 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Lumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Now It Sounds Like You: Learning Personalized Vocabulary On Device
May 05, 2023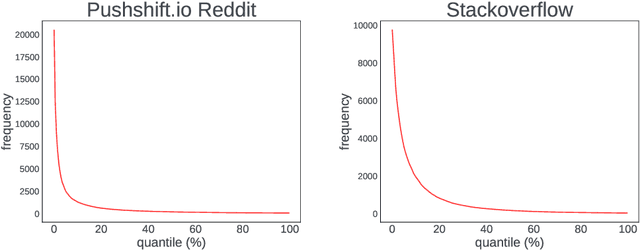

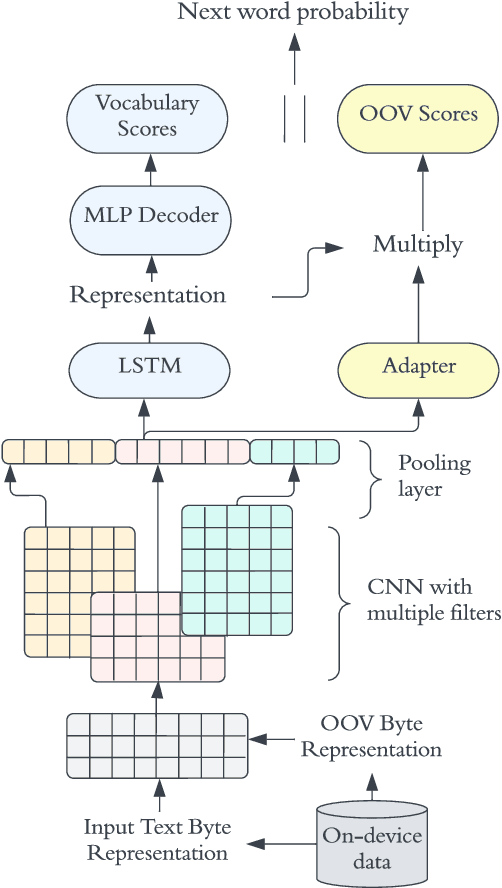

In recent years, Federated Learning (FL) has shown significant advancements in its ability to perform various natural language processing (NLP) tasks. This work focuses on applying personalized FL for on-device language modeling. Due to limitations of memory and latency, these models cannot support the complexity of sub-word tokenization or beam search decoding, resulting in the decision to deploy a closed-vocabulary language model. However, closed-vocabulary models are unable to handle out-of-vocabulary (OOV) words belonging to specific users. To address this issue, We propose a novel technique called "OOV expansion" that improves OOV coverage and increases model accuracy while minimizing the impact on memory and latency. This method introduces a personalized "OOV adapter" that effectively transfers knowledge from a central model and learns word embedding for personalized vocabulary. OOV expansion significantly outperforms standard FL personalization methods on a set of common FL benchmarks.
Green Federated Learning
Mar 26, 2023



The rapid progress of AI is fueled by increasingly large and computationally intensive machine learning models and datasets. As a consequence, the amount of compute used in training state-of-the-art models is exponentially increasing (doubling every 10 months between 2015 and 2022), resulting in a large carbon footprint. Federated Learning (FL) - a collaborative machine learning technique for training a centralized model using data of decentralized entities - can also be resource-intensive and have a significant carbon footprint, particularly when deployed at scale. Unlike centralized AI that can reliably tap into renewables at strategically placed data centers, cross-device FL may leverage as many as hundreds of millions of globally distributed end-user devices with diverse energy sources. Green AI is a novel and important research area where carbon footprint is regarded as an evaluation criterion for AI, alongside accuracy, convergence speed, and other metrics. In this paper, we propose the concept of Green FL, which involves optimizing FL parameters and making design choices to minimize carbon emissions consistent with competitive performance and training time. The contributions of this work are two-fold. First, we adopt a data-driven approach to quantify the carbon emissions of FL by directly measuring real-world at-scale FL tasks running on millions of phones. Second, we present challenges, guidelines, and lessons learned from studying the trade-off between energy efficiency, performance, and time-to-train in a production FL system. Our findings offer valuable insights into how FL can reduce its carbon footprint, and they provide a foundation for future research in the area of Green AI.
Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems
Dec 16, 2021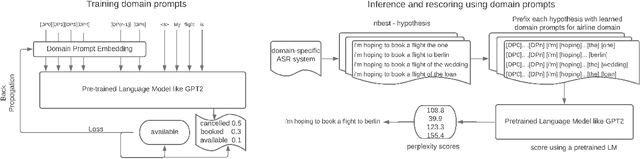

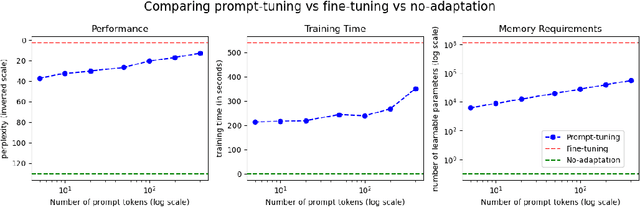
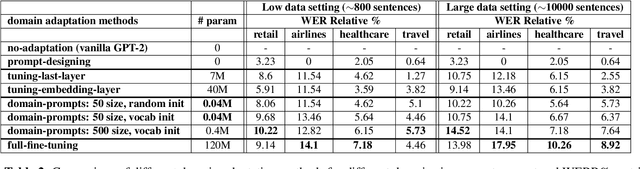
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we introduce domain-prompts, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve 7-14% WER improvement over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. With ablations on prompt-sizes, dataset sizes, initializations and domains, we provide evidence for the benefits of using domain-prompts in ASR systems.
Prompt-tuning in ASR systems for efficient domain-adaptation
Oct 22, 2021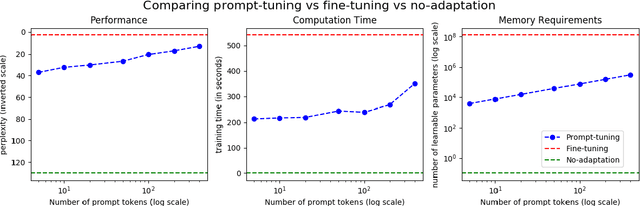
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we overcome the problem using prompt-tuning, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve much better perplexity scores over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. We replicate our findings in perplexity numbers to Word Error Rate in a domain-specific ASR system for one such domain.
Remember the context! ASR slot error correction through memorization
Sep 18, 2021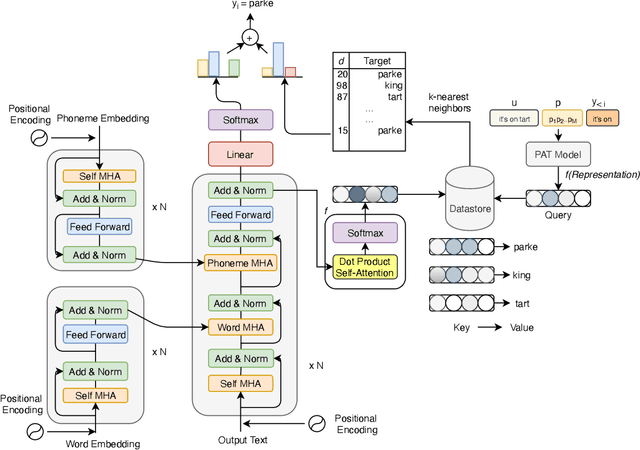
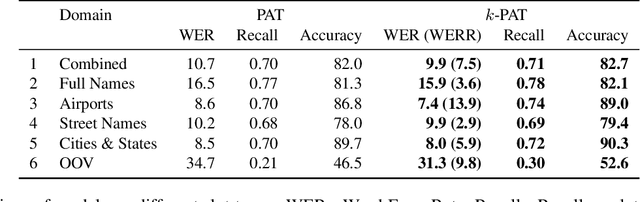
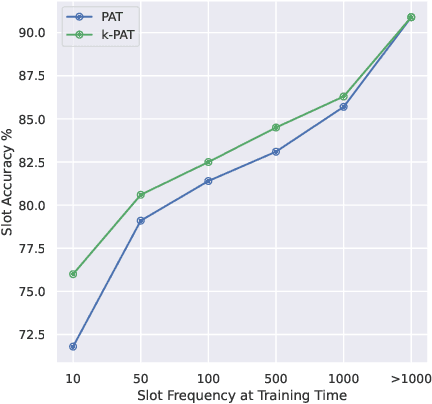
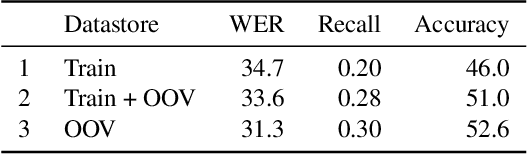
Accurate recognition of slot values such as domain specific words or named entities by automatic speech recognition (ASR) systems forms the core of the Goal-oriented Dialogue Systems. Although it is a critical step with direct impact on downstream tasks such as language understanding, many domain agnostic ASR systems tend to perform poorly on domain specific or long tail words. They are often supplemented with slot error correcting systems but it is often hard for any neural model to directly output such rare entity words. To address this problem, we propose k-nearest neighbor (k-NN) search that outputs domain-specific entities from an explicit datastore. We improve error correction rate by conveniently augmenting a pretrained joint phoneme and text based transformer sequence to sequence model with k-NN search during inference. We evaluate our proposed approach on five different domains containing long tail slot entities such as full names, airports, street names, cities, states. Our best performing error correction model shows a relative improvement of 7.4% in word error rate (WER) on rare word entities over the baseline and also achieves a relative WER improvement of 9.8% on an out of vocabulary (OOV) test set.