 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve-and-Fill for Scenario-based Task-Oriented Semantic Parsing
Feb 02, 2022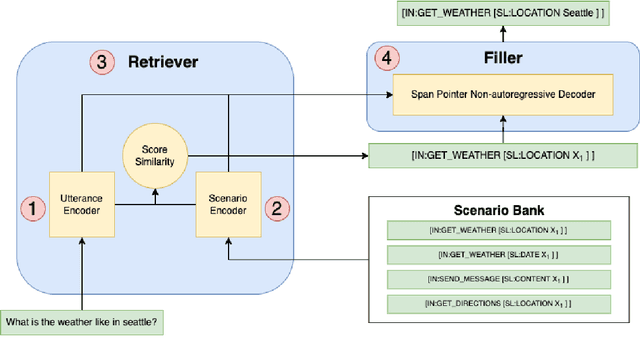


Task-oriented semantic parsing models have achieved strong results in recent years, but unfortunately do not strike an appealing balance between model size, runtime latency, and cross-domain generalizability. We tackle this problem by introducing scenario-based semantic parsing: a variant of the original task which first requires disambiguating an utterance's "scenario" (an intent-slot template with variable leaf spans) before generating its frame, complete with ontology and utterance tokens. This formulation enables us to isolate coarse-grained and fine-grained aspects of the task, each of which we solve with off-the-shelf neural modules, also optimizing for the axes outlined above. Concretely, we create a Retrieve-and-Fill (RAF) architecture comprised of (1) a retrieval module which ranks the best scenario given an utterance and (2) a filling module which imputes spans into the scenario to create the frame. Our model is modular, differentiable, interpretable, and allows us to garner extra supervision from scenarios. RAF achieves strong results in high-resource, low-resource, and multilingual settings, outperforming recent approaches by wide margins despite, using base pre-trained encoders, small sequence lengths, and parallel decoding.
Assessing Data Efficiency in Task-Oriented Semantic Parsing
Jul 10, 2021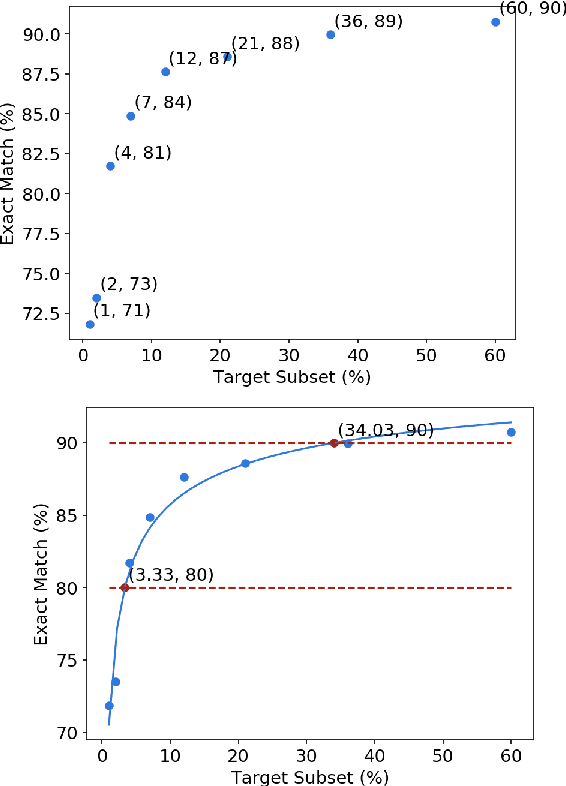
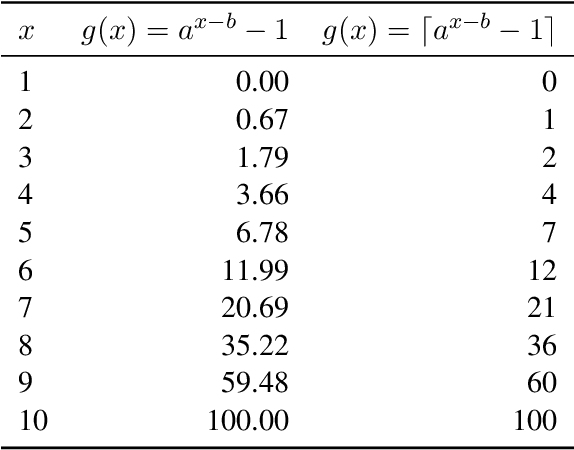
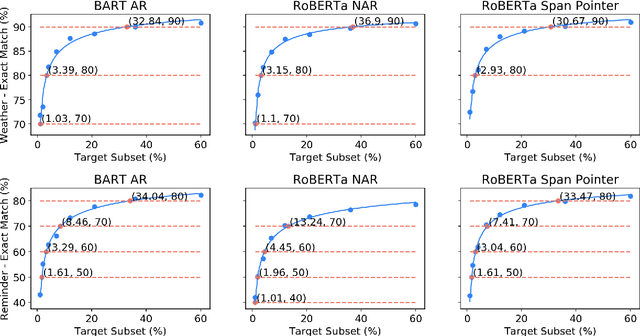

Data efficiency, despite being an attractive characteristic, is often challenging to measure and optimize for in task-oriented semantic parsing; unlike exact match, it can require both model- and domain-specific setups, which have, historically, varied widely across experiments. In our work, as a step towards providing a unified solution to data-efficiency-related questions, we introduce a four-stage protocol which gives an approximate measure of how much in-domain, "target" data a parser requires to achieve a certain quality bar. Specifically, our protocol consists of (1) sampling target subsets of different cardinalities, (2) fine-tuning parsers on each subset, (3) obtaining a smooth curve relating target subset (%) vs. exact match (%), and (4) referencing the curve to mine ad-hoc (target subset, exact match) points. We apply our protocol in two real-world case studies -- model generalizability and intent complexity -- illustrating its flexibility and applicability to practitioners in task-oriented semantic parsing.
Diagnosing Transformers in Task-Oriented Semantic Parsing
May 27, 2021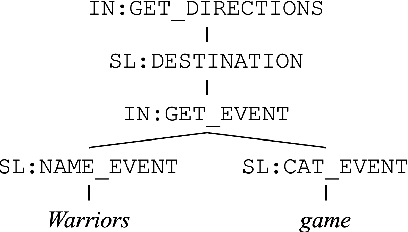
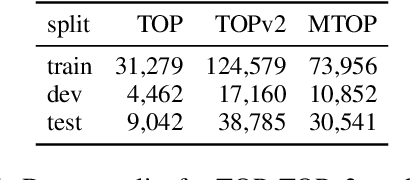

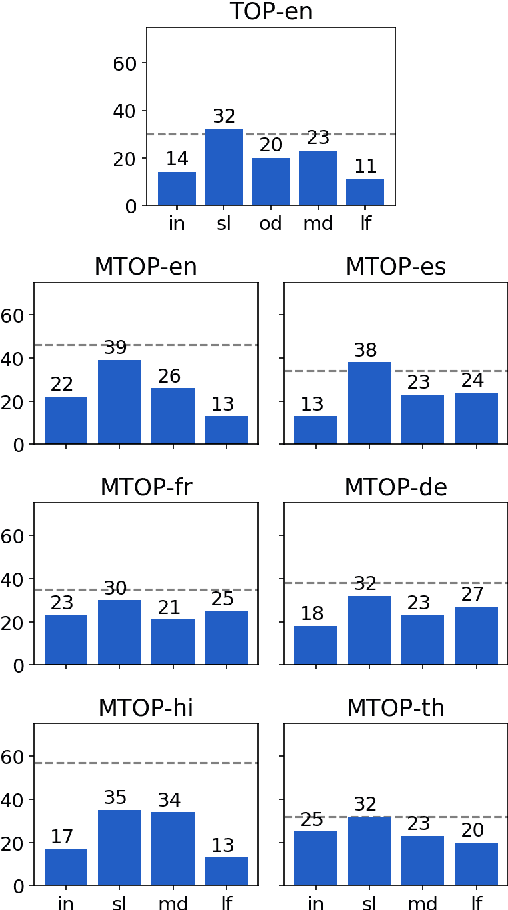
Modern task-oriented semantic parsing approaches typically use seq2seq transformers to map textual utterances to semantic frames comprised of intents and slots. While these models are empirically strong, their specific strengths and weaknesses have largely remained unexplored. In this work, we study BART and XLM-R, two state-of-the-art parsers, across both monolingual and multilingual settings. Our experiments yield several key results: transformer-based parsers struggle not only with disambiguating intents/slots, but surprisingly also with producing syntactically-valid frames. Though pre-training imbues transformers with syntactic inductive biases, we find the ambiguity of copying utterance spans into frames often leads to tree invalidity, indicating span extraction is a major bottleneck for current parsers. However, as a silver lining, we show transformer-based parsers give sufficient indicators for whether a frame is likely to be correct or incorrect, making them easier to deploy in production settings.
Span Pointer Networks for Non-Autoregressive Task-Oriented Semantic Parsing
Apr 16, 2021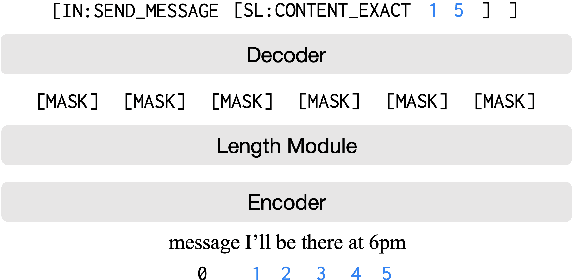

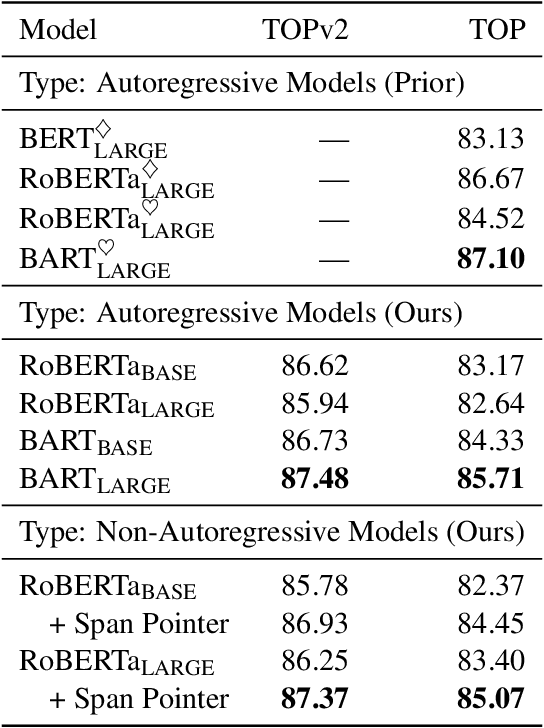
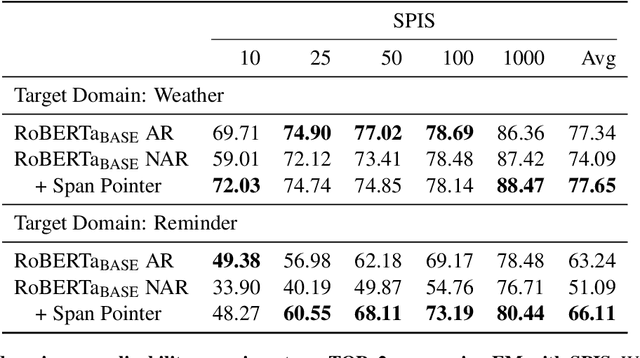
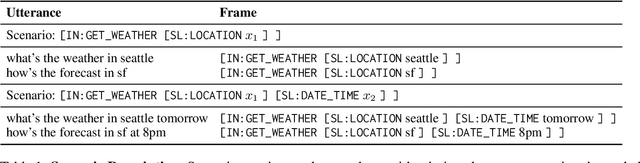
An effective recipe for building seq2seq, non-autoregressive, task-oriented parsers to map utterances to semantic frames proceeds in three steps: encoding an utterance $x$, predicting a frame's length |y|, and decoding a |y|-sized frame with utterance and ontology tokens. Though empirically strong, these models are typically bottlenecked by length prediction, as even small inaccuracies change the syntactic and semantic characteristics of resulting frames. In our work, we propose span pointer networks, non-autoregressive parsers which shift the decoding task from text generation to span prediction; that is, when imputing utterance spans into frame slots, our model produces endpoints (e.g., [i, j]) as opposed to text (e.g., "6pm"). This natural quantization of the output space reduces the variability of gold frames, therefore improving length prediction and, ultimately, exact match. Furthermore, length prediction is now responsible for frame syntax and the decoder is responsible for frame semantics, resulting in a coarse-to-fine model. We evaluate our approach on several task-oriented semantic parsing datasets. Notably, we bridge the quality gap between non-autogressive and autoregressive parsers, achieving 87 EM on TOPv2 (Chen et al. 2020). Furthermore, due to our more consistent gold frames, we show strong improvements in model generalization in both cross-domain and cross-lingual transfer in low-resource settings. Finally, due to our diminished output vocabulary, we observe 70% reduction in latency and 83% reduction in memory at beam size 5 compared to prior non-autoregressive parsers.
Low-Resource Task-Oriented Semantic Parsing via Intrinsic Modeling
Apr 15, 2021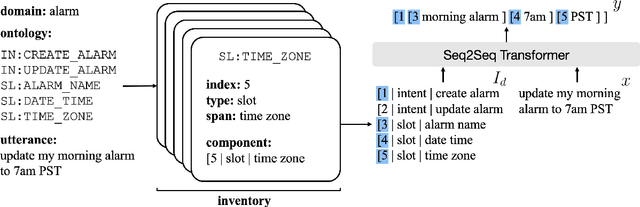
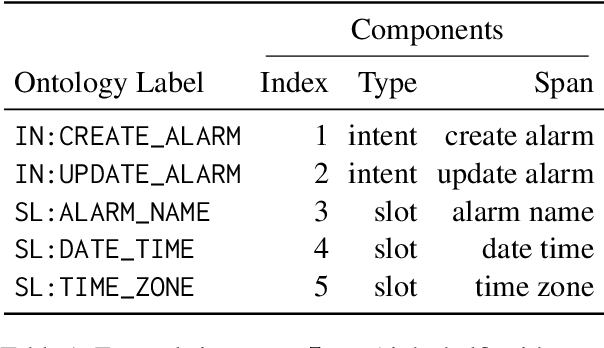
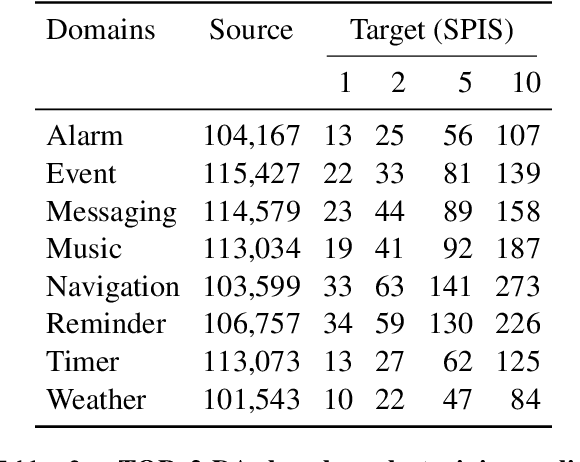
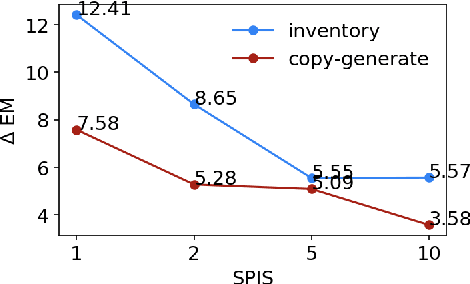
Task-oriented semantic parsing models typically have high resource requirements: to support new ontologies (i.e., intents and slots), practitioners crowdsource thousands of samples for supervised fine-tuning. Partly, this is due to the structure of de facto copy-generate parsers; these models treat ontology labels as discrete entities, relying on parallel data to extrinsically derive their meaning. In our work, we instead exploit what we intrinsically know about ontology labels; for example, the fact that SL:TIME_ZONE has the categorical type "slot" and language-based span "time zone". Using this motivation, we build our approach with offline and online stages. During preprocessing, for each ontology label, we extract its intrinsic properties into a component, and insert each component into an inventory as a cache of sorts. During training, we fine-tune a seq2seq, pre-trained transformer to map utterances and inventories to frames, parse trees comprised of utterance and ontology tokens. Our formulation encourages the model to consider ontology labels as a union of its intrinsic properties, therefore substantially bootstrapping learning in low-resource settings. Experiments show our model is highly sample efficient: using a low-resource benchmark derived from TOPv2, our inventory parser outperforms a copy-generate parser by +15 EM absolute (44% relative) when fine-tuning on 10 samples from an unseen domain.
Compressive Summarization with Plausibility and Salience Modeling
Oct 15, 2020
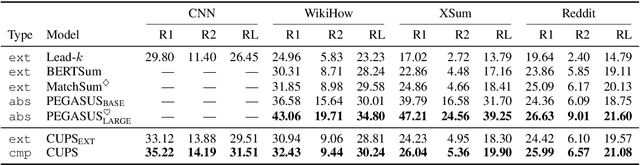
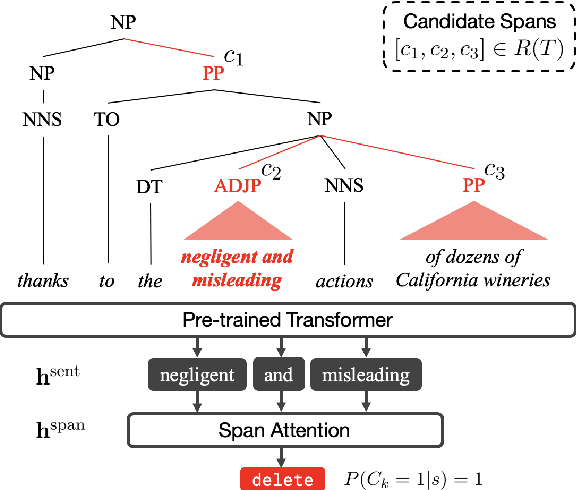
Compressive summarization systems typically rely on a crafted set of syntactic rules to determine what spans of possible summary sentences can be deleted, then learn a model of what to actually delete by optimizing for content selection (ROUGE). In this work, we propose to relax the rigid syntactic constraints on candidate spans and instead leave compression decisions to two data-driven criteria: plausibility and salience. Deleting a span is plausible if removing it maintains the grammaticality and factuality of a sentence, and spans are salient if they contain important information from the summary. Each of these is judged by a pre-trained Transformer model, and only deletions that are both plausible and not salient can be applied. When integrated into a simple extraction-compression pipeline, our method achieves strong in-domain results on benchmark summarization datasets, and human evaluation shows that the plausibility model generally selects for grammatical and factual deletions. Furthermore, the flexibility of our approach allows it to generalize cross-domain: our system fine-tuned on only 500 samples from a new domain can match or exceed an in-domain extractive model trained on much more data.
Understanding Neural Abstractive Summarization Models via Uncertainty
Oct 15, 2020

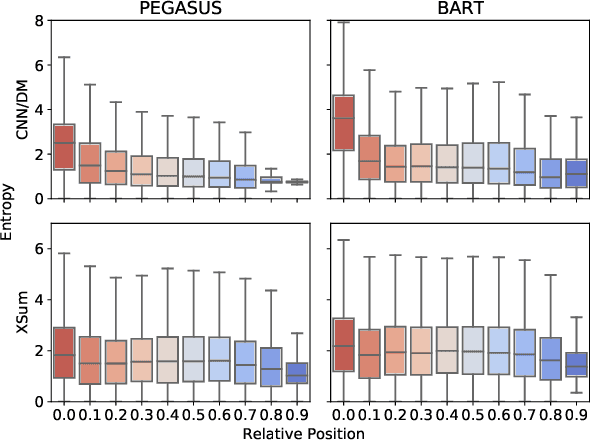
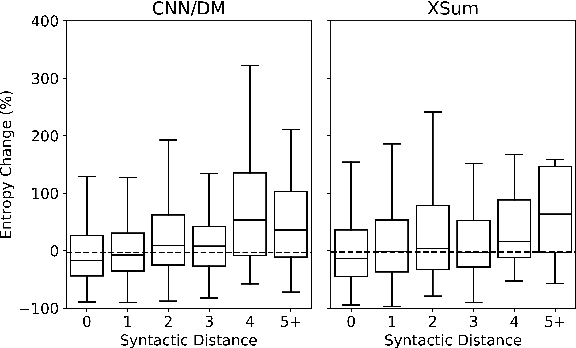
An advantage of seq2seq abstractive summarization models is that they generate text in a free-form manner, but this flexibility makes it difficult to interpret model behavior. In this work, we analyze summarization decoders in both blackbox and whitebox ways by studying on the entropy, or uncertainty, of the model's token-level predictions. For two strong pre-trained models, PEGASUS and BART on two summarization datasets, we find a strong correlation between low prediction entropy and where the model copies tokens rather than generating novel text. The decoder's uncertainty also connects to factors like sentence position and syntactic distance between adjacent pairs of tokens, giving a sense of what factors make a context particularly selective for the model's next output token. Finally, we study the relationship of decoder uncertainty and attention behavior to understand how attention gives rise to these observed effects in the model. We show that uncertainty is a useful perspective for analyzing summarization and text generation models more broadly.
Accelerating Natural Language Understanding in Task-Oriented Dialog
Jun 05, 2020
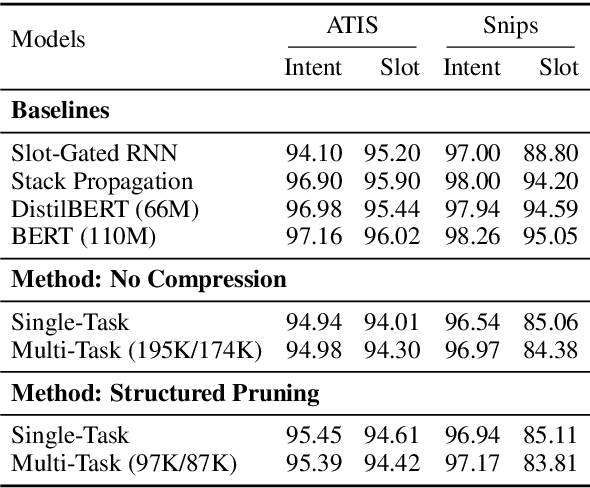
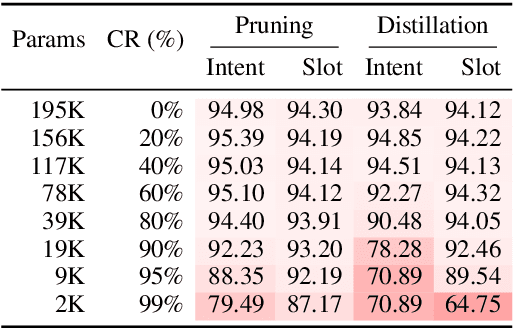
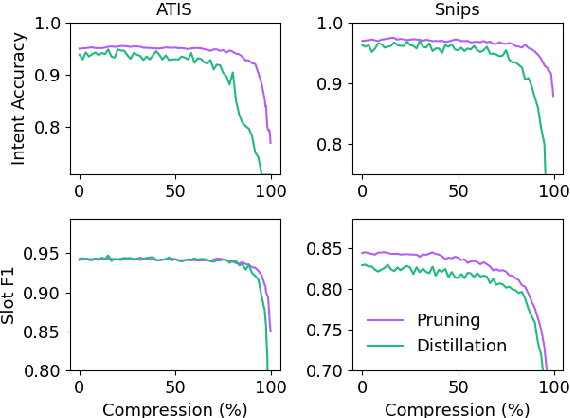
Task-oriented dialog models typically leverage complex neural architectures and large-scale, pre-trained Transformers to achieve state-of-the-art performance on popular natural language understanding benchmarks. However, these models frequently have in excess of tens of millions of parameters, making them impossible to deploy on-device where resource-efficiency is a major concern. In this work, we show that a simple convolutional model compressed with structured pruning achieves largely comparable results to BERT on ATIS and Snips, with under 100K parameters. Moreover, we perform acceleration experiments on CPUs, where we observe our multi-task model predicts intents and slots nearly 63x faster than even DistilBERT.
Detecting Perceived Emotions in Hurricane Disasters
Apr 29, 2020
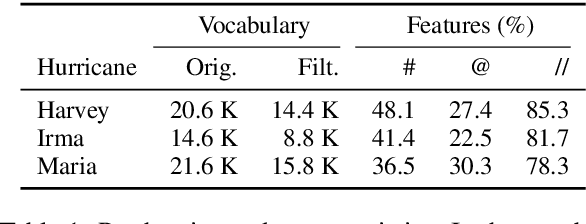

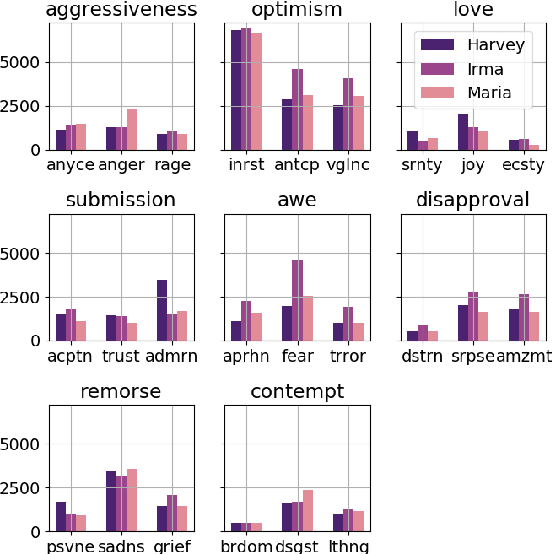
Natural disasters (e.g., hurricanes) affect millions of people each year, causing widespread destruction in their wake. People have recently taken to social media websites (e.g., Twitter) to share their sentiments and feelings with the larger community. Consequently, these platforms have become instrumental in understanding and perceiving emotions at scale. In this paper, we introduce HurricaneEmo, an emotion dataset of 15,000 English tweets spanning three hurricanes: Harvey, Irma, and Maria. We present a comprehensive study of fine-grained emotions and propose classification tasks to discriminate between coarse-grained emotion groups. Our best BERT model, even after task-guided pre-training which leverages unlabeled Twitter data, achieves only 68% accuracy (averaged across all groups). HurricaneEmo serves not only as a challenging benchmark for models but also as a valuable resource for analyzing emotions in disaster-centric domains.
Calibration of Pre-trained Transformers
Mar 20, 2020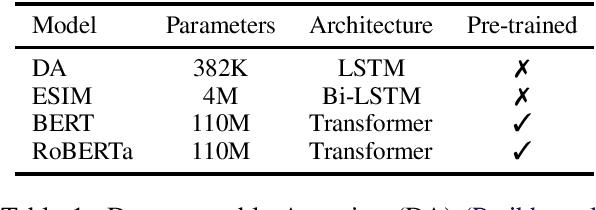
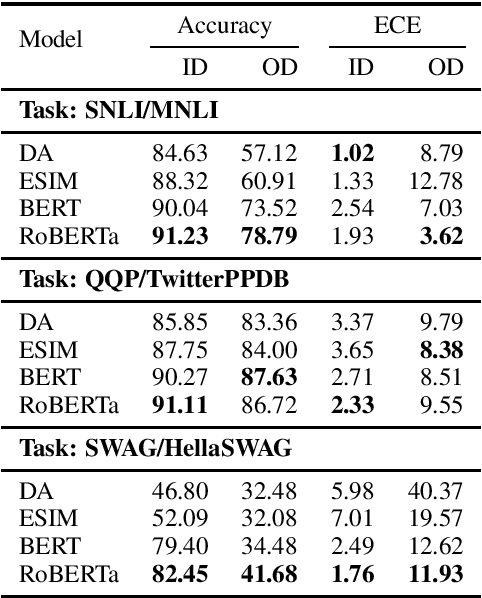
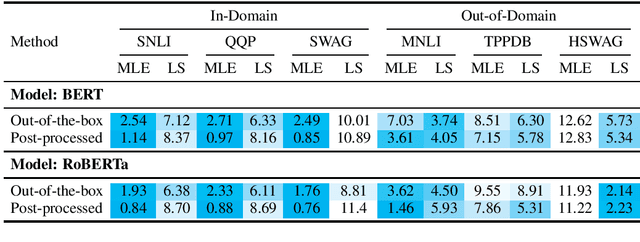

Pre-trained Transformers are now ubiquitous in natural language processing, but despite their high end-task performance, little is known empirically about whether they are calibrated. Specifically, do these models' posterior probabilities provide an accurate empirical measure of how likely the model is to be correct on a given example? We focus on BERT and RoBERTa in this work, and analyze their calibration across three tasks: natural language inference, paraphrase detection, and commonsense reasoning. For each task, we consider in-domain as well as challenging out-of-domain settings, where models face more examples they should be uncertain about. We show that: (1) when used out-of-the-box, pre-trained models are calibrated in-domain, and compared to baselines, their calibration error out-of-domain can be as much as 3.5x lower; (2) temperature scaling is effective at further reducing calibration error in-domain, and using label smoothing to deliberately increase empirical uncertainty helps calibrate posteriors out-of-domain.