 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
Assessing Data Efficiency in Task-Oriented Semantic Parsing
Jul 10, 2021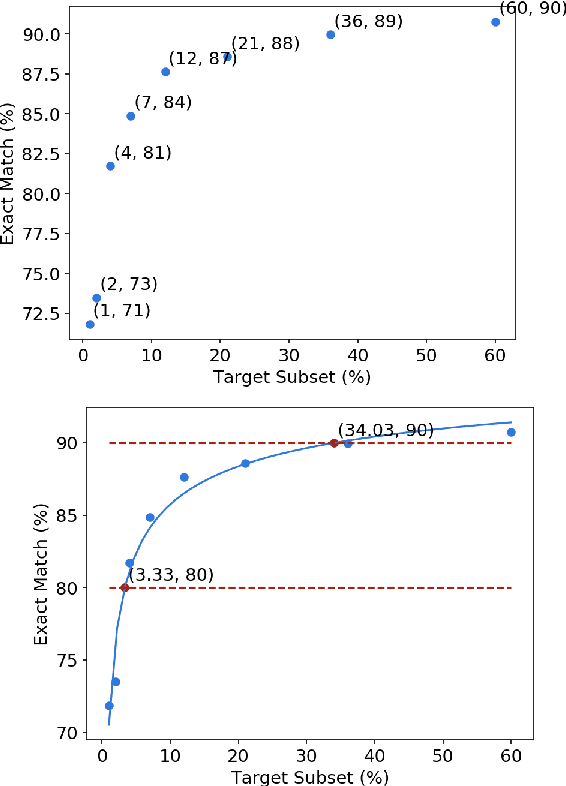
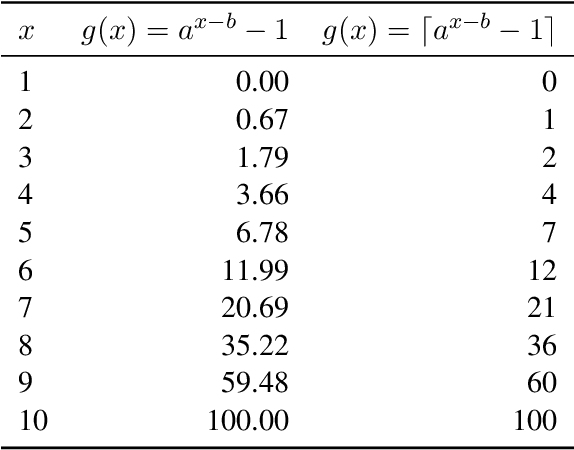
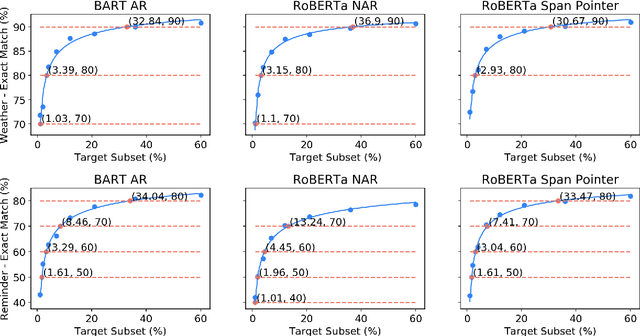

Data efficiency, despite being an attractive characteristic, is often challenging to measure and optimize for in task-oriented semantic parsing; unlike exact match, it can require both model- and domain-specific setups, which have, historically, varied widely across experiments. In our work, as a step towards providing a unified solution to data-efficiency-related questions, we introduce a four-stage protocol which gives an approximate measure of how much in-domain, "target" data a parser requires to achieve a certain quality bar. Specifically, our protocol consists of (1) sampling target subsets of different cardinalities, (2) fine-tuning parsers on each subset, (3) obtaining a smooth curve relating target subset (%) vs. exact match (%), and (4) referencing the curve to mine ad-hoc (target subset, exact match) points. We apply our protocol in two real-world case studies -- model generalizability and intent complexity -- illustrating its flexibility and applicability to practitioners in task-oriented semantic parsing.