 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIMPSE : Real-Time Text Recognition and Contextual Understanding for VQA in Wearables
Feb 13, 2026Video Large Language Models (Video LLMs) have shown remarkable progress in understanding and reasoning about visual content, particularly in tasks involving text recognition and text-based visual question answering (Text VQA). However, deploying Text VQA on wearable devices faces a fundamental tension: text recognition requires high-resolution video, but streaming high-quality video drains battery and causes thermal throttling. Moreover, existing models struggle to maintain coherent temporal context when processing text across multiple frames in real-time streams. We observe that text recognition and visual reasoning have asymmetric resolution requirements - OCR needs fine detail while scene understanding tolerates coarse features. We exploit this asymmetry with a hybrid architecture that performs selective high-resolution OCR on-device while streaming low-resolution video for visual context. On a benchmark of text-based VQA samples across five task categories, our system achieves 72% accuracy at 0.49x the power consumption of full-resolution streaming, enabling sustained VQA sessions on resource-constrained wearables without sacrificing text understanding quality.
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Lumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
Now It Sounds Like You: Learning Personalized Vocabulary On Device
May 05, 2023

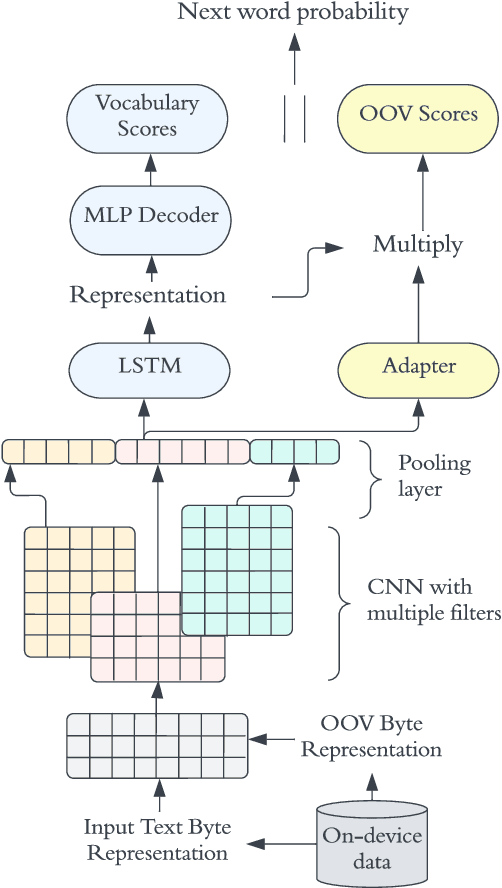

In recent years, Federated Learning (FL) has shown significant advancements in its ability to perform various natural language processing (NLP) tasks. This work focuses on applying personalized FL for on-device language modeling. Due to limitations of memory and latency, these models cannot support the complexity of sub-word tokenization or beam search decoding, resulting in the decision to deploy a closed-vocabulary language model. However, closed-vocabulary models are unable to handle out-of-vocabulary (OOV) words belonging to specific users. To address this issue, We propose a novel technique called "OOV expansion" that improves OOV coverage and increases model accuracy while minimizing the impact on memory and latency. This method introduces a personalized "OOV adapter" that effectively transfers knowledge from a central model and learns word embedding for personalized vocabulary. OOV expansion significantly outperforms standard FL personalization methods on a set of common FL benchmarks.
Omni-sparsity DNN: Fast Sparsity Optimization for On-Device Streaming E2E ASR via Supernet
Oct 15, 2021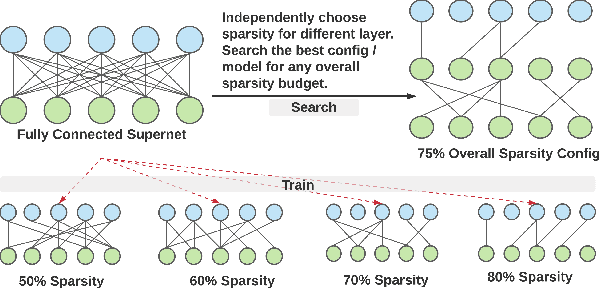
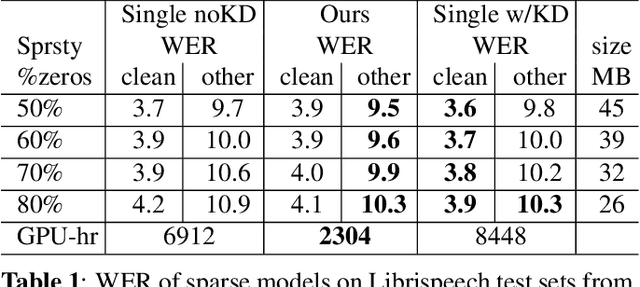
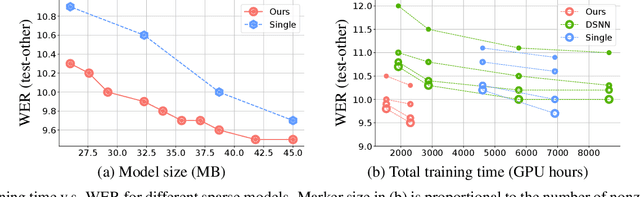
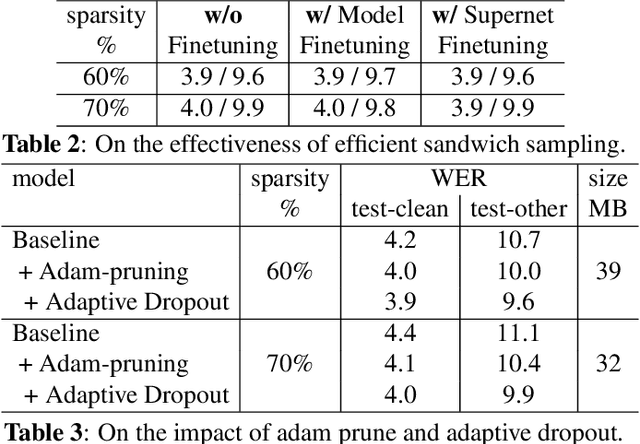
From wearables to powerful smart devices, modern automatic speech recognition (ASR) models run on a variety of edge devices with different computational budgets. To navigate the Pareto front of model accuracy vs model size, researchers are trapped in a dilemma of optimizing model accuracy by training and fine-tuning models for each individual edge device while keeping the training GPU-hours tractable. In this paper, we propose Omni-sparsity DNN, where a single neural network can be pruned to generate optimized model for a large range of model sizes. We develop training strategies for Omni-sparsity DNN that allows it to find models along the Pareto front of word-error-rate (WER) vs model size while keeping the training GPU-hours to no more than that of training one singular model. We demonstrate the Omni-sparsity DNN with streaming E2E ASR models. Our results show great saving on training time and resources with similar or better accuracy on LibriSpeech compared to individually pruned sparse models: 2%-6.6% better WER on Test-other.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021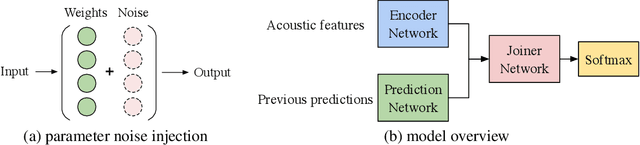
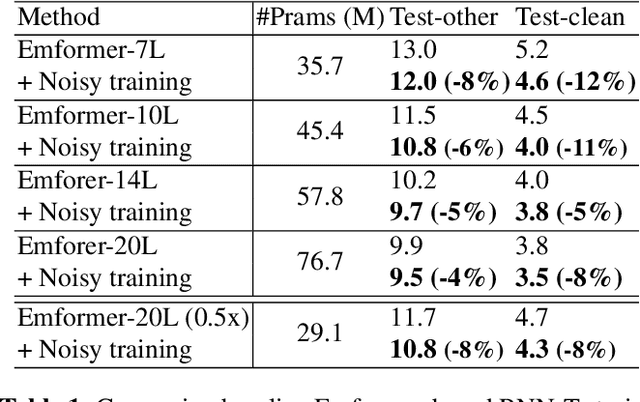
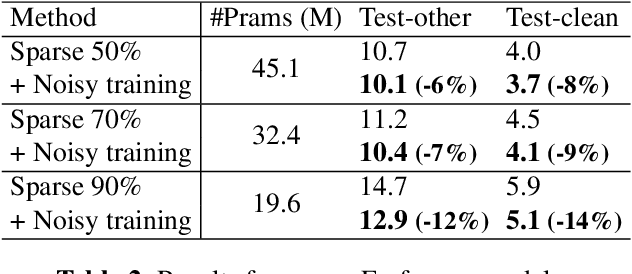
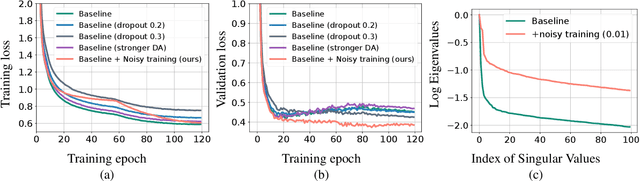
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021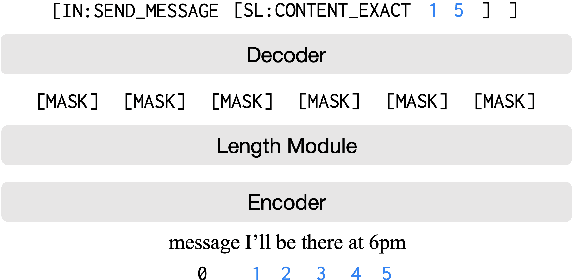

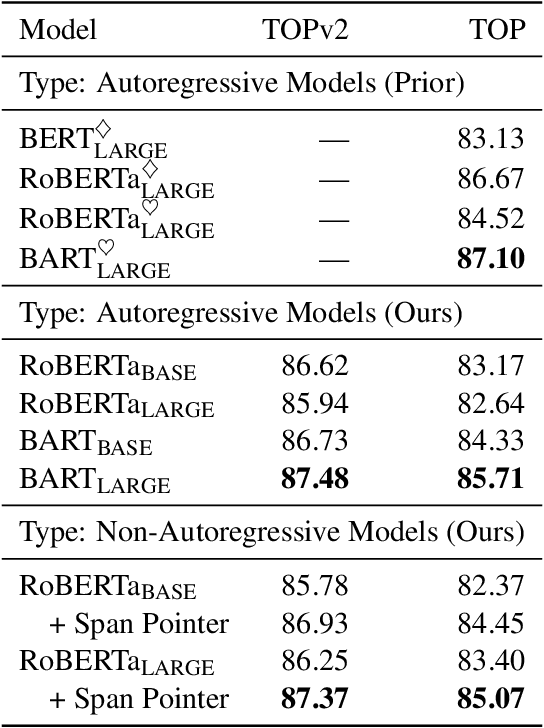
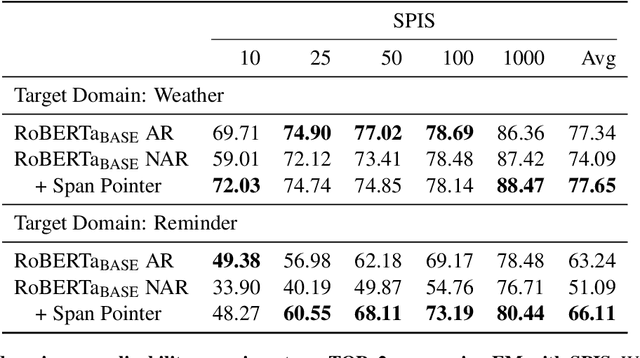
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.
F-CAD: A Framework to Explore Hardware Accelerators for Codec Avatar Decoding
Mar 08, 2021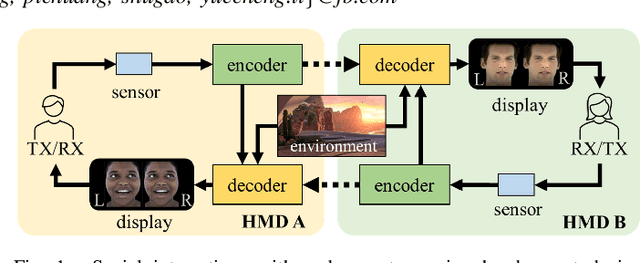
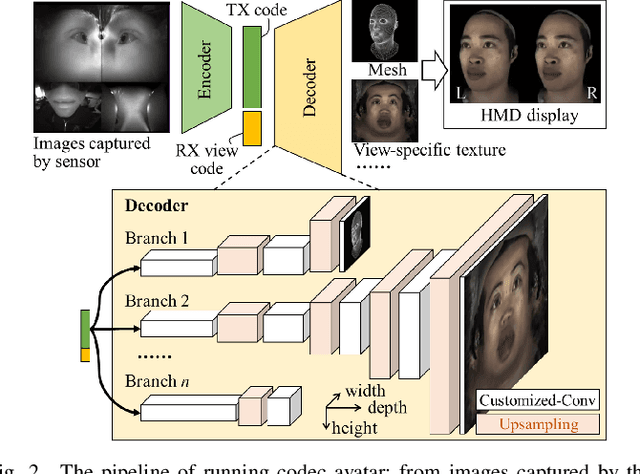
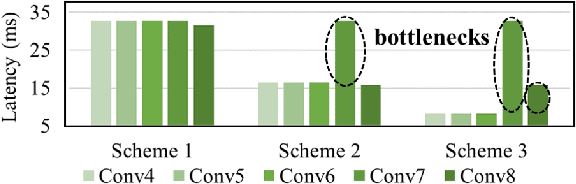
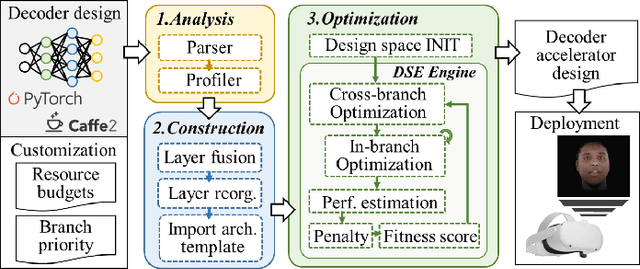
Creating virtual avatars with realistic rendering is one of the most essential and challenging tasks to provide highly immersive virtual reality (VR) experiences. It requires not only sophisticated deep neural network (DNN) based codec avatar decoders to ensure high visual quality and precise motion expression, but also efficient hardware accelerators to guarantee smooth real-time rendering using lightweight edge devices, like untethered VR headsets. Existing hardware accelerators, however, fail to deliver sufficient performance and efficiency targeting such decoders which consist of multi-branch DNNs and require demanding compute and memory resources. To address these problems, we propose an automation framework, called F-CAD (Facebook Codec avatar Accelerator Design), to explore and deliver optimized hardware accelerators for codec avatar decoding. Novel technologies include 1) a new accelerator architecture to efficiently handle multi-branch DNNs; 2) a multi-branch dynamic design space to enable fine-grained architecture configurations; and 3) an efficient architecture search for picking the optimized hardware design based on both application-specific demands and hardware resource constraints. To the best of our knowledge, F-CAD is the first automation tool that supports the whole design flow of hardware acceleration of codec avatar decoders, allowing joint optimization on decoder designs in popular machine learning frameworks and corresponding customized accelerator design with cycle-accurate evaluation. Results show that the accelerators generated by F-CAD can deliver up to 122.1 frames per second (FPS) and 91.6% hardware efficiency when running the latest codec avatar decoder. Compared to the state-of-the-art designs, F-CAD achieves 4.0X and 2.8X higher throughput, 62.5% and 21.2% higher efficiency than DNNBuilder and HybridDNN by targeting the same hardware device.
Improving Efficiency in Neural Network Accelerator Using Operands Hamming Distance optimization
Feb 13, 2020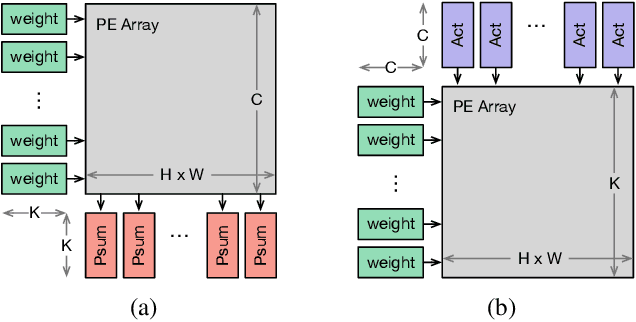

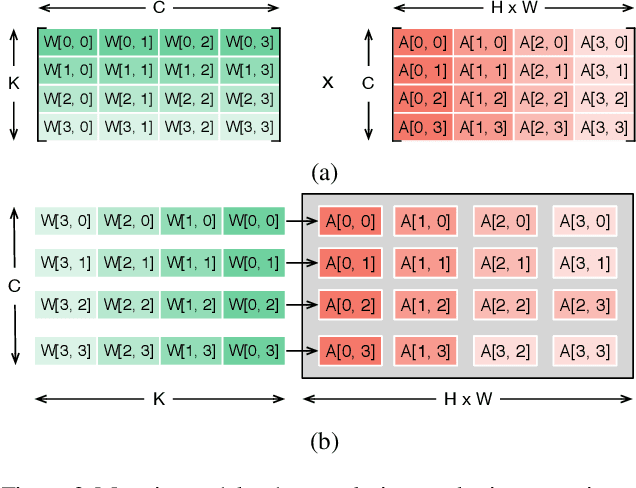
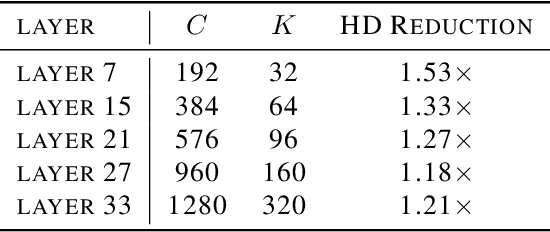
Neural network accelerator is a key enabler for the on-device AI inference, for which energy efficiency is an important metric. The data-path energy, including the computation energy and the data movement energy among the arithmetic units, claims a significant part of the total accelerator energy. By revisiting the basic physics of the arithmetic logic circuits, we show that the data-path energy is highly correlated with the bit flips when streaming the input operands into the arithmetic units, defined as the hamming distance of the input operand matrices. Based on the insight, we propose a post-training optimization algorithm and a hamming-distance-aware training algorithm to co-design and co-optimize the accelerator and the network synergistically. The experimental results based on post-layout simulation with MobileNetV2 demonstrate on average 2.85X data-path energy reduction and up to 8.51X data-path energy reduction for certain layers.