 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeMo: a toolkit for building AI applications using Neural Modules
Sep 14, 2019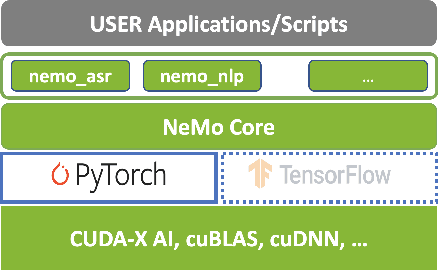

NeMo (Neural Modules) is a Python framework-agnostic toolkit for creating AI applications through re-usability, abstraction, and composition. NeMo is built around neural modules, conceptual blocks of neural networks that take typed inputs and produce typed outputs. Such modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations. NeMo makes it easy to combine and re-use these building blocks while providing a level of semantic correctness checking via its neural type system. The toolkit comes with extendable collections of pre-built modules for automatic speech recognition and natural language processing. Furthermore, NeMo provides built-in support for distributed training and mixed precision on latest NVIDIA GPUs. NeMo is open-source https://github.com/NVIDIA/NeMo
Stochastic Gradient Methods with Layer-wise Adaptive Moments for Training of Deep Networks
May 27, 2019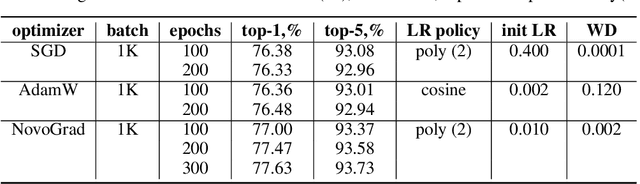
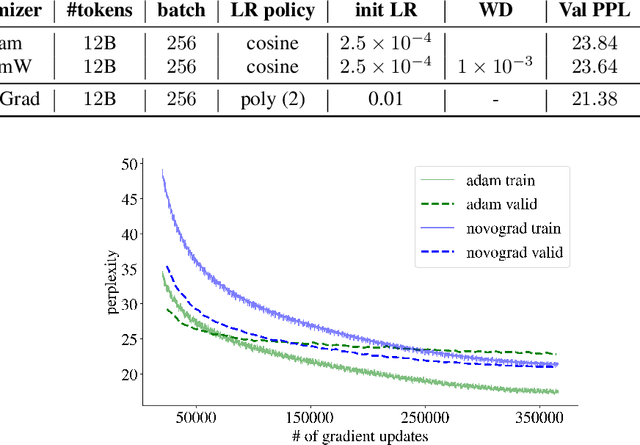
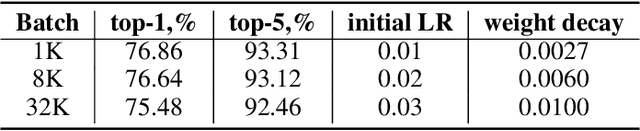
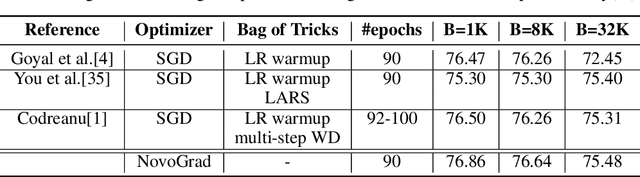
We propose NovoGrad, a first-order stochastic gradient method with layer-wise gradient normalization via second moment estimators and with decoupled weight decay for a better regularization. The method requires half as much memory as Adam/AdamW. We evaluated NovoGrad on the diverse set of problems, including image classification, speech recognition, neural machine translation and language modeling. On these problems, NovoGrad performed equal to or better than SGD and Adam/AdamW. Empirically we show that NovoGrad (1) is very robust during the initial training phase and does not require learning rate warm-up, (2) works well with the same learning rate policy for different problems, and (3) generally performs better than other optimizers for very large batch sizes
Jasper: An End-to-End Convolutional Neural Acoustic Model
Apr 05, 2019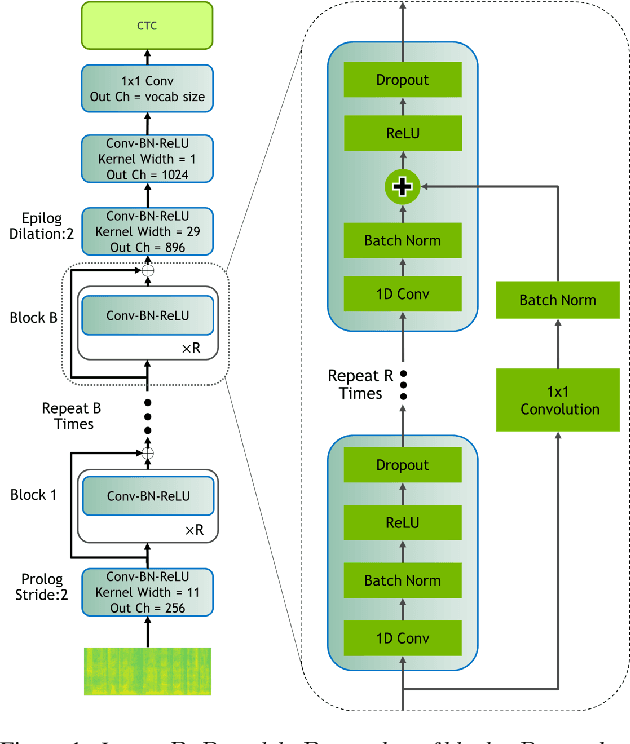
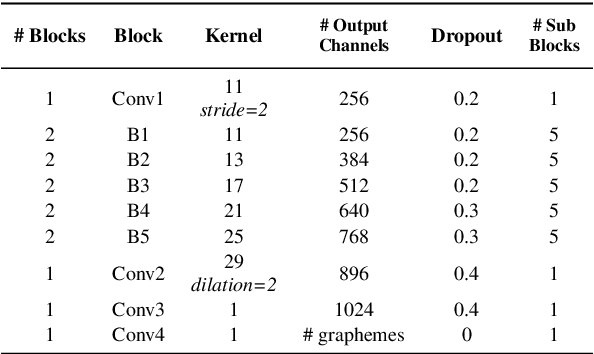
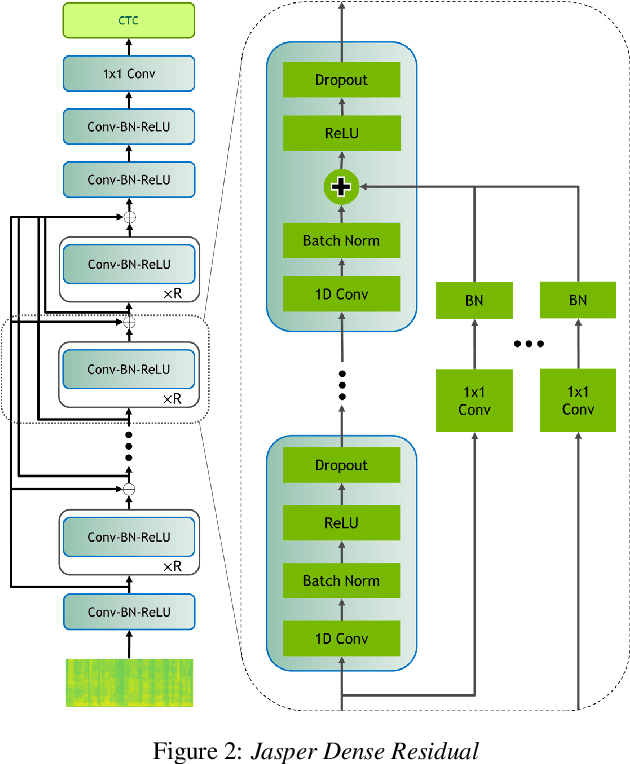
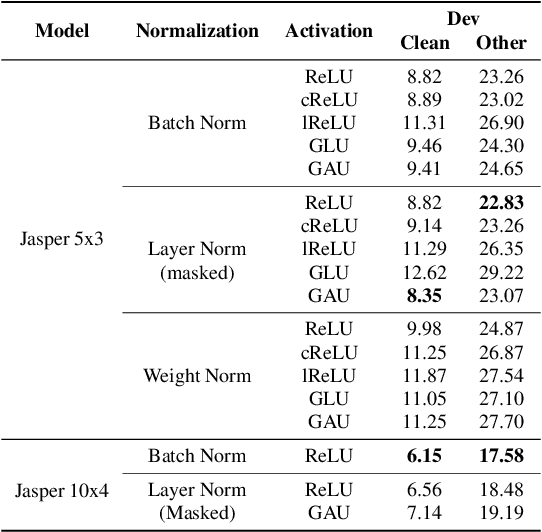
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.