 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-tuning in ASR systems for efficient domain-adaptation
Paper and Code
Oct 22, 2021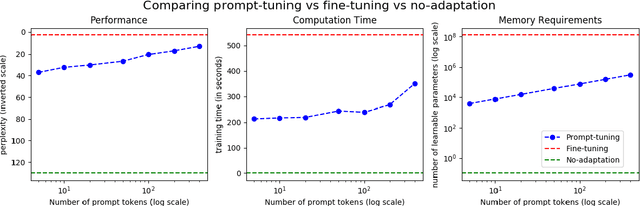
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we overcome the problem using prompt-tuning, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve much better perplexity scores over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. We replicate our findings in perplexity numbers to Word Error Rate in a domain-specific ASR system for one such domain.