 2021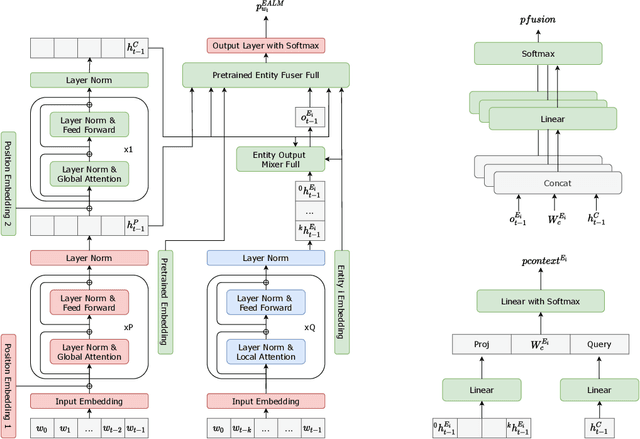
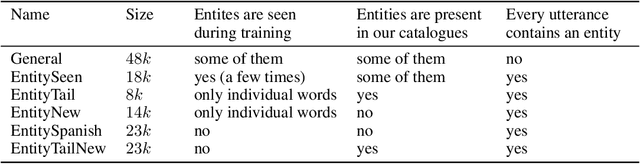

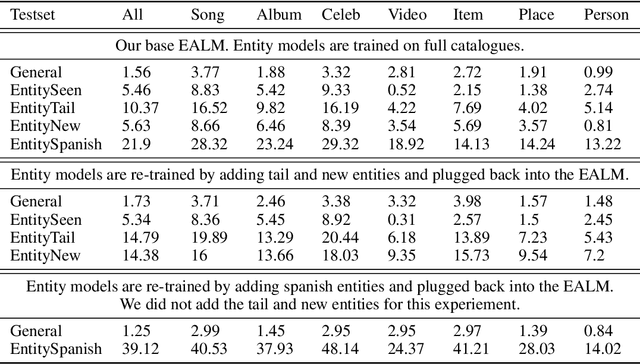
Neural language models (LM) trained on diverse corpora are known to work well on previously seen entities, however, updating these models with dynamically changing entities such as place names, song titles and shopping items requires re-training from scratch and collecting full sentences containing these entities. We aim to address this issue, by introducing entity-aware language models (EALM), where we integrate entity models trained on catalogues of entities into the pre-trained LMs. Our combined language model adaptively adds information from the entity models into the pre-trained LM depending on the sentence context. Our entity models can be updated independently of the pre-trained LM, enabling us to influence the distribution of entities output by the final LM, without any further training of the pre-trained LM. We show significant perplexity improvements on task-oriented dialogue datasets, especially on long-tailed utterances, with an ability to continually adapt to new entities (to an extent).
Jasper: An End-to-End Convolutional Neural Acoustic Model
Apr 05, 2019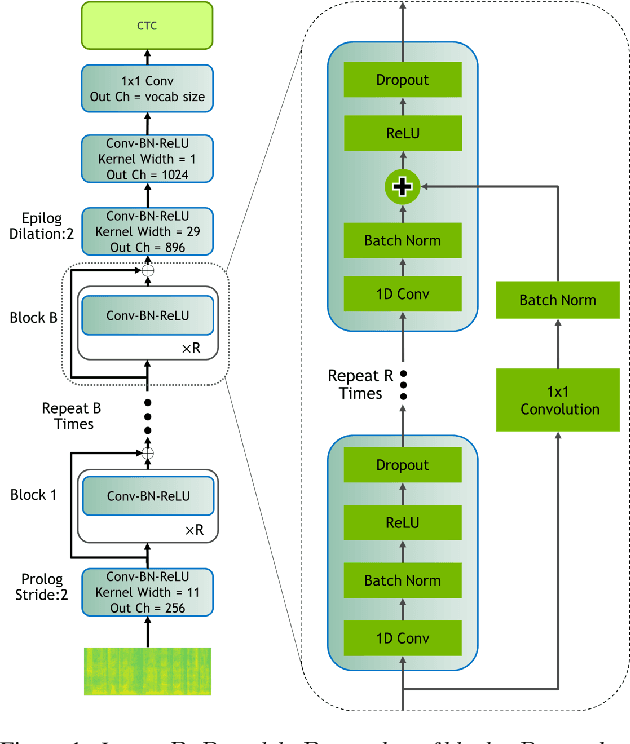
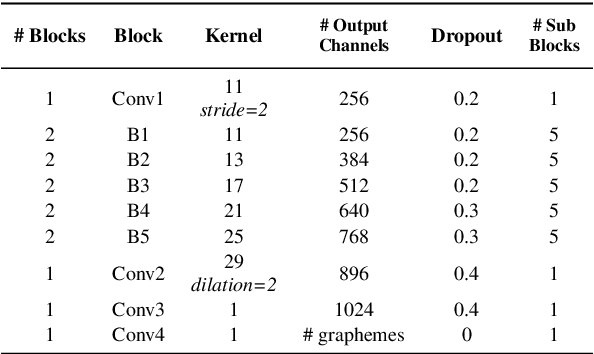
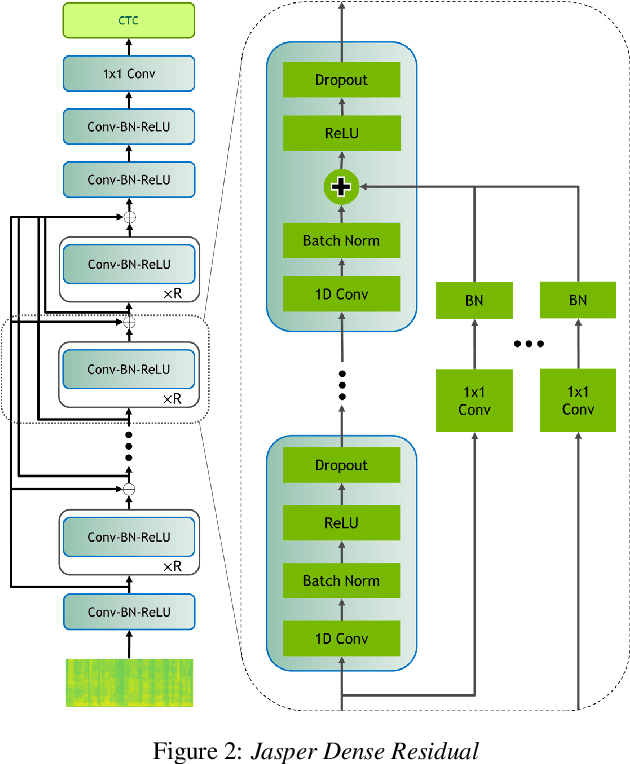
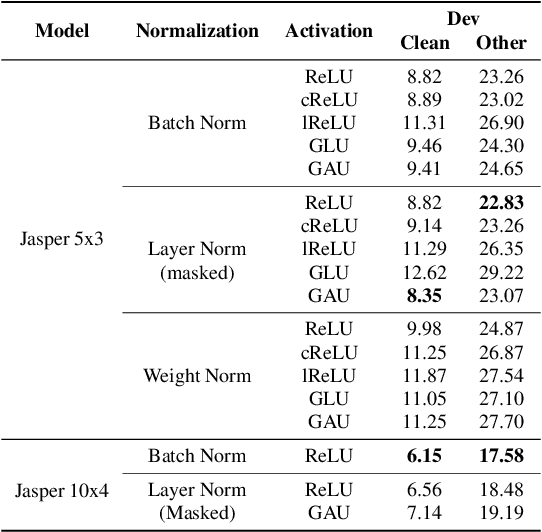
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.