 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022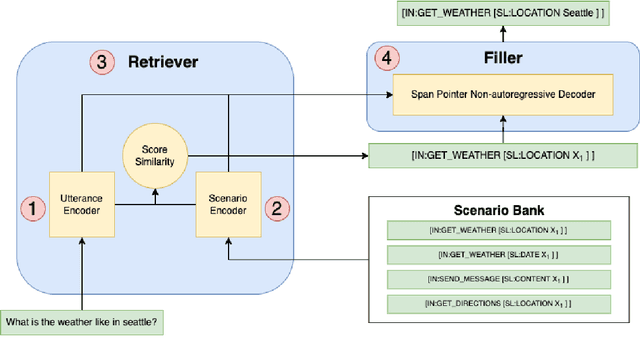
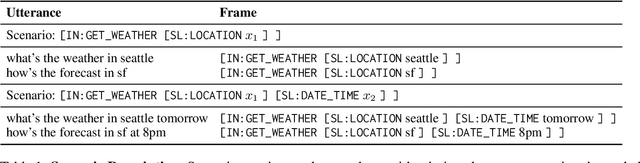


Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.
Assessing Data Efficiency in Task-Oriented Semantic Parsing
Jul 10, 2021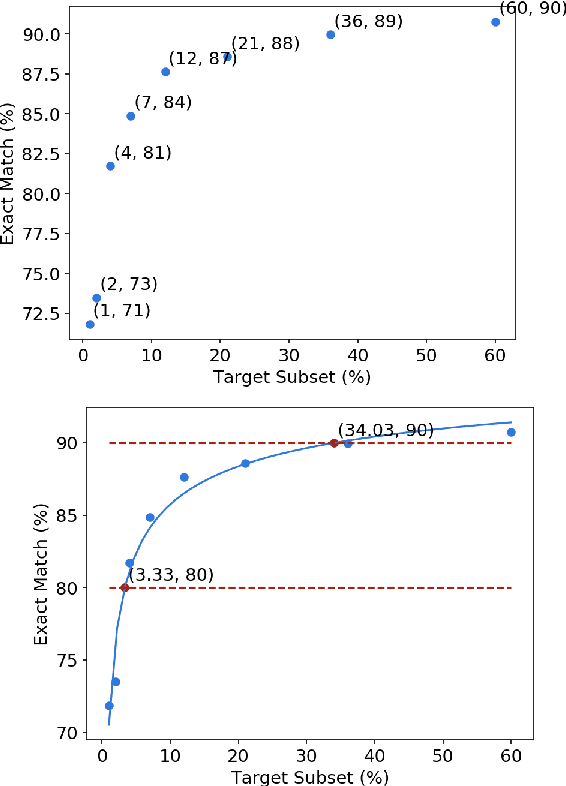
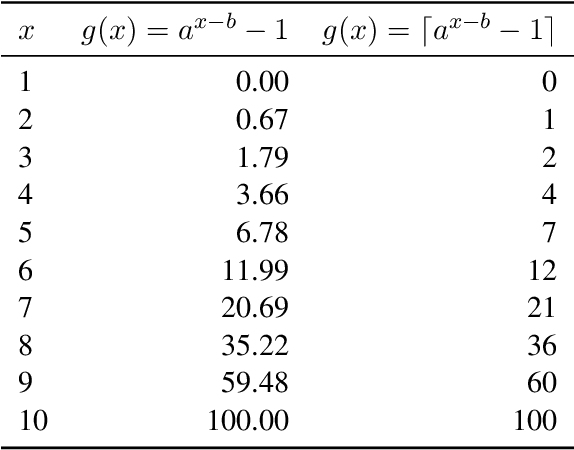
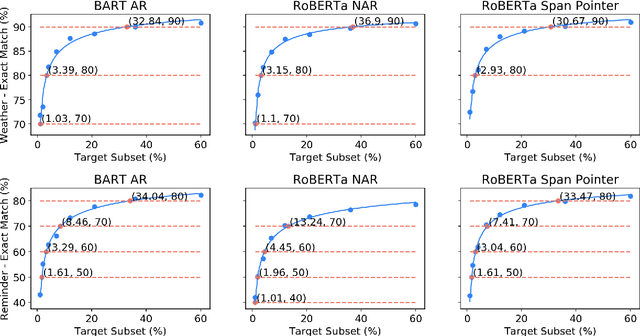

Data efficiency, despite being an attractive characteristic, is often challenging to measure and optimize for in task-oriented semantic parsing; unlike exact match, it can require both model- and domain-specific setups, which have, historically, varied widely across experiments. In our work, as a step towards providing a unified solution to data-efficiency-related questions, we introduce a four-stage protocol which gives an approximate measure of how much in-domain, "target" data a parser requires to achieve a certain quality bar. Specifically, our protocol consists of (1) sampling target subsets of different cardinalities, (2) fine-tuning parsers on each subset, (3) obtaining a smooth curve relating target subset (%) vs. exact match (%), and (4) referencing the curve to mine ad-hoc (target subset, exact match) points. We apply our protocol in two real-world case studies -- model generalizability and intent complexity -- illustrating its flexibility and applicability to practitioners in task-oriented semantic parsing.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021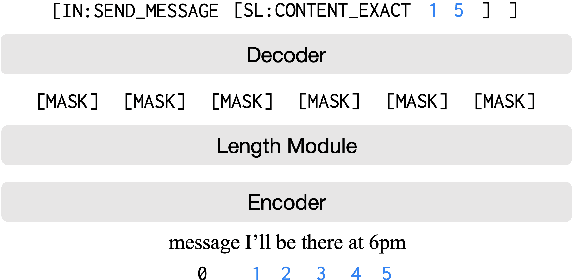

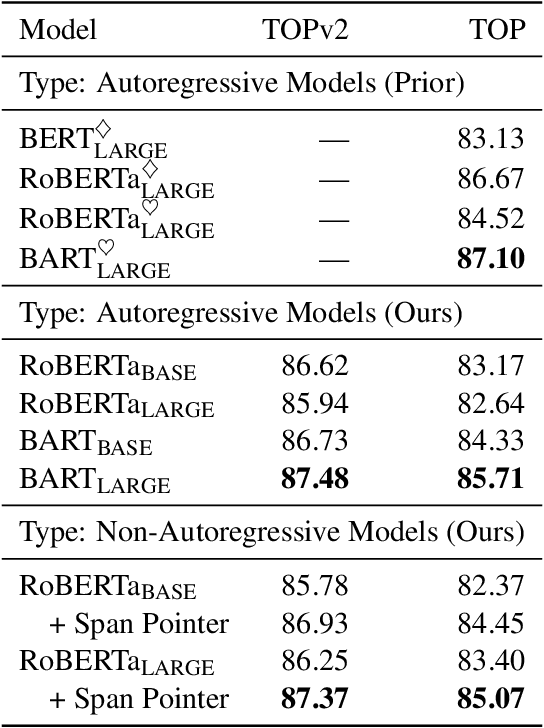
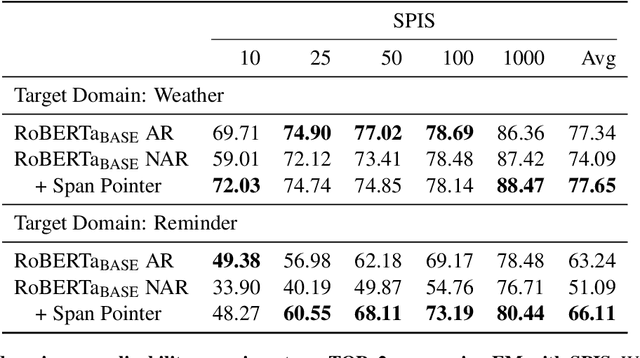
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.
Low-Resource Task-Oriented Semantic Parsing via Intrinsic Modeling
Apr 15, 2021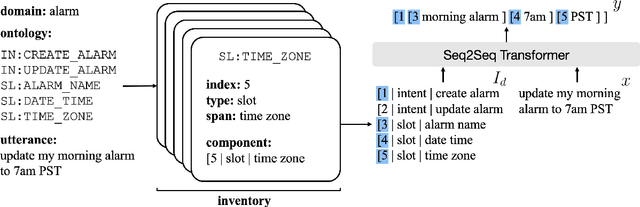
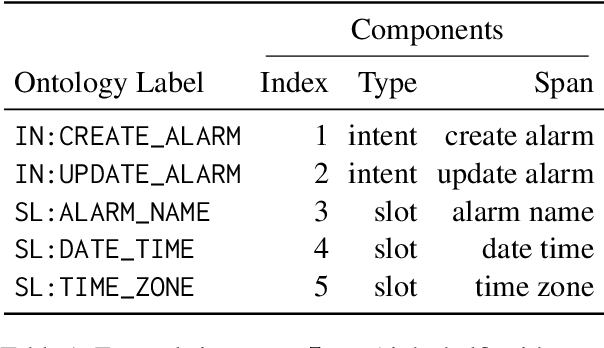
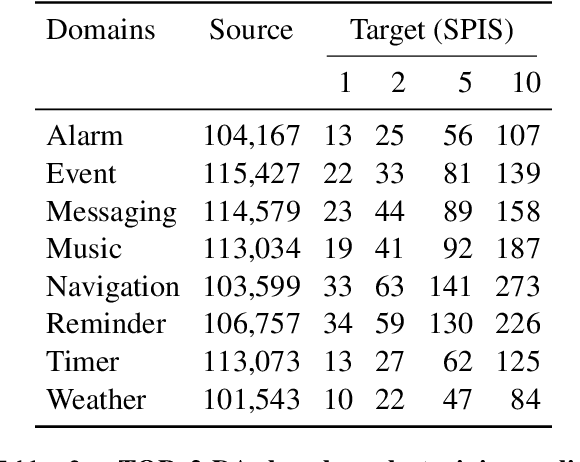
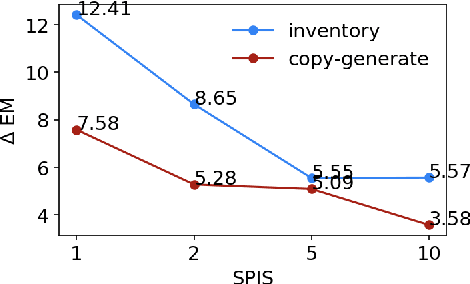
Task-oriented semantic parsing models typically have high resource requirements: to support new ontologies (i.e., intents and slots), practitioners crowdsource thousands of samples for supervised fine-tuning. Partly, this is due to the structure of de facto copy-generate parsers; these models treat ontology labels as discrete entities, relying on parallel data to extrinsically derive their meaning. In our work, we instead exploit what we intrinsically know about ontology labels; for example, the fact that SL:TIME_ZONE has the categorical type "slot" and language-based span "time zone". Using this motivation, we build our approach with offline and online stages. During preprocessing, for each ontology label, we extract its intrinsic properties into a component, and insert each component into an inventory as a cache of sorts. During training, we fine-tune a seq2seq, pre-trained transformer to map utterances and inventories to frames, parse trees comprised of utterance and ontology tokens. Our formulation encourages the model to consider ontology labels as a union of its intrinsic properties, therefore substantially bootstrapping learning in low-resource settings. Experiments show our model is highly sample efficient: using a low-resource benchmark derived from TOPv2, our inventory parser outperforms a copy-generate parser by +15 EM absolute (44% relative) when fine-tuning on 10 samples from an unseen domain.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.